This a Deep Learning project based on the Bike-sharing dataset. It implements a neural network from scratch and uses commonly used algorithms such as gradient descent, backpropogation, and data cleaning.
The goal of the project is to predict the optimal number of bikes that a company needs in the near future for maximum profit. This project is also a classical example of the applicaiton of data science and statistics in economics.
- Load and prepare the data - A critical step in working with neural networks is preparing the data correctly. Variables on different scales make it difficult for the network to efficiently learn the correct weights.
- Checking and cleaning the data
- Scaling target variables - To make training the network easier, each of the continuous variables is standardized. That is, the variables are shifted and scaled such that they have zero mean and a standard deviation of 1.
- Splitting the data into training, testing, and validation sets
- Network Development
- Prepare unit tests to check the training of the network
- Training the network
- Making predictions
More information is provided in the project file - Predicting_bike_sharing_data.ipynb
A very basic network is used for this project. There is one hidden layer with neurons between the input and output layer.
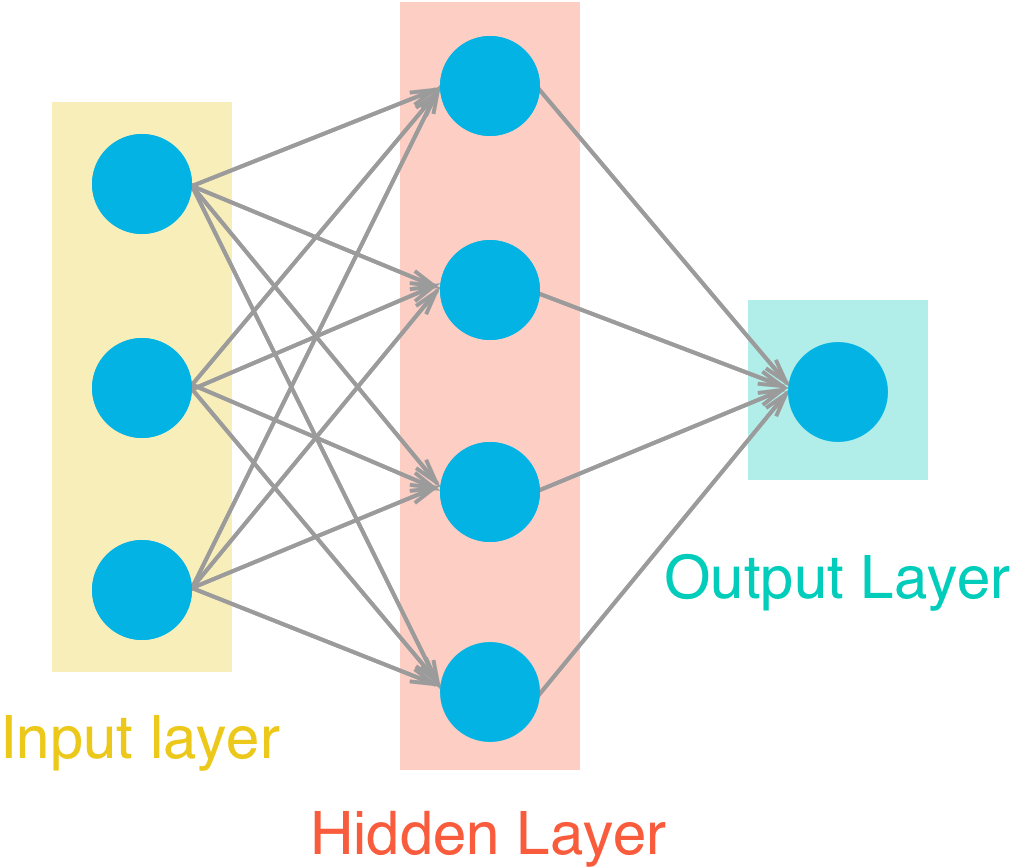
The model, after training, was tested on the validation data set. The predictions compared with the actual data is:
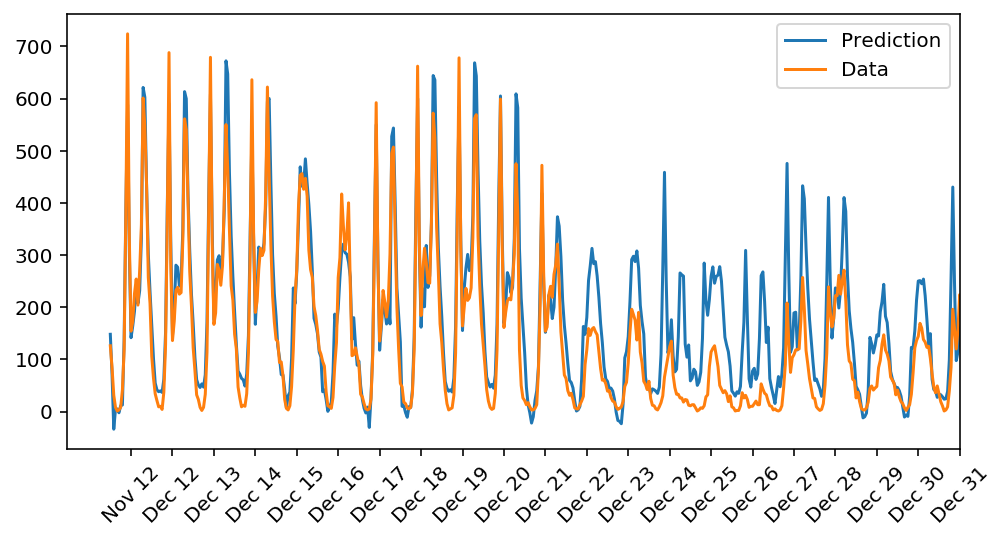
The predictions are consistent with the actual data. Thus, the model can be used to predict the number of bikes that a company must possess at a particular time to increase profits. This model can be used for other such economic queries as well. All that is required is to retrain the network based on the old data.
The following libraries were used to make this project:
- Python 3.7
- pandas
- numpy
- matplotlib