🔹 Etapas
🔹 Execução
Este projeto consiste na criação de uma solução que simula um Parque Eólico com a produção de dados de sensores por meio de aplicações Python usando os serviços da AWS. O objetivo é monitorar os dados produzidos e ver se correspondem com o esperado, de modo a garantir a qualidade da produção de energia no Parque Eólico.
O projeto consiste nos seguintes passos:
- Criar um Data Stream no Kinesis Data Stream
- Criar aplicações Python para gerar os dados
- Criar um bucket no S3 para receber os dados
- Criar um Kinesis Data Firehouse para entregar os dados
- Criar uma database no Glue Data Catalog
- Criar um crawler no Glue Data Catalog
- Criar um novo bucket S3
- Criar um job ETL no Glue para transformar os dados gerados de JSON para Parquet
- Criar um outro crawler no Glue para inferir o schema dos dados transformados
- Criar consultas no Athena
Esse é um projeto end-to-end, desde a produção dos dados até a disponibilização dos mesmos para consulta, usando os serviços da AWS. A arquitetura completa pode ser visualizada a seguir:
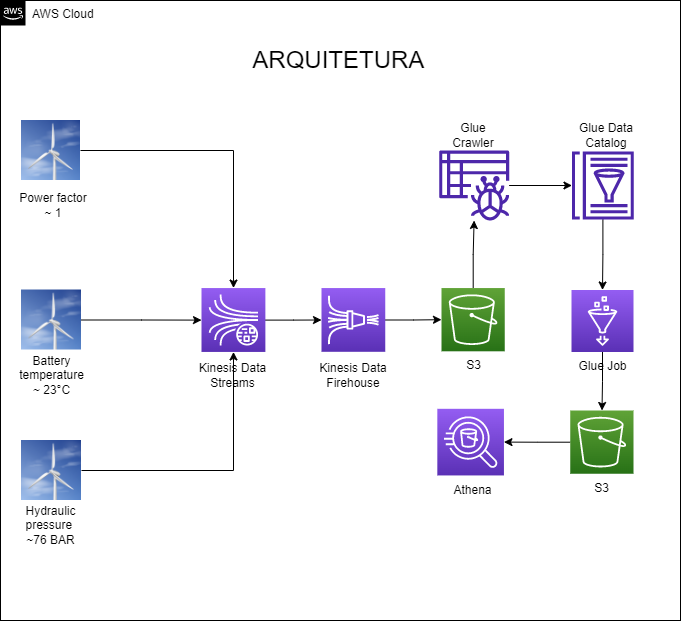
Créditos pela imagem da turbina eólica: Imagem de macrovector no Freepik
Para executar esse projeto é necessário ter o Jupyter Notebook instalado localmente ou uma conta Google para acessar o Colab e uma conta na nuvem AWS.
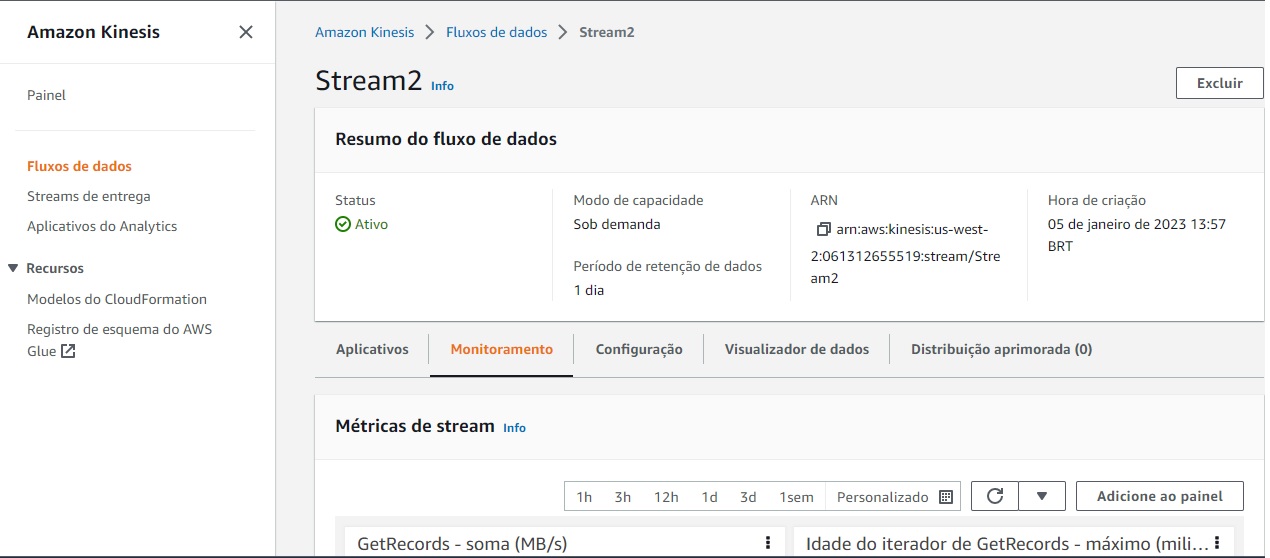
Essa primeira etapa consiste em acessar o serviço Kinesis e gerar fluxos de dados (data streams) de nome Stream2, por exemplo, que será usado pela aplicação python geradora de dados para transmitir os dados como streaming.
A imagem abaixo demonstra o fluxo de dados criado.
Nessa segunda etapa, geram-se as aplicações python que simulam os sensores de um parque eólico e que produzem os dados que serão, posteriormente, usados pelos serviços da AWS. São criadas 3 aplicações python, simulando 3 sensores conforme abaixo:
- Sensor de fator de potência gerando potências em torno de 1
- Sensor de temperatura gerando temperaturas em torno de 23°C
- Sensor de pressão hidráulica gerando pressão em torno de 76 BAR
As aplicações produzem dados a cada 10 segundos no formato JSON contendo os seguintes campos:
- id - identificador do registro
- data - o dado em si
- type - o tipo de dado, podendo ser powerfactor, temperature ou hydraulicpressure
- timestamp - data e hora que o registro foi gerado
Para transmitir os dados para o data stream Stream2 criado no Kinesis Data Stream, deve-se, primeiramente, iniciar uma conexão cliente com o Kinesis através da biblioteca boto3. Em seguida, deve-se preencher os campos aws_access_key_id e aws_secret_access_key com a chave secreta gerada na sua conta da AWS, e region_name com o nome da região onde o bucket da etapa anterior foi criado. Além disso, precisa também especificar o campo StreamName com o nome do data scream criado na primeira etapa e o campo PartitionKey com o valor da chave que será usada para identificar o shard do Kinesis Data Stream para o qual os registros serão enviados.
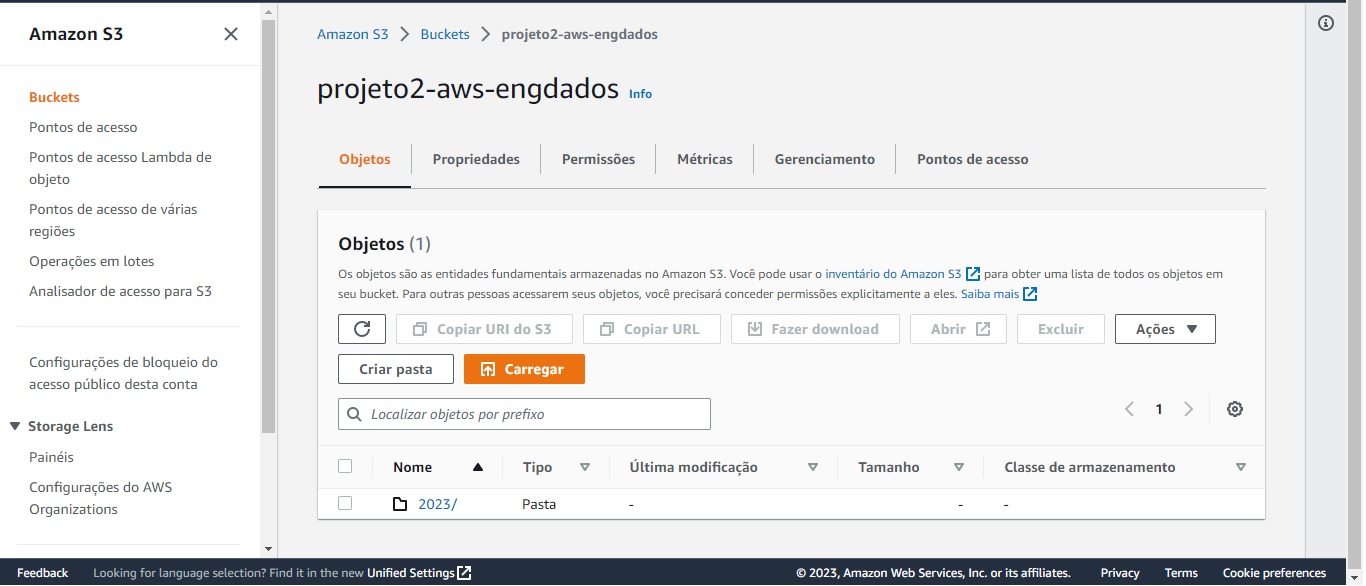
O terceiro passo consiste em acessar o serviço S3 e criar um bucket de nome projeto2-aws-engdados, por exemplo, para receber os dados vindos do Kinesis Data Firehouse, conforme mostra a imagem abaixo:
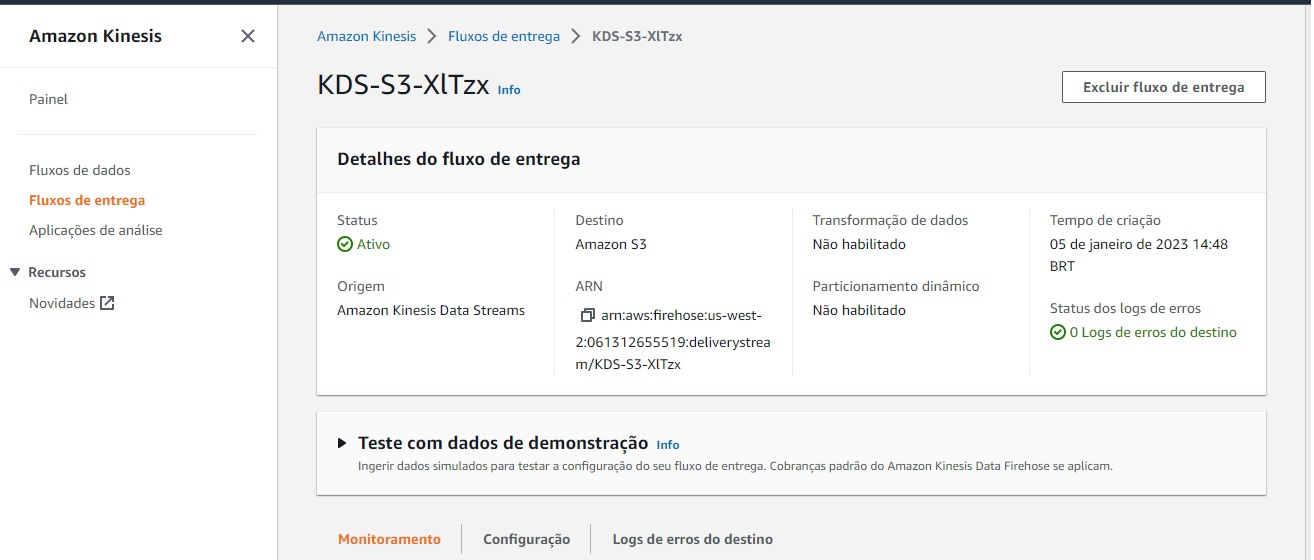
A quarta etapa é criar um fluxo de entrega no Kinesis Data Firehouse que entregará todos os dados em um mesmo arquivo particionado por ano, mês e dia ao bucket no S3. Ao criar o fluxo, precisa-se configurar a origem e o destino dos dados como sendo, respectivamente, o Kinesis Data Stream e o bucket criado na etapa anterior. Precisa-se também estabelecer o tempo de latência (da entrega dos dados ao bucket) como 60 segundos. A figura abaixo mostra o Data Firehouse gerado:
Na quinta etapa, é necessário acessar o Glue Data Catalog e criar uma database, que é repositório de dados, no qual ficarão armazenadas as tabelas que tiveram o seu schema inferido pelo crawler, que será gerado no próximo passo. Nesse projeto foi criada a database dados_sensores, conforme mostra a imagem abaixo:

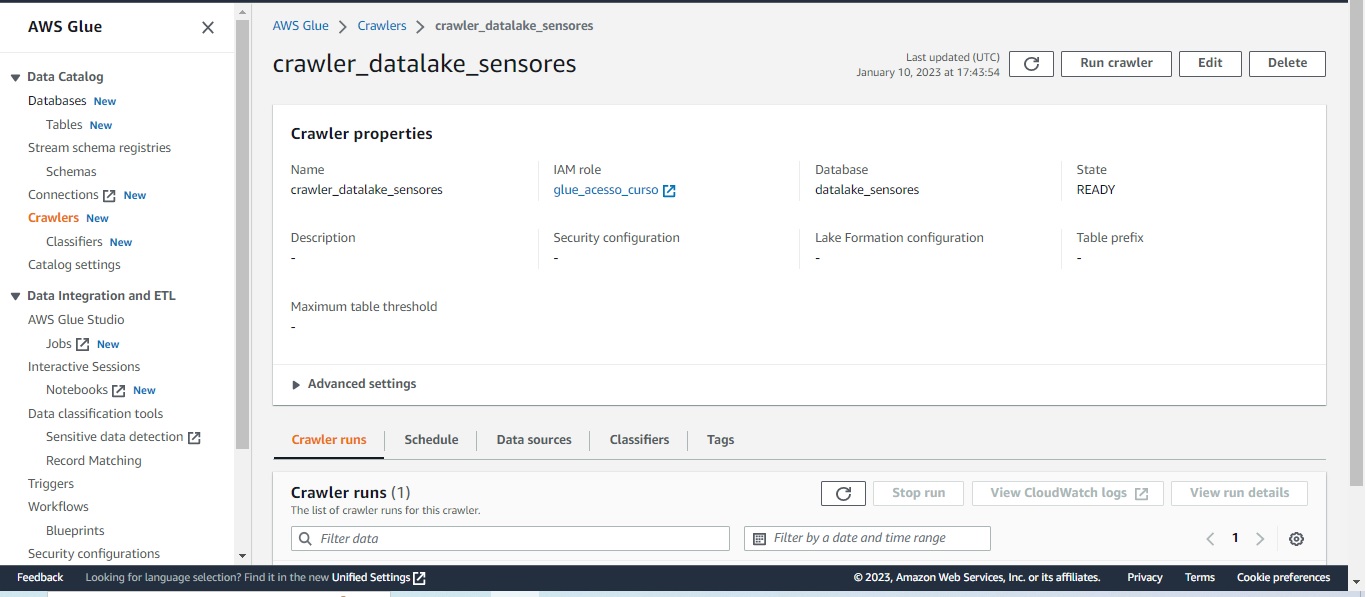
A sexta etapa consiste em criar um crawler no Glue Data Catalog, que inferirá o schema dos objetos armazenados no bucket S3. No caso, esses objetos são os dados gerados pelas aplicações python armazenados no bucket projeto2-aws-engdados, transformando-os em tabelas. Ao criar um crawler, precisa-se associar os dados a uma database, que no caso será a dados_sensores, gerada na etapa anterior. Além disso, é precisa-se configurar uma IAM role que tenha acesso ao bucket S3. O crawler gerado é mostrado na imagem abaixo:
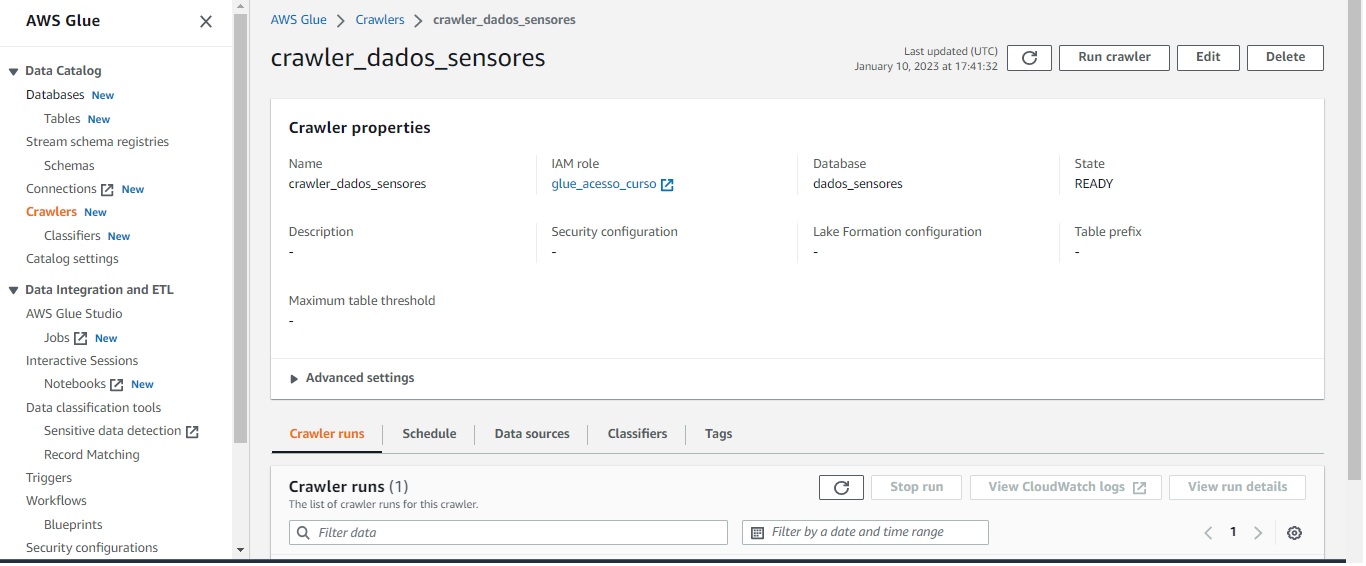
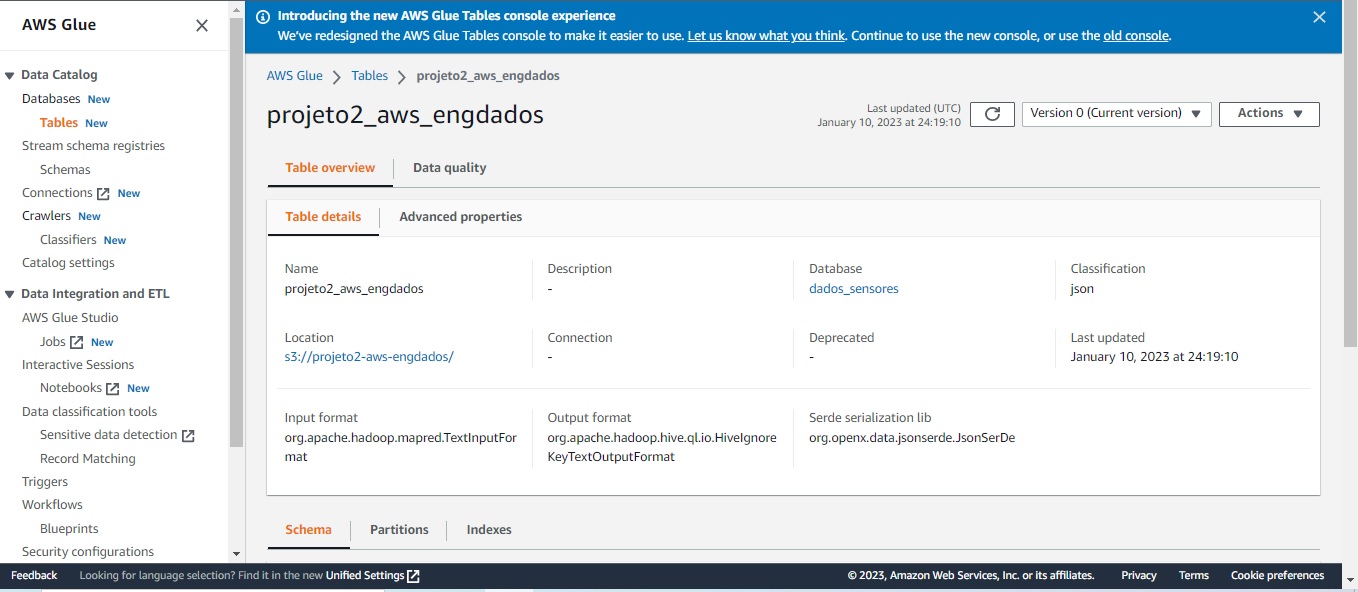
Ao executar o crawler, é criada a tabela projeto2-aws-engdados, a partir do bucket de mesmo nome, associada a database *dados_sensores, conforme pode ser visto na figura a seguir:
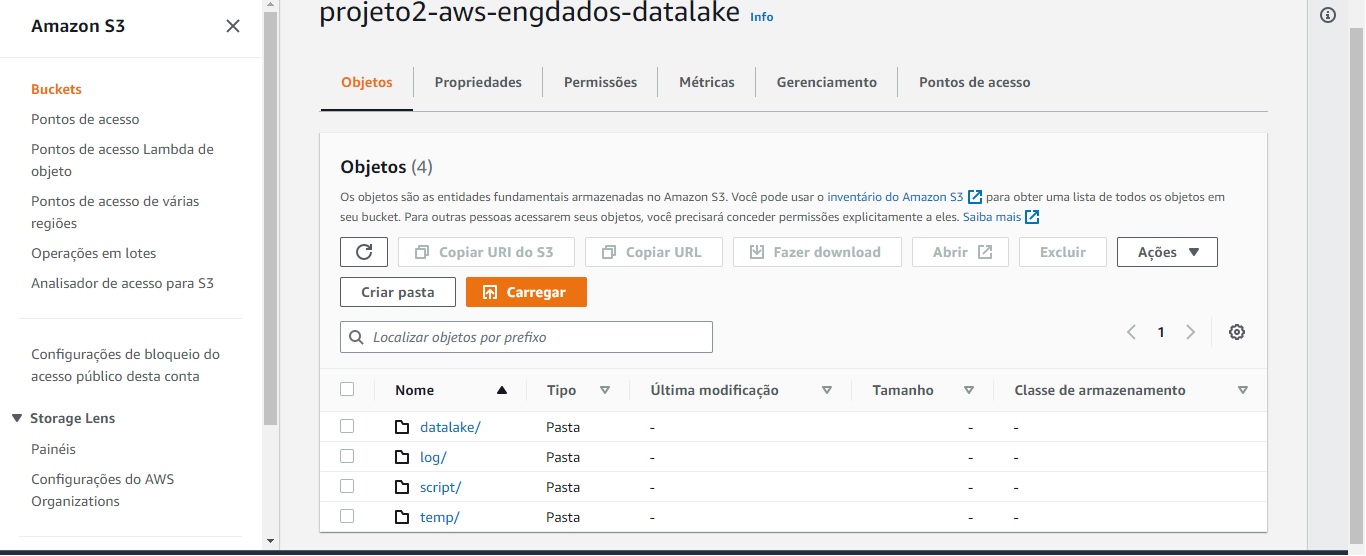
Essa etapa consiste em criar um novo bucket no S3 chamado projeto2-aws-engdados-datalake, que funciona como um datalake para armazenar os dados transformados gerados pelo Glue job (pasta datalake), seus scripts de transformação (pasta script), seus logs (pasta log) e arquivos temporários (pasta temp). A imagem abaixo ilustra isso:
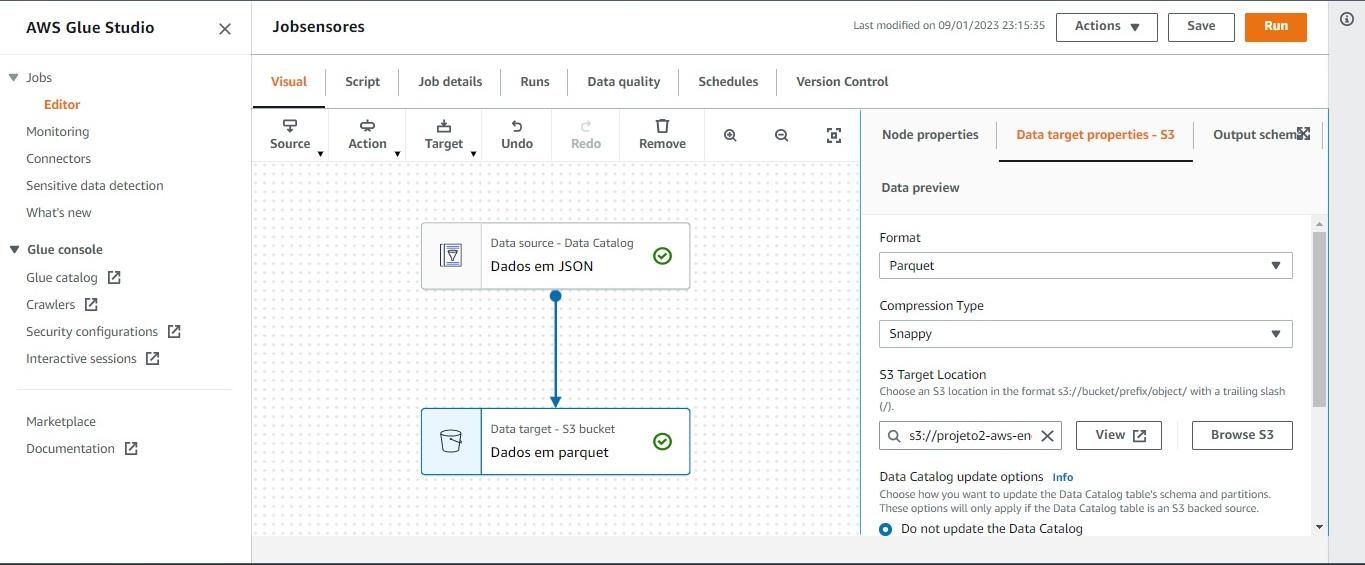
A sétima etapa é criar e executar um job ETL, que extraia a tabela projeto2_aws_engdados gerada no Data Catalog, transforme-a do formato JSON para Parquet e armazene no bucket projeto2-aws-engdados-datalake na pasta datalake, que funciona como um datalake. Para criar o job, usa-se uma interface visual iniciando com um canvas em branco, onde pode-se selecionar os ícones que representam a origem, o tipo de transformação e o destino dos dados. A figura abaixo ilustra isso:
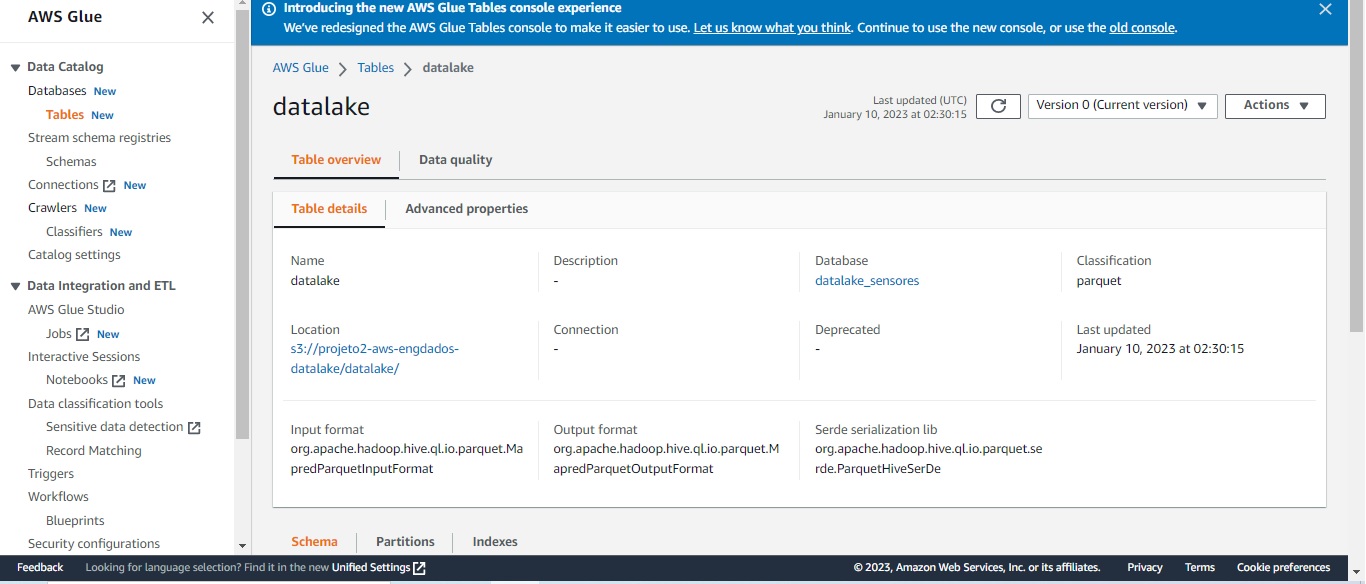
Após executar o job ETL e gerar os dados transformados, o próximo passo é, primeiramente, criar uma database chamada datalake-sensores. Em seguida, gerar um novo crawler que infira o schema desses dados transformados armazenados na pasta datalake do bucket projeto2-aws-engdados-datalake e associe a tabela datalake produzida a essa nova database no Data Catalog, para que ela possa ser usada no Athena. A database, o crawler e a tabela gerada são demonstrados nas figuras a seguir:

A partir das tabelas armazenadas no Data Catalog, é possível gerar consultas SQL no Athena, sem a necessidade de provisionar um servidor. Para isso, basta acessar o editor de consulta no painel do Athena, configurar o Data Catalog como a origem dos dados, a database e rodar as queries desejadas. Os dados gerados pelas consultas, devem ser armazenados em um bucket S3 específico para o Athena.
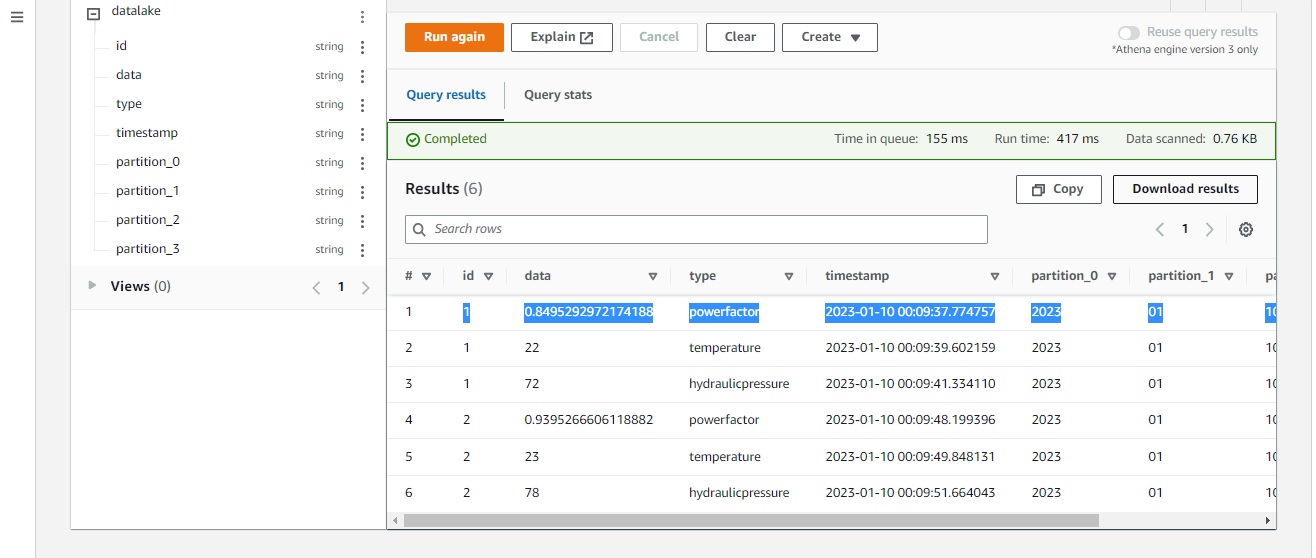
A figura, a seguir, mostra o resultado da consulta de todos os dados da tabela datalake:
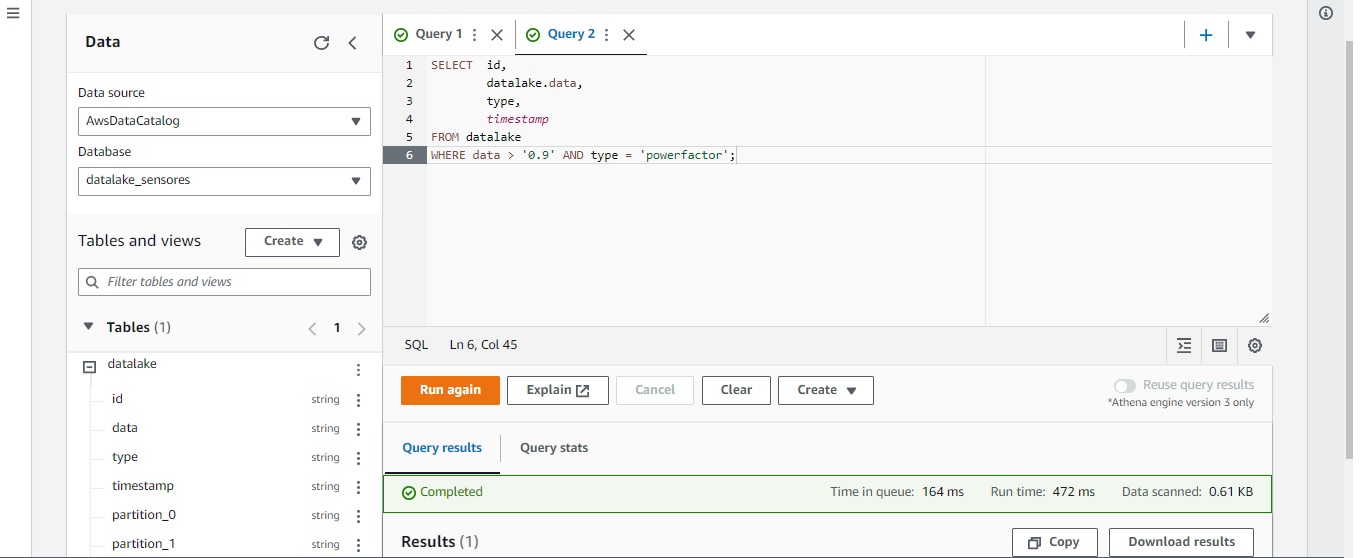
Também foi rodada uma query no qual retorna todos os campos da tabela datalake cujos dados tenham valores maiores que 0.9 e tipo igual a powerfactor, conforme visto pelas imagens abaixo:

OBS: Os serviços Kinesis Data Stream, Kinesis Data Firehouse, Glue crawler e Glue Jobs são pagos e podem gerar custos!