In this project, the scaling approach involves deploying an agent per pod, which is a vertical scaling strategy. This method is particularly well-suited for stateful applications. The system is highly scalable because we can add an agent for every pod, and the interval of scaling can be as low as 1 second, allowing for rapid adjustments to resource demands.
🎥 MARLISE Autoscaling Overview
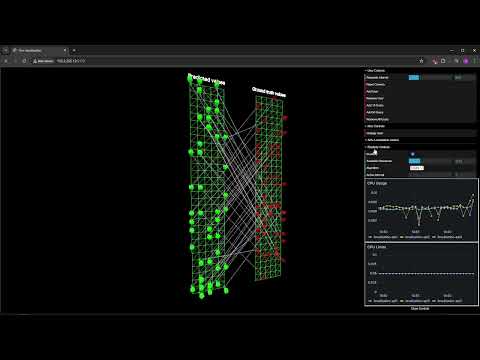
🎯 MARLISE Application Autoscaling Demo
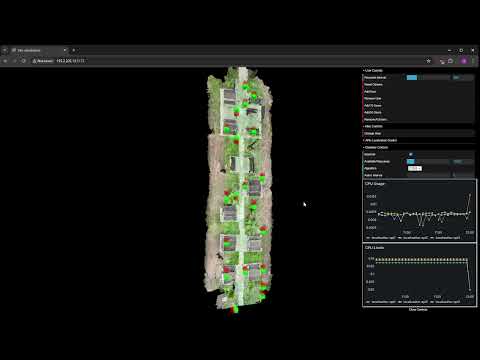
Scripts are meant to run from the project root folder.
- Usage of InPlacePodVerticalScaling feature gate is required for agent functionalities to ensure seamless scaling.
Example:
kubectl patch pod localization-api1 --patch '{"spec":{"containers":[{"name":"localization-api", "resources":{"requests":{"cpu":"500m"}, "limits":{"cpu":"500m"}}}]}}'
- Ensure all Python dependencies are installed. You can use a
requirements.txtfile or a similar method to install dependencies.
- This project has been tested on k3s and microk8s.
To install the microk8s container orchestration platform, run the following script on every node:
sudo bash scripts/microk8s/setup.shAfter running the script, join the nodes using:
microk8s add-nodeDeploy the necessary configurations and the use-case service of localization:
sudo bash scripts/microk8s/deploy_all.shMore info in demo readme.
To run the inference script, use the following command:
python src/infer.pyusage: infer.py [-h] [--n_agents N_AGENTS] [--resources RESOURCES] [--load_model LOAD_MODEL] [--action_interval ACTION_INTERVAL] [--priorities PRIORITIES [PRIORITIES ...]] [--algorithm ALGORITHM] [--hack HACK] [--debug]
options:
-h, --help show this help message and exit
--n_agents N_AGENTS
--resources RESOURCES
--load_model LOAD_MODEL
--action_interval ACTION_INTERVAL
--priorities PRIORITIES [PRIORITIES ...]
List of priorities (0.0 < value <= 1.0), default is 1.0 for all agents. Example: 1.0 1.0 1.0
--algorithm ALGORITHM
Algorithm to use: ppo, ippo (instant ppo), dppo (discrete ppo), ddpg, iddpg (instant ddpg), mdqn, dmdqn, ddmdqn
--hack HACK Transfer learning agent, so every agent will be loaded from this agent's saved weights
--debug
Three multi-agent deep reinforcement learning algorithms are supported:
- DQN: Actions are {increase, maintain, decrease}
- PPO: Outputs a continuous number [-1, 1], scaled and applied. Can also use discrete actions.
- DDPG: Similar to PPO, outputs a continuous number.
Avaialbe as a Docker image or run locally, refer to other readme.
The Backend handles the elasticity by itself, but offers API intreface for control and information about the system.
| Endpoint | Method | Description | Request Body | Response |
|---|---|---|---|---|
/start |
POST | Starts the inference process | None | { "message": "Inference started" } |
/stop |
POST | Stops the inference process | None | { "message": "Inference stopped" } |
/set_resources |
POST | Sets the maximum CPU resources | { "resources": int } |
{ "message": "Resources set to {resources}" } |
/set_interval |
POST | Sets the interval between actions | { "interval": int } |
{ "message": "Interval set to {interval}" } |
/set_dqn_algorithm |
POST | Sets the algorithm to DQN | None | { "message": "DQN algorithm set" } |
/set_ppo_algorithm |
POST | Sets the algorithm to PPO | None | { "message": "PPO algorithm set" } |
/set_ddpg_algorithm |
POST | Sets the algorithm to DDPG | None | { "message": "DDPG algorithm set" } |
/set_default_limits |
POST | Sets the default CPU limits | None | { "message": "Default limits set" } |
/status |
GET | Gets the status of the inference process | None | { "status": bool } |
/algorithm |
GET | Gets the current algorithm being used | None | { "algorithm": "ppo" OR "dqn" OR "ddpg" } |
/resources |
GET | Gets the current maximum CPU resources | None | { "resources": int } |
/interval |
GET | Gets the current action interval | None | { "interval": int } |
For the frontend that is connected to the above aforementioned Backend, refer to the following repository.
Please cite our paper as follows:
@article{Prodanov2025,
title = {Multi-agent Reinforcement Learning-based In-place Scaling Engine for Edge-cloud Systems},
journal = {IEEE Cloud},
year = {2025},
doi = {https://doi.org/10.48550/arXiv.2507.07671},
url = {[https://arxiv.org/abs/2507.07671v1]},
author = {Jovan Prodanov and Blaž Bertalanič and Carolina Fortuna and Shih-Kai Chou and Matjaž Branko Jurič and Ramon Sanchez-Iborra and Jernej Hribar}
}
This work was funded in part by the Slovenian Research Agency (grants P2-0016 and MN-0009-106), by grant PID2023-148104OB-C43 funded by MICIU/AEI/10.13039/501100011033 and co-funded by ERDF/EU, by the European Commission NANCY project (No. 101096456), and by the HORIZON-MSCA-PF project TimeSmart (No. 101063721).
- Ensure all containers are running the same Python version.
- In Kubernetes, it is recommended to disable swap with
sudo swapoff -aon all nodes to maximize resource utilization. All deployments should have CPU and memory limits set.