A Classification model to correctly classify the news into suitable sub-categories of Fake News based on features extracted.
The condensed table for the classification is as follows:
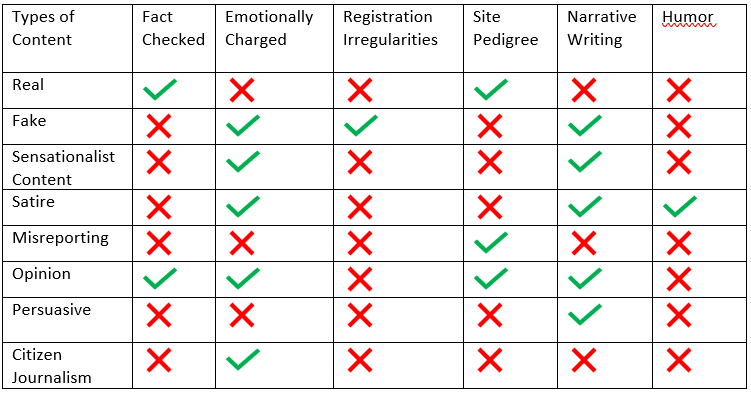
The datasets used are FakeNewsNet and BSDetector for the purpose, which has features like Title, Text, Source, Author, Images, Metadata etc.
From the dataset (1536 samples) I extracted the features listed in the table and ran the Partitioning Around Mediods(K-Mediods) Clustering and K-modes Clustering on it. The clusters generated are then analysed and labelled.
I also prepared a test dataset of about 100 samples (from the Politifact Dataset). I manually labelled this test dataset and ran the selected algorithms using it. I then compared the clusters the algorithms assigns each data-point to, with the label I assigned to it and calculated the accuracy.
The K-Mediods Clustering gave the accuracy of about 84 %, while the K-Modes Clustering gave the accuracy of about 81 %.
