stdlib: Add binary:encode_hex/2#6297
Conversation
CT Test Results 2 files 86 suites 35m 10s ⏱️ For more details on these failures, see this check. Results for commit b12294d. ♻️ This comment has been updated with latest results. To speed up review, make sure that you have read Contributing to Erlang/OTP and that all checks pass. See the TESTING and DEVELOPMENT HowTo guides for details about how to run test locally. Artifacts// Erlang/OTP Github Action Bot |
binary:encode_hex/2
binary:encode_hex/2binary:encode_hex/2
|
Something similar has recently been done for the The solution initially proposed there was much like this one here, and it slowed down the encoding and decoding process considerably. So, you might want to benchmark the performance before and after your change here 😉 After changes suggested by @bjorng were applied, the revised solution was about on par with the then current implementation. The same approach should also be applicable for this PR. |
| -spec encode_hex(Bin, Case) -> Bin2 when | ||
| Bin :: binary(), | ||
| Case :: lower | upper, | ||
| Bin2 :: <<_:_*16>>. |
There was a problem hiding this comment.
Would lowercase / uppercase be better namings than upper / lower? Not sure what the precedents are.
There was a problem hiding this comment.
Yes, lowercase/uppercase is better.
The performance must be the same as the original version. The algorithm hasn't been changed. It just provides new APIs. |
Running a modified version of base64_bench on the With this PR, there is a slight loss of performance: On the With this PR rebased on top of the |
e2b966c to
b12294d
Compare
Thank you. I will find a way to improve it. |
|
@bjorng out of interest, if you run the benchmarks with |
|
@Maria-12648430 There were no noticeable differences in benchmark results between the two modes.
In general, matching is not done one clause at a time in order. In this case, the selection between the two clauses is done by the following BEAM instruction: If there are many values in a I expect the most expensive part of this sequence to be the first instruction, which loads a BEAM register into CPU register |
|
@bjorng thanks for the detailed explanation, very much appreciated 🥰 |
| encode_hex(Data) when is_binary(Data) -> | ||
| << <<?HEX(N)>> || <<N>> <= Data >>; | ||
| encode_hex(Bin) -> | ||
| encode_hex(Bin, upper). |
b12294d to
61263c1
Compare
|
I improve the performance in some way ugly 😅. @bjorng Here is the bench on my computer. On the master branch, the results are: With this PR rebased on top of the master branch, the results are: |
|
I'll take a look at it tomorrow 🙂 |
|
Ok. I want to say that my review is inspired (or maybe biased) by similar work recently done on the I would suggest to conflate the functions hex(X, Off) ->
element(
X+Off,
{
% integers for uppercase
16#3030, 16#3031, 16#3032, 16#3033, 16#3034, ...
..., 16#4642, 16#4643, 16#4644, 16#4645, 16#4646,
% integers for lowercase
16#3030, 16#3031, 16#3032, 16#3033, 16#3034, ...
..., , 16#6662, 16#6663, 16#6664, 16#6665, 16#6666
}
).So if you want to query for an uppercase integer, you pass in the offset 1, for a lowercase integer you pass in 257: 1> hex(16#4a, 1).
13371
2> hex(16#4a, 257).
13409Having only one function for the translation, you can go with only one macro instead of two: -define(HEX(X, Off), (hex(X, Off)):16).And having only one function and macro, you don't need two separate functions encode_hex1(Data, Off) when byte_size(Data) rem 8 =:= 0 ->
<< <<?HEX(A, Off), ?HEX(B, Off), ?HEX(C, Off), ?HEX(D, Off),
?HEX(E, Off), ?HEX(F, Off), ?HEX(G, Off), ?HEX(H, Off)>>
|| <<A, B, C, D, E, F, G, H>> <= Data >>;
encode_hex1(Data, Off) when byte_size(Data) rem 7 =:= 0 ->
<< <<?HEX(A, Off), ?HEX(B, Off), ?HEX(C, Off), ?HEX(D, Off),
?HEX(E, Off), ?HEX(F, Off), ?HEX(G, Off)>>
|| <<A, B, C, D, E, F, G>> <= Data >>;
...
encode_hex1(Data, Off) when is_binary(Data) ->
<< <<?HEX(N, Off)>> || <<N>> <= Data >>;
encode_hex1(Bin, Off) ->
badarg_with_info([Bin, Off]).(Actually, if you define your macro like The proper value for the offset can be determined and passed in from encode_hex(Bin, uppercase) ->
encode_hex1(Bin, 1);
encode_hex(Bin, lowercase) ->
encode_hex1(Bin, 257).I think by going like this, the code would be smaller and cleaner (but make sure to add comments explaining what that Offset is about ;)), without any performance penalties. Anyway, I would advise to wait for @bjorng's comment before doing anything 😉 |
 bjorng
left a comment
bjorng
left a comment
There was a problem hiding this comment.
I agree with @juhlig's suggestions.
We don't want to have only property tests; there should always be some tests for if proper is not installed. Please update binary_module_SUITE.
Make sure that the documentation have the correct name for the options.
2593435 to
c04af5d
Compare
| UpperHex = binary:encode_hex(Data, uppercase), | ||
| LowerHex = binary:encode_hex(Data, lowercase), | ||
| binary:decode_hex(LowerHex) =:= Data andalso binary:decode_hex(UpperHex) =:= Data |
There was a problem hiding this comment.
This is nice as far as it goes, and you should keep it, but this only tests that what was hex-encoded can be hex-decoded. In other words, it is not tested if encode_hex produces the correct output, only that decode_hex can decode whatever encode_hex produced back into the initial binary.
A way you could test correct output (without repeating the actual implementation) could be with a helper function like this:
check_hex_encoded(<<I1:4, I2:4, Ins/binary>>, <<U1:8, U2:8, UCs/binary>>, <<L1:8, L2:8, LCs/binary>>) ->
check_hex_chars_match(I1, U1, L1) andalso
check_hex_chars_match(I2, U2, L2) andalso
check_hex_encoded(Ins, UCs, LCs);
check_hex_encoded(<<>>, <<>>, <<>>) ->
true;
check_hex_encoded(_, _, _) ->
false.
check_hex_chars_match(X, U, L) when X < 10 ->
(U =:= $0 + X) andalso (L =:= $0 + X);
check_hex_chars_match(X, U, L) ->
(U =:= $A + X -10) andalso (L =:= $a + X -10).... and call it from the property like check_hex_encoded(Data, UpperHex, LowerHex).
(Note that I just typed this off the top of my head, didn't test it, so there may be bugs and/or typos 😅)
I admit this won't be hideously fast (for which reason I would just use the normally-growing binary() generator instead of resizing it), but with tests it is more important to be thorough than to be fast 😉
c04af5d to
86bc409
Compare
 juhlig
left a comment
juhlig
left a comment
There was a problem hiding this comment.
IMO, this is fine now. Only some minor indendation issues ;)
| begin | ||
| UpperHex = binary:encode_hex(Data, uppercase), | ||
| LowerHex = binary:encode_hex(Data, lowercase), | ||
| binary:decode_hex(LowerHex) =:= Data andalso | ||
| binary:decode_hex(UpperHex) =:= Data andalso | ||
| check_hex_encoded(Data, UpperHex, LowerHex) | ||
| end). |
There was a problem hiding this comment.
| begin | |
| UpperHex = binary:encode_hex(Data, uppercase), | |
| LowerHex = binary:encode_hex(Data, lowercase), | |
| binary:decode_hex(LowerHex) =:= Data andalso | |
| binary:decode_hex(UpperHex) =:= Data andalso | |
| check_hex_encoded(Data, UpperHex, LowerHex) | |
| end). | |
| begin | |
| UpperHex = binary:encode_hex(Data, uppercase), | |
| LowerHex = binary:encode_hex(Data, lowercase), | |
| binary:decode_hex(LowerHex) =:= Data andalso | |
| binary:decode_hex(UpperHex) =:= Data andalso | |
| check_hex_encoded(Data, UpperHex, LowerHex) | |
| end). |
Indendation.
| check_hex_chars_match(I2, U2, L2) andalso | ||
| check_hex_encoded(Ins, UCs, LCs); |
There was a problem hiding this comment.
| check_hex_chars_match(I2, U2, L2) andalso | |
| check_hex_encoded(Ins, UCs, LCs); | |
| check_hex_chars_match(I2, U2, L2) andalso | |
| check_hex_encoded(Ins, UCs, LCs); |
Indendation.
| <p>Encodes a binary into a hex encoded binary using the specified case for the Hex digits "a" to "f".</p> | ||
| <p>The default case is <c>uppercase</c>.</p> | ||
| <p><em>Example:</em></p> | ||
|
|
||
| <code> |
There was a problem hiding this comment.
| <p>Encodes a binary into a hex encoded binary using the specified case for the Hex digits "a" to "f".</p> | |
| <p>The default case is <c>uppercase</c>.</p> | |
| <p><em>Example:</em></p> | |
| <code> | |
| <p>Encodes a binary into a hex encoded binary using the specified case for the Hex digits "a" to "f".</p> | |
| <p>The default case is <c>uppercase</c>.</p> | |
| <p><em>Example:</em></p> | |
| <code> |
Indendation.
| <<"2f">> | ||
| 4> binary:encode_hex(<<"/">>, uppercase). | ||
| <<"2F">> | ||
| </code> |
There was a problem hiding this comment.
| </code> | |
| </code> |
Indendation.
|
Nice, I think this is almost good to go now, only the indendation 😉 |
86bc409 to
e011fc8
Compare
|
I've been busy the last week or so and I haven't had time to fully review the latest changes. Thanks @juhlig and @Maria-12648430 for the reviewing you've done. However, when I took a quick look yesterday and ran the test suite and attempted to build the documentation, I noticed that the test case |
|
By the way, I've created a ticket number to use in the (@juhlig No, I don't think it's mentioned in our contribution guidelines.) |
The documentation build failure is probably because you removed the About the |
6716d85 to
090e267
Compare
| <<"not a binary">>; | ||
| expand_error(bad_hex_case) -> | ||
| <<"not uppercase or lowercase">>; | ||
| expand_error(not_compiled_regexp) -> |
There was a problem hiding this comment.
However, when I took a quick look yesterday and ran the test suite and attempted to build the documentation, I noticed that the test case
binary_module_SUITE:error_info/1fails, and that the documentation fails to build.The documentation build failure is probably because you removed the
sincetag from your new function altogether. I believe it can be left empty, but its presence is required. Since you now have a ticket number, you should put it in thesincetag like thissince="OTP @OTP-18354@", and that should also solve the build issue.About the
error_infotest failure, I have no idea though =^^=
I have fixed the error_info test failure now. @juhlig
|
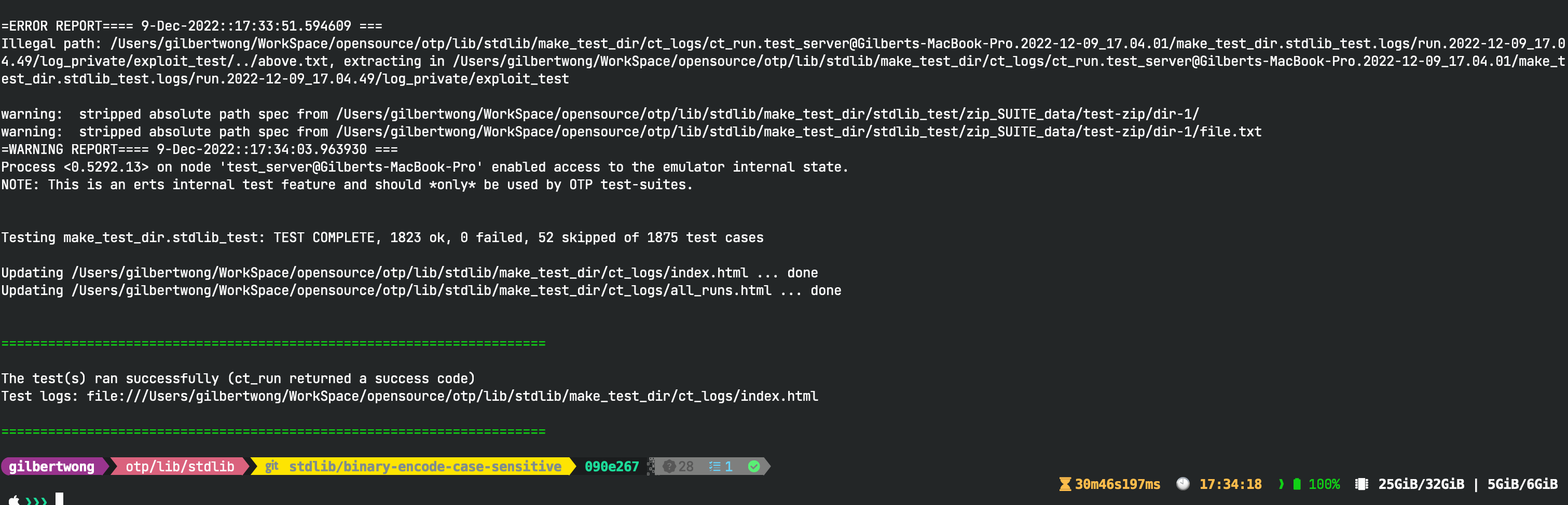
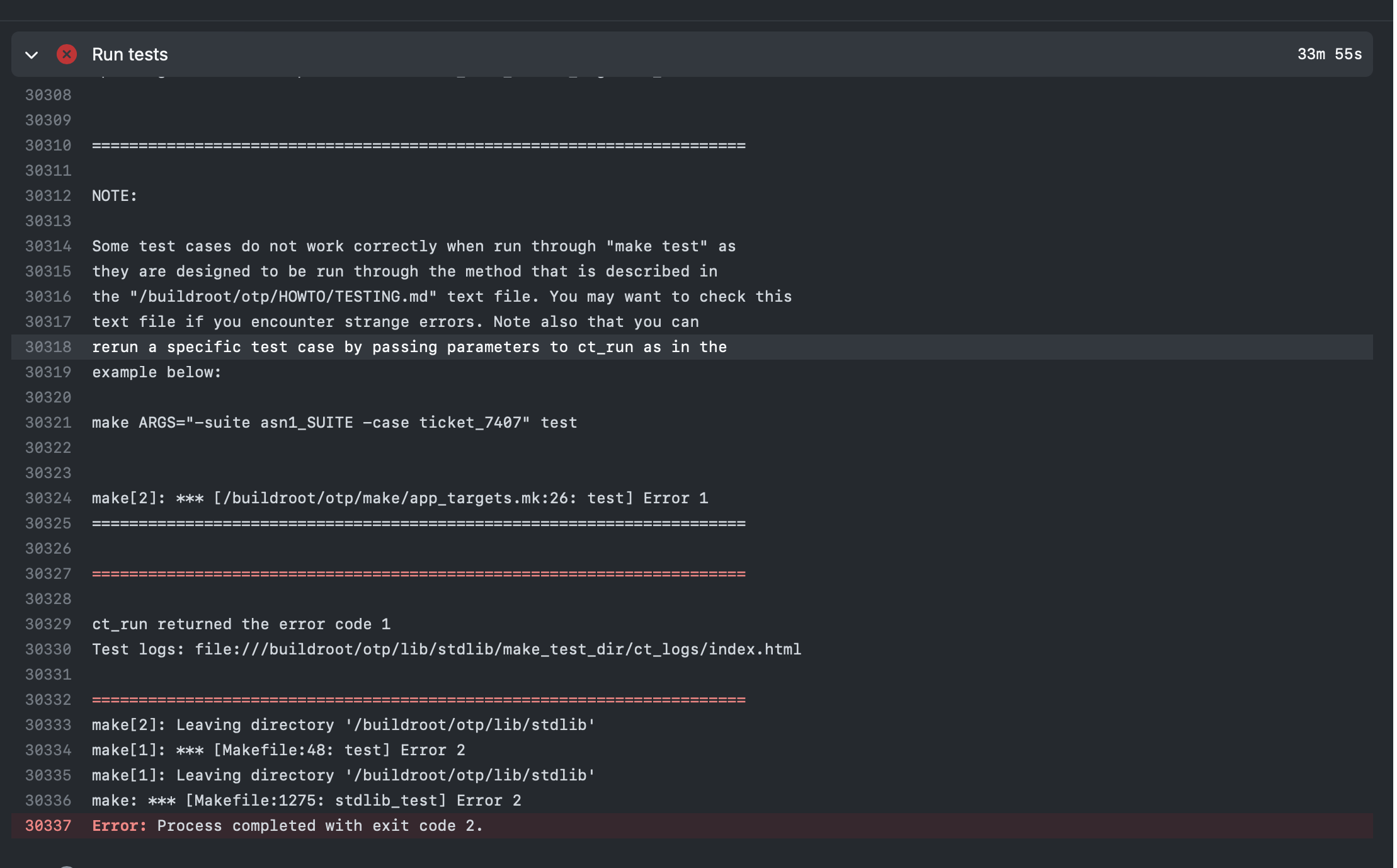
The stdlib tests ran successfully on my machine, but it failed in CI
I don't know why. Do you have any ideas? |
|
We know that there are some test cases that tend to fail in github actions. It is not your fault. |
bjorng
left a comment
There was a problem hiding this comment.
I have only one more nit pick in the documentation. Otherwise looks good. When you have fixed that, please squash your commits, rebase on the master branch, and retarget the pull request to master.
| <fsummary>Encodes a binary into a hex encoded binary with specified case</fsummary> | ||
| <desc> | ||
| <p>Encodes a binary into a hex encoded binary.</p> | ||
| <p>Encodes a binary into a hex encoded binary using the specified case for the Hex digits "a" to "f".</p> |
There was a problem hiding this comment.
| <p>Encodes a binary into a hex encoded binary using the specified case for the Hex digits "a" to "f".</p> | |
| <p>Encodes a binary into a hex encoded binary using the specified case for the hexadecimal digits "a" to "f".</p> |
090e267 to
21e3016
Compare
The `binary` module only exposes `encode_hex/1` which encodes binary to a hex-encoded binary. The output as the number in hexadecimal, with a through f is in the upper case by default. This change allows the user to decide to use upper case or lower case.
21e3016 to
a30a54d
Compare
|
Thanks! Added to our daily builds. |
|
Thanks for your pull request! |
The
binarymodule only exposesencode_hex/1, which only supports uppercase output.This change adds
binary:encode_hex/2to support uppercase and lowercase hex-encoding. After this change,encode_hex/1supports uppercase by default.