Conversation
Testing scenarios needed before merging
|
Future work: placement preferencesMetaInstance currently places with no optimization preference. A natural next step is letting users specify a placement preference, e.g.:
These are different points on a throughput vs. interactivity Pareto curve. The placer would use the preference to score candidate placements differently rather than just picking the first valid one. |
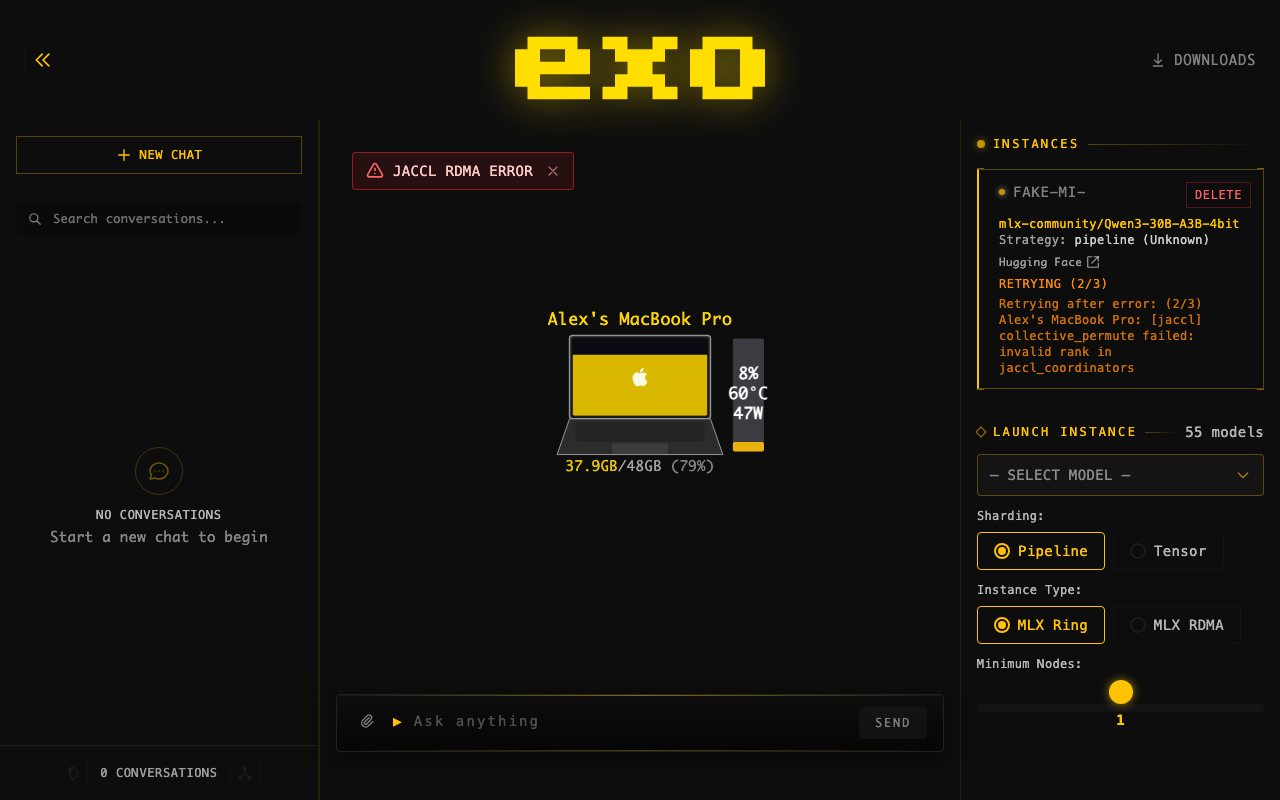
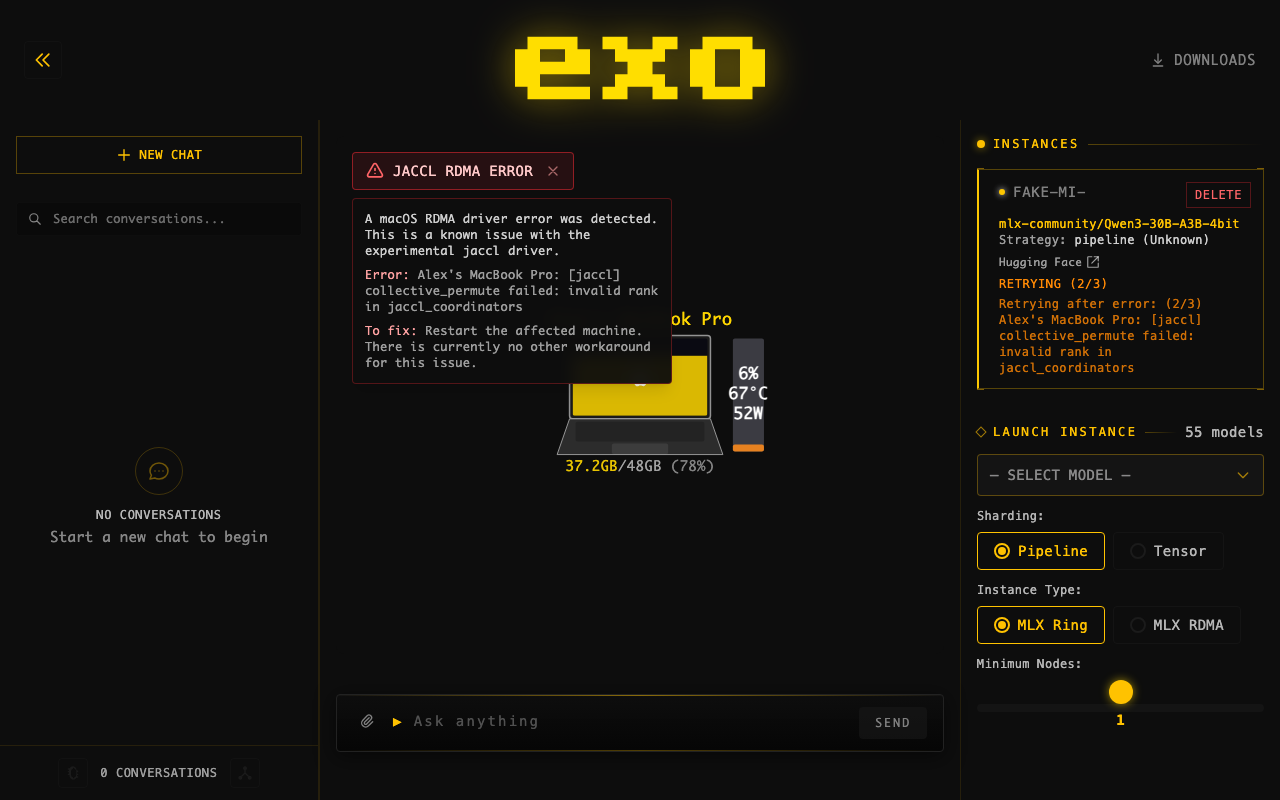
JACCL RDMA Error Warning BannerAdded a dashboard warning that detects What it does:
Banner: Tooltip on hover: |
Deep Review of PR 1447: MetaInstance LayerReviewed: all 32 commits, ~2459 additions / ~228 deletions across 25+ files SummaryThe PR adds a MetaInstance declarative constraint layer that ensures a model instance matching given parameters always exists. When the backing instance fails, the system automatically retries placement up to Recommendation: Merge (with minor suggestions below)Architecture is clean — pure reconciliation functions in Issues Found1. Race condition in
|
| Category | Tests |
|---|---|
| Lifecycle | create/delete roundtrip, frozen model, deletion removes from state |
| Retry logic | counter increments through cycle, max retries → deletion, resets on success |
| Error handling | retrying for missing instance, placement failure records error, double-delete idempotent |
| Backward compat | instances without meta_instance_id, legacy placement, state serialization |
| Concurrent | multiple meta-instances for same model, deleting one doesn't affect others |
| Constraints | node_ids subset matching, min_nodes enforcement, binding vs constraint semantics |
🤖 Generated with Claude Code
Full Summary of PR #1447 — Add MetaInstance Declarative LayerDiff: 31 files changed, +3,241 / -238 lines What is MetaInstance?A declarative primitive: "ensure an instance matching these parameters always exists." If a node disconnects or connections break, the reconciler automatically re-creates the backing instance. Previously, users managed instances directly and dead instances stayed dead. Core Changes (Python — 20 files)New types and models:
Events and commands:
Event sourcing:
Reconciliation:
Master and worker:
Other:
Dashboard Changes (Svelte — 4 files)
Tests (3 files, ~28 new tests)
Design Decisions
Merge Conflict ResolutionThe merge with
|
Latest improvements (commit 3df896d)Bug fix: cancel active tasks on meta-instance cascade delete
Files: Lifecycle loggingAdded structured logging for meta-instance operations to aid debugging:
GET
|
 AlexCheema
left a comment
AlexCheema
left a comment
There was a problem hiding this comment.
Code Review: PR #1447 — MetaInstance Declarative Layer
Overall Assessment
Well-architected addition that introduces a declarative MetaInstance abstraction over the existing imperative instance management. The reconciliation pattern is clean, the retry logic is sound, and the test coverage is thorough (778 lines of edge-case tests). This is a significant architectural improvement.
Strengths
-
ProcessManager Protocol (
process_managers/__init__.py): Clean, composable interface.@runtime_checkableis a nice touch for validation. The three reconcilers (InstanceHealth, NodeTimeout, MetaInstance) have clear single responsibilities. -
_apply_and_broadcasteliminates the loopback processor hack. Centralizing event indexing, state mutation, persistence, and broadcast in one method is a major improvement. The docstring correctly notes Python's cooperative scheduling guarantees. -
instance_runners_failed(reconcile.py): The logic is exactly right — requires ALL runners to be terminal AND at least oneRunnerFailed. Correctly returns(False, None)when runners haven't reported yet (still starting) or when all are gracefully shut down. The node-identity-aware error messages are a nice UX touch. -
find_unsatisfied_meta_instancescorrectly checks bothmeta_instance_idbinding ANDinstance_connections_healthy, not just one or the other. A MetaInstance with a backing instance that has a broken connection will be detected. -
Cascade delete (
_command_processor, DeleteMetaInstance case): Correctly cancels active tasks before deleting the backing instance. TheTaskStatus.Cancelledevents are emitted beforeInstanceDeleted, ensuring proper cleanup ordering. -
Comprehensive edge-case tests (
test_meta_instance_edge_cases.py): Tests cover frozen model validation, create/delete roundtrips, nonexistent-ID safety, duplicate MetaInstances, retry counter resets, full retry cycles, and more.
Issues
-
try_place_for_meta_instancedoesn't intersectnode_idswith live topology (reconcile.py~line 227): If a meta-instance pinsnode_ids=["node-a", "node-b"]andnode-bgoes down, placement will fail becausenode-bisn't in the topology. The placement could be made more resilient by intersectingmeta_instance.node_idswithtopology.list_nodes()and only requiring alive nodes. (Note: the other branch — #1484 — appears to have this fix withalive = set(meta_instance.node_ids) & live_nodes.) -
Reconcile loop at 1-second interval (
master/main.py): The previous_planloop ran every 10 seconds. Now_reconcileruns every 1 second, andMetaInstanceReconcilercallsModelCard.load()for every unsatisfied meta-instance on each cycle. If model card loading hits the network (HuggingFace API), this could generate excessive requests when placement persistently fails. Consider:- Caching
ModelCard.load()results - Adding a timeout to
ModelCard.load()(prevent one slow model lookup from blocking the entire reconcile loop) - Exponential backoff for meta-instances with
placement_errorset
- Caching
-
Placement strategy change (
placement.py,placement_utils.py):get_smallest_cycles→get_largest_cycleschanges the default from "minimize nodes used" to "maximize nodes used". This is a significant behavior change — users who previously got 2-node placements will now get 4-node placements. Should be documented and justified (performance? memory pressure?). -
_reconcilemanager ordering matters (master/main.py): Managers run sequentially with state updated between each.InstanceHealthReconcilerruns beforeMetaInstanceReconciler, which is correct (delete broken instances before trying to re-place). But this ordering dependency is implicit. Consider adding a comment. -
Potential double-place race in
CreateMetaInstancehandler (master/main.py): The command handler does an immediate placement attempt after_apply_and_broadcast(MetaInstanceCreated). It re-checksfind_unsatisfied_meta_instancesto avoid racing with the reconciler, which is good. However, between theawait ModelCard.load()and the re-check, the reconciler could also be placing — the re-check mitigates but doesn't fully eliminate the race since the reconciler could be mid-placement (afterfind_unsatisfiedbut before emittingInstanceCreated).
Minor
-
PlacementResultasNamedTuple(reconcile.py): Rest of the codebase uses frozen Pydantic models or dataclasses. Minor inconsistency. -
Magic number:
MAX_INSTANCE_RETRIES = 3ininstance_health.py— consider making this configurable or at least documenting why 3.
Verdict
Strong architectural improvement. The declarative layer, reconciliation pattern, and retry logic are well-designed. The main concerns are the placement strategy change (largest vs smallest), the 1-second reconcile interval with potentially slow ModelCard.load(), and the node_ids/topology intersection issue. Would approve after addressing #7 (topology intersection) and #9 (placement strategy documentation).
🤖 Generated with Claude Code
3df896d to
34e846b
Compare
Introduces MetaInstance as a declarative constraint ensuring an instance matching given parameters (model, sharding, min_nodes) always exists. The master's reconciliation loop continuously checks for unsatisfied meta-instances and attempts placement. Connection health checking verifies that specific IPs (MlxRing) and RDMA interfaces (MlxJaccl) stored on instances still exist as topology edges, enabling automatic recovery when cables are swapped or interfaces change. Also eliminates the master's loopback event path, unifying all event emission through _apply_and_broadcast for simpler control flow. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
- Add MetaInstanceBound event and meta_instance_backing State field for explicit MetaInstance → Instance binding (prevents ambiguous linking when two MetaInstances have identical constraints) - Replace model_card: ModelCard with model_id: ModelId on MetaInstance (load ModelCard on-demand at placement time) - Add MetaInstance API endpoints (POST /meta_instance, DELETE) - Update dashboard to use MetaInstances as primary primitive with unified display items merging MetaInstances and orphan instances - Dashboard launches via MetaInstance instead of direct Instance creation Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
The separate MetaInstanceBound event + meta_instance_backing map introduced two bugs: stale exclusion sets in the reconciler loop and a delete ordering race. Embedding meta_instance_id directly on BaseInstance eliminates the binding mechanism entirely — when an instance is created for a MetaInstance it carries the ID, when deleted the binding is gone. No separate map, no cleanup, no races. Also fixes delete_meta_instance to cascade-delete backing instances. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Replace inline _plan() steps with a list of ProcessManagers, each implementing async reconcile(State) -> Sequence[Event]. Tick every 1s instead of 10s — safe because all PMs are idempotent against state. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
- Replace inline _plan() with ProcessManager loop (_reconcile), tick every 1s instead of 10s — safe because all PMs are idempotent - Fix dashboard sending "MlxIbv" instead of "MlxJaccl" for RDMA instance type, which silently fell back to MlxRing default - Remove all stale MlxIbv references from dashboard Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
When a MetaInstance has no backing instance yet, derive the strategy display from the MetaInstance's own sharding and instanceMeta fields rather than showing "Unknown (Unknown)". Also clean up all stale MlxIbv references across the dashboard — the backend enum is MlxJaccl. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Show why MetaInstance placement fails instead of stuck "PLACING", and show per-node runner status during loading for multi-node instances. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
The mode="plain" validator bypassed Pydantic's string-to-enum coercion, so JSON strings like "Tensor" and "MlxJaccl" from the dashboard failed the isinstance check and silently fell back to Pipeline/MlxRing defaults. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Dashboard was not including the user's node filter in the POST to /meta_instance, so placement ignored which nodes the user selected. Also, placement silently fell back to Ring when RDMA was requested but no RDMA-connected cycles were available — now raises an error that surfaces via MetaInstancePlacementFailed. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
When user selects specific nodes via the filter, min_nodes should be at least the number of filtered nodes to prevent placement from picking a smaller cycle. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
RDMA requires at least 2 nodes — a single-node RDMA instance is nonsensical. Enforce this in both the dashboard (when building the launch request) and the backend placement (when filtering cycles). Previously, selecting RDMA would still place on 1 node because min_nodes defaulted to 1 and the placement silently switched to Ring. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
The dashboard now extracts node IDs from the selected preview's memory_delta_by_node, ensuring the backend places on exactly the nodes the user was shown. Also reverts incorrect RDMA min_nodes >= 2 enforcement since single-node RDMA is valid. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
frozenset serializes to a JSON array but cannot be deserialized back in strict mode through the TaggedModel wrap validator (list → frozenset coercion is rejected). Changed to list[NodeId] since the model is already frozen/immutable. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
- Extend InstanceDeleted with failure_error field for runner crash info - Add InstanceFailureInfo model tracking consecutive failures per MetaInstance - InstanceHealthReconciler now detects runner failures (all terminal with at least one RunnerFailed) in addition to connection failures - apply_instance_deleted increments failure counter for meta-bound instances - Dashboard shows RETRYING (N/3) status with error messages, and "Instance re-created due to failure" after 3 consecutive failures - Extract and display RunnerFailed error messages in instance status Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
…ashboard MetaInstanceReconciler now checks failure count before placement — after 3 consecutive failures it emits MetaInstancePlacementFailed instead of retrying forever. Dashboard shows "Retrying after error: <msg>" in orange throughout the retry cycle, not just during the brief window with no backing instance. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
When multiple runners fail, concatenate all error messages with "; " so the real error isn't hidden by generic side-effect failures from other runners. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
The dashboard % 3 logic already handles displaying retry progress in batches (RETRYING 1/3, 2/3, 3/3, then PLACING with error, repeat). No need to permanently block placement after 3 failures. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Each error in the combined message is now prefixed with the node's friendly name (e.g. "MacBook Pro: OOM; Mac Studio: connection reset") so the root cause node is easily identifiable. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
…er wording - apply_instance_created no longer clears last_failure_error so the error context persists while the new instance starts up - Dashboard retryError shows the error without (N/3) prefix when consecutiveFailures is 0 (instance was recreated) - Jaccl warning tooltip now says "experimental RDMA driver in macOS" Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Replace fragile TCP SideChannel with anonymous pipes relayed through exo's event-sourced control plane. RunnerSupervisor creates pipe pairs for MlxJaccl instances, relays all_gather rounds via JacclSideChannelData/ JacclSideChannelGathered events through the master, eliminating errno=57 crashes from Thunderbolt RDMA driver instability. Also includes dashboard RDMA warning improvements and instance retry fixes. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Anonymous pipes from os.pipe() don't survive multiprocessing.Process spawn on macOS (default since Python 3.8). The FD numbers are passed but the actual file descriptors don't exist in the child process, causing EBADF errors. Switch to named pipes (FIFOs) which the child opens by path in the spawned process, getting valid FDs for the C++ SideChannel. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
TaggedModel's wrap validator converts JSON→Python validation context, which breaks strict-mode bytes deserialization from JSON strings. Use Base64Bytes type to encode/decode bytes as base64 strings in JSON. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Cover retry logic, error handling, backward compatibility, concurrent scenarios, placement error tracking, and serialization. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Two race conditions existed in the meta-instance lifecycle: 1. CreateMetaInstance buffered MetaInstanceCreated but didn't apply it before awaiting ModelCard.load(). The reconciler could interleave during the await, leading to duplicate placements. Fix: apply MetaInstanceCreated eagerly via _apply_and_broadcast, then re-check satisfaction after the await so placement uses fresh state and skips if the reconciler already handled it. 2. delete_meta_instance (API handler) sent DeleteMetaInstance then read self.state.instances for cascade deletion. State was stale, so backing instances created between the send and the read were missed — permanently orphaning them. Fix: move cascade delete into the command processor's DeleteMetaInstance handler, where InstanceDeleted events are generated atomically with MetaInstanceDeleted. Reproduced on 4-node Mac Mini cluster: 28K anomalies in stress test including 21 permanently orphaned instances. After fix, the cascade delete and placement are race-free. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Prevents RuntimeError when the context has already been set, e.g. when Terminal.app reuses a tab or the process restarts. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
…dels On startup, _emit_existing_download_progress() used downloaded_bytes_this_session to decide between DownloadPending and DownloadOngoing. Since downloaded_bytes_this_session is always 0 on startup (it tracks the current session only), fully-downloaded models were incorrectly reported as DownloadPending. Now checks actual disk state: if downloaded_bytes >= total_bytes, emit DownloadCompleted regardless of session bytes. This fixes the UI showing models as pending when they're already available. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
- Add TaskCancelled command and Cancelled task status - Detect API client disconnects in master/api.py - Handle TaskCancelled in master state machine - Add _cancel_tasks to worker for graceful task cleanup - Add cancel_receiver to runner for inference abort - Add mx_any helper in MLX utils for cancellable operations - Guard instance lookup in worker to prevent KeyError - Update tests for cancellation flow Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
…UG-001)" This reverts commit 2a75672.
…001d) The placement algorithm previously selected the smallest viable cycle, causing large models to be distributed across too few nodes and running out of memory. Changed get_smallest_cycles to get_largest_cycles so that all healthy nodes are utilized, spreading layers more evenly. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
…ures (BUG-001c) The place_instance API endpoint used fire-and-forget: it sent the command and returned HTTP 200 immediately. On a fresh cluster start, the master's state often lacks topology/memory data, so placement raises ValueError which was silently caught and logged. The caller never learned it failed. Two fixes: - API: validate placement locally before sending, return HTTP 400 on failure instead of silently accepting an unprocessable command - Master: emit MetaInstancePlacementFailed on immediate placement error in CreateMetaInstance handler so the error surfaces in state right away Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
…eReconciler ModelCard.load() does async I/O inside the 1-second reconcile loop. A slow or failing load blocked all reconciliation (health checks, node timeouts, other meta-instances). Adds a 10-second timeout, per-meta-instance error handling with MetaInstancePlacementFailed events, and documents the intentional early return in apply_instance_retrying. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
…instance UI 1. DERIVED REACTIVITY BUG: `unifiedDisplayItems` used `$derived(fn)` which made the derived value the function itself instead of its result. Svelte never tracked reactive dependencies in the function body, so the instance list didn't update when metaInstances or instances changed. Fixed by using `$derived.by(fn)` and removing the `()` call-sites in the template. 2. TAUTOLOGICAL CHECK: In `getMetaInstancePlacingStatus`, the `lastError ? ... : null` guard inside the `failures > 0` branch was always true because `lastFailureError` and `consecutiveFailures` are always set together in `apply_instance_retrying` and `apply_instance_deleted`. Removed the dead `: null` branch. Also fixes pyright errors in test file by using proper pytest.MonkeyPatch type. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Previously, DeleteMetaInstance cascade-deleted backing instances without cancelling their active tasks, leaving orphaned task references. Now emits TaskStatusUpdated(Cancelled) for Pending/Running tasks before InstanceDeleted. Also adds lifecycle logging for meta-instance operations, a GET /meta_instances endpoint, and 2 regression tests. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
- Add TaskStatusUpdated to imports in master/main.py (used in cascade delete but missing after rebase conflict resolution) - Mock mx.distributed.all_gather in test_event_ordering.py so MockGroup works with the cancel-checking code path Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
…mbda - Add `tasks` parameter to `try_place_for_meta_instance()` in reconcile.py and thread `state.tasks` through from both call sites (main.py, meta_instance.py) - Replace untyped lambda with typed helper function in test_event_ordering.py to satisfy basedpyright strict mode Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Add missing case branch for TaskCancelled to satisfy basedpyright exhaustive match check. Deletes the associated task and cleans up the command_task_mapping, mirroring TaskFinished behavior. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
fb6a084 to
11424f6
Compare
The merge resolution kept pre-#1447 code that assigned to `instanceData` (a Svelte 5 $derived constant) and used the old /instance endpoint. Switch both launchInstance and onboardingLaunchModel to POST /meta_instance. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
The merge resolution kept pre-#1447 code that assigned to `instanceData` (a Svelte 5 $derived constant) and used the old /instance endpoint. Switch both launchInstance and onboardingLaunchModel to POST /meta_instance. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
The merge resolution kept pre-#1447 code that assigned to `instanceData` (a Svelte 5 $derived constant) and used the old /instance endpoint. Switch both launchInstance and onboardingLaunchModel to POST /meta_instance. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Motivation
Users currently manage instances directly, which means if a node disconnects or connections break, the instance dies and nothing recreates it. MetaInstance is a declarative primitive: "ensure an instance matching these parameters always exists." The reconciler watches for unhealthy or missing backing instances and re-places them automatically.
Changes
meta_instance.py): declarative constraint withmodel_id,min_nodes, optionalnode_ids, andshardingreconcile.py):find_unsatisfied_meta_instanceschecks which MetaInstances lack a healthy backing instance,try_place_for_meta_instancecreates onemain.py): periodically reconciles unsatisfied MetaInstances; immediate placement onCreateMetaInstancecommandapi.py):create_meta_instance/delete_meta_instance/GET /meta_instancesendpoints; delete cascades to backing instances with task cancellationmeta_instance_idon Instance (instances.py): no separate binding event or backing map — the instance carries its parent MetaInstance ID directly, eliminating race conditions in the reconcilerRecent improvements
DeleteMetaInstancenow emitsTaskStatusUpdated(Cancelled)for any Pending/Running tasks on backing instances before emittingInstanceDeleted. Previously, cascade-deleting backing instances left orphaned task references in state.logger.info/logger.warningfor:CreateMetaInstance(model, min_nodes, sharding),DeleteMetaInstance(with cascade count), reconciler placement success/failure, and retry decisions with attempt counts inInstanceHealthReconciler./meta_instancesendpoint — lists all meta-instances without needing to fetch full state.test_cascade_delete_cancels_active_tasksandtest_cascade_delete_skips_completed_tasksverify the cascade-delete event sequence.Why It Works
Putting
meta_instance_idonBaseInstancemakes binding inherent to instance creation. When the reconciler creates an instance for a MetaInstance, it tags it viamodel_copy. When the instance is deleted, the binding disappears with it. This avoids the two bugs that a separate binding mechanism would introduce:Test Plan
Manual Testing
Automated Testing
test_meta_instance_edge_cases.py: lifecycle, retry logic, error handling, concurrent operations, cascade delete with task cancellationtest_reconcile.py: constraint matching, connection health (single/multi-node, edge removal, IP changes), unsatisfied detection, exclusive binding, idempotency