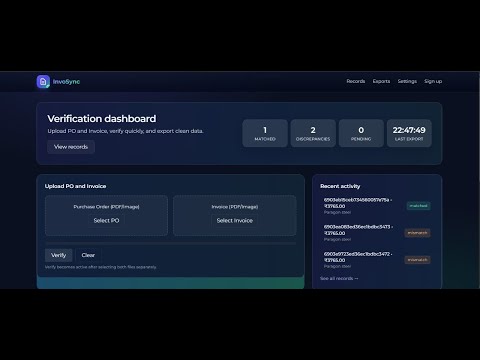
InvoSync is an AI-powered invoice and purchase order reconciliation system that uses Tesseract OCR and RapidFuzz to detect, extract, and compare data from scanned invoices and purchase orders. It automatically highlights mismatches, corrects inconsistencies, and exports clean, standardized results — saving hours of manual verification work.
- OCR Extraction: Reads invoice and purchase order data using Tesseract OCR.
- Discrepancy Detection: Automatically compares and corrects vendor, quantity, and pricing mismatches.
- Data Export: Generates corrected CSV reports and discrepancy summaries.
- Modern Frontend: Built using React.js + Vite for a fast and smooth UI.
- Seamless Backend Integration: Flask backend for OCR, comparison, and API handling.
- Modular Architecture: Clean separation of OCR, parsing, comparison, and export logic.
| Layer | Technologies |
|---|---|
| Frontend | React.js, Vite, TailwindCSS |
| Backend | Python, Flask |
| OCR Engine | Tesseract OCR |
| Text Matching | RapidFuzz |
| Data Processing | Pandas, Regex |
| File Handling | Pillow, pdf2image |
InvoSync/
│
├── backend/
│ ├── app.py # Flask app entry point
│ ├── compare.py # Handles comparison between PO and invoice
│ ├── export.py # Exports corrected data to CSV
│ ├── ocr.py # OCR logic using Tesseract
│ ├── parse.py # Parses extracted text into structured format
│ └── requirements.txt # Backend dependencies
│
├── frontend/
│ ├── index.html
│ ├── package.json
│ ├── package-lock.json
│ └── src/
│ ├── App.jsx
│ ├── main.jsx
│ ├── components/
│ │ ├── HowItWorks.jsx
│ │ ├── Page.jsx
│ │ └── Shell.jsx
│ ├── lib/
│ │ └── api.js
│ └── pages/
│ ├── Dashboard.jsx
│ ├── Exports.jsx
│ ├── Login.jsx
│ ├── RecordDetail.jsx
│ ├── Records.jsx
│ ├── Review.jsx
│ ├── Settings.jsx
│ ├── Signup.jsx
│ └── Upload.jsx
│
└── README.md
+---------------------+
| Frontend (React) |
| ──────────────── |
| Upload Invoices |
| View Discrepancies |
+----------+----------+
|
v
+---------------------+
| Backend (Flask) |
| ─────────────── |
| OCR Extraction |
| Parsing & Comparison |
| Export to CSV |
+----------+----------+
|
v
+---------------------+
| Tesseract OCR |
| Image → Text |
+---------------------+
cd backend
python -m venv venv
source venv/bin/activate # (Windows: venv\Scripts�ctivate)
pip install -r requirements.txt
python app.pyBackend runs on http://localhost:5000
cd frontend
npm install
npm run devFrontend runs on http://localhost:5173
Tesseract OCR is an open-source engine developed by Google that extracts text from images and PDFs.
In InvoSync, it’s used inside backend/ocr.py to process invoice and purchase order files.
Pipeline:
- Preprocess image using
PillowandImageEnhancefor better clarity. - Extract text via:
import pytesseract text = pytesseract.image_to_string(image)
- Parse the extracted text into structured fields (item name, quantity, price, total).
- Compare extracted invoice and purchase order details using RapidFuzz for fuzzy string matching.
- Upload
invoice.jpgandpurchase_order.jpgthrough the frontend. - Backend extracts and parses data using Tesseract OCR.
- Mismatches (e.g., price/quantity/vendor) are identified.
- Corrected invoice and discrepancy report are exported as:
corrected_invoice.csvdiscrepancy_report.csv
| File | Description |
|---|---|
corrected_invoice.csv |
Final corrected invoice after comparison |
discrepancy_report.csv |
Log of mismatches and corrections made |
Developed by:
Ashish Kumar Nanda
Kushagra Gupta
Rashi Gupta
Radhi Pahuja
If you find this project useful, please consider giving it a ⭐ on GitHub!