Acknowledgement: This project is inspired by the DCGANfakeface.
Since everyone here speaks Chinese, let's introduce in Chinese.
我们推测大家对机器学习应该会比较好奇。
因此给大家出一个小项目来让大家知道机器学习的项目一般长什么样(祛魅)。
当然,这仅仅是最基础的入门。以及,祛魅本身是中性的。
我们需要你实现一个DCGAN(深度生成对抗网络)。
关于DCGAN能生效的原因,我们在此并不进行详细讲解,如果有需要,可以在网上学习相关内容。
此处我们给出原论文:
- Generative Adversarial Networks
- Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
在本项目中,你只需要完成 network 的建立,所以实际上你只用了解网络的结构即可。
我们希望你对 network.py 中的 Generator 和 Discriminator 进行实现。
具体而言,你需要实现他们的 __init__ 和 forward(以及可能存在的一些辅助函数)。
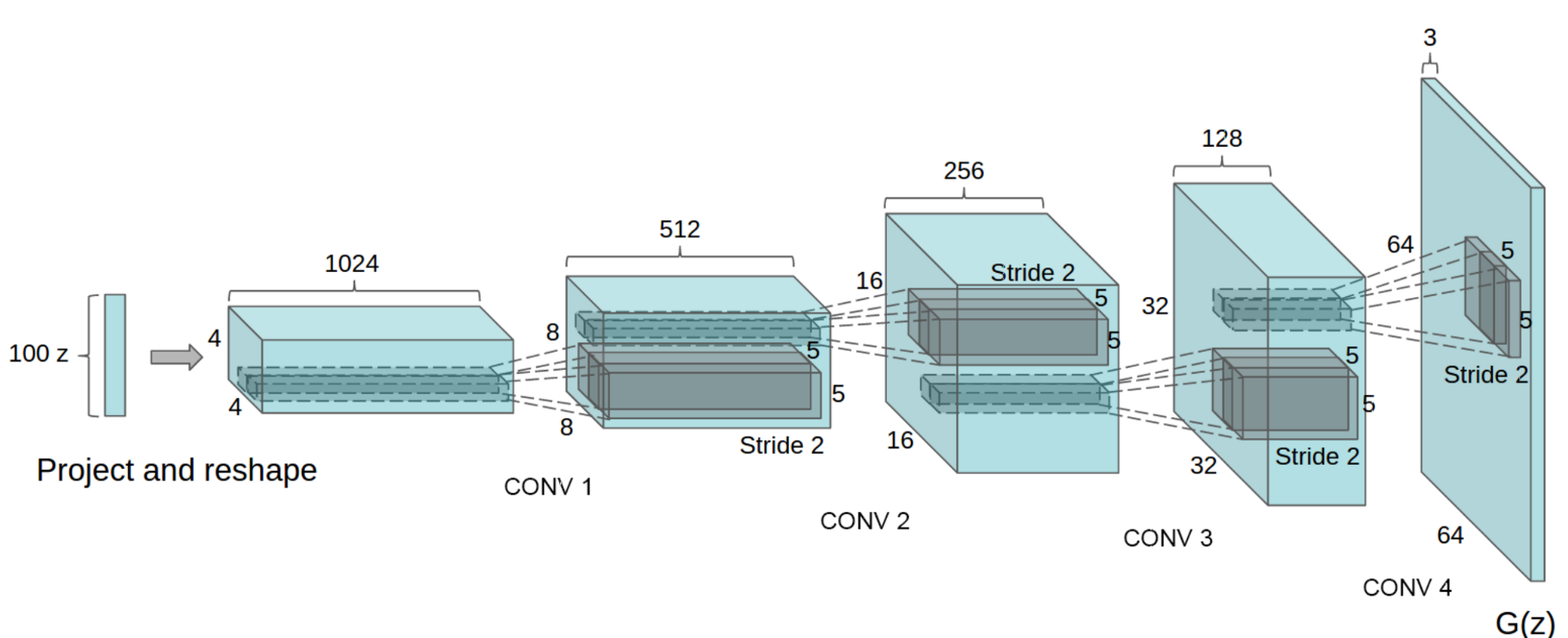
你可能要用到 nn.ConvTranspose2d 和 nn.BatchNorm2d。
论文中给出的卷积核大小为 5*5。

你可能要用到 nn.Conv2d 和 nn.BatchNorm2d。
关于这些函数最简单的使用方式,可以参考我们给出的文档。
更具体的知识可以看这篇文章。
论文中给出的卷积核大小为 5*5。
我们这里引用论文的原话:
- Replace any pooling layers with strided convolutions (discriminator) and fractional-strided convolutions (generator).(这条对应的是 structure 中的内容)
- Use batchnorm in both the generator and the discriminator.(这条提示你在何处用
nn.BatchNorm2d) - Remove fully connected hidden layers for deeper architectures.(这条提示你不需要使用全连接层)
- Use ReLU activation in generator for all layers except for the output, which uses Tanh.(这条提示你
forward怎么写) - Use LeakyReLU activation in the discriminator for all layers.(这条提示你
Discriminator的forward额外需要修改什么)
我们直接引用原文:
No pre-processing was applied to training images besides scaling to the range of the tanh activation
function
All models were trained with mini-batch stochastic gradient descent (SGD) with
a mini-batch size of
All weights were initialized from a zero-centered Normal distribution
with standard deviation
In the LeakyReLU, the slope of the leak was set to
While previous GAN work has used momentum to accelerate training, we used the Adam optimizer (Kingma & Ba, 2014) with tuned hyperparameters.
We found the suggested learning rate of
Additionally, we found leaving the momentum term
部分超参数的设置已经帮大家写好了,但是关于 network 的超参数需要大家自己设置。
关于 BatchNorm2d 的 momentum 原文没有提及,大家可以自行设置(或者default)。
认真读读报错信息,用 pdb 或者 print 语句输出每一层的形状,从而找到错误的位置。
关于为什么我们的损失函数(criterion)选择的是 nn.BCELoss,可以参考 这里。
我们使用 Celeb-A Faces 数据集,在我们给出的链接中,有通过 Google 链接的下载方式。
当然如果你想通过国内的网站下载,我们也给出如下链接:下载链接。
请留出时间下载数据集(8G),不然你可能会来不及完成项目。
我们希望数据集(文件夹)放在 "img/" 目录下。
用于预处理数据集,把图片缩放到 64x64 的大小。预期处理后的目录为 "img/processed/"
用于加载数据集,在本次项目中,你不需要显示调用这个文件。值得注意的是,加载的数据集不是原始数据集,而是经过 preprocess.py 处理后的数据。
用于构建 DCGAN 的网络结构。也是你需要完成的部分。
用于训练网络,其中训练完成的参数会保存在 "generator.params" 中。
从 "generator.params" 中加载训练好的参数,并生成图片。
实际上你需要先运行 preprocess.py,然后运行 train.py,最后运行 generator.py。
preprocess.py 只需要运行一次(在不修改 preprocess.py 的情况下)。
具体构成如下:
-
代码实现和结果展示 70%
-
解释文档 20%
- 解释实现过程
- 解释
train.py的大致思想
-
额外实现 10%
-
额外实现的内容可以是任何你想做的事情,比如说:
- 提供用于评判生成质量的指标
- 实现一个更好的网络结构(数据或者理论支撑)
- 更高的分辨率(见
preprocess.py,值得注意的是,你的网络也会因此变化) - 其他(请提前和助教联系,不然不一定保证得分)
-
- scikit-image
- numpy
- matplotlib
- torch
- 其他
配环境是不得不品鉴的一环,大家加油!(记得配带gpu的版本,如果有gpu的话)
请于 2025.7.6(周日)23:59 之前提交。(暂定)
请提交一份 report.pdf 以及对应的 .md 文件(如果可以的话)