How to build LLM evaluation framewok - Blog Post (recipe #2) #14500
Conversation
|
The latest updates on your projects. Learn more about Vercel for GitHub.
|


|
Hi @Radu-Raicea! As discussed, here's my first stab at a blog post focused on LLM analytics. Would love your eyes on it when you get a chance. A few things I'm hoping you can help with: Accuracy check — did I misrepresent the product or any features? I'm not an expert here so want to make sure I got it right For context: this is meant to be a high-level tutorial targeting SEO/LLM traffic to drive awareness and visibility, not a deep technical dive. Any and all feedback welcome! |
|
|
||
| After AI: you write code that calls an LLM and... hope. Hope it doesn't hallucinate, go off-brand, or end up screenshotted on Twitter. Except hope is not a strategy for production systems. | ||
|
|
||
| LLMs fail differently than traditional code; bad outputs don't throw errors, they just land on users' plates. It's like serving food you haven't tasted, and hoping you eyeballed the right amount of salt. |
There was a problem hiding this comment.
If you're a chef, you don't really taste it though :D
|
|
||
| This recipe gives you a quality control system. | ||
|
|
||
| 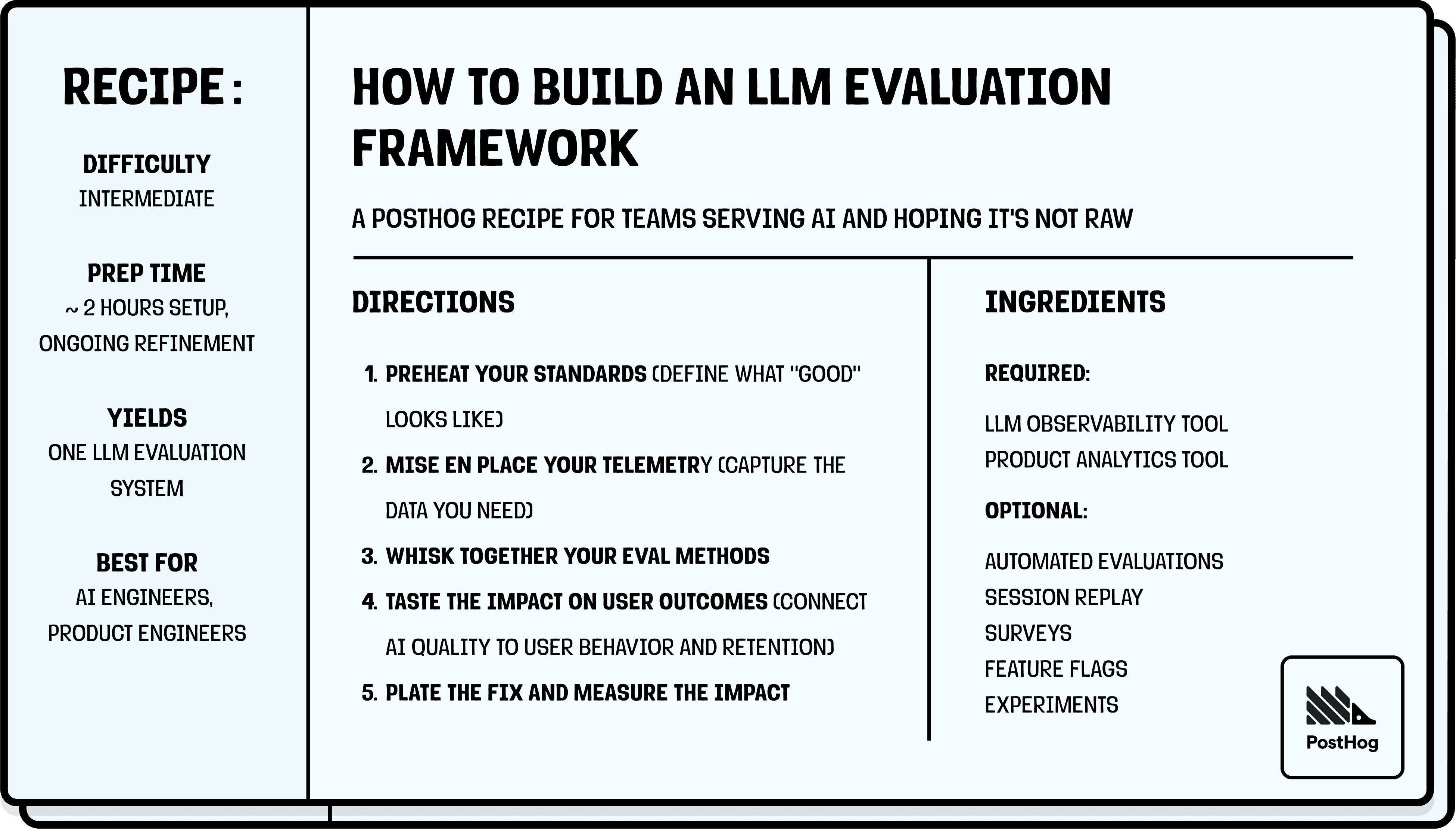 |
There was a problem hiding this comment.
The Y in Telemetry is not bolded
|
|
||
| ### Want to cook with PostHog? Great choice. | ||
|
|
||
| If you haven't set it up yet, [start here](/docs/getting-started/install). For LLM analytics specifically: |
There was a problem hiding this comment.
Should we link the LLMA getting started page here instead?
|
|
||
| If you haven't set it up yet, [start here](/docs/getting-started/install). For LLM analytics specifically: | ||
|
|
||
| 1. Install the [PostHog SDK](/docs/llm-analytics/installation) with your LLM provider wrapper ([OpenAI](/docs/llm-analytics/installation/openai), [Anthropic](/docs/llm-analytics/installation/anthropic), [LangChain](/docs/llm-analytics/installation/langchain), etc.) |
There was a problem hiding this comment.
I would mention the manual capture method too, in case we don't support their framework with a wrapper.
| 2. Make sure you're calling [`posthog.identify()`](/docs/product-analytics/identify) so you can connect AI outputs to specific users | ||
| 3. Your generations will start appearing in [LLM Analytics](https://app.posthog.com/llm-analytics) automatically | ||
|
|
||
| The first **100K** LLM events per month are free with 30-day retention! |
There was a problem hiding this comment.
We could either not mention the retention, or specify that we drop exactly drop the whole LLM event, but rather the input/output messages. We still keep the events for their metadata (cost, number, users associated) past 30 days.
| An LLM evaluation framework is only as good as its data. Every generation should be captured with enough context to debug later. | ||
|
|
||
| Set up your LLM observability so that, at a minimum, it records: | ||
| - **Input** (the user's prompt and any system context) |
There was a problem hiding this comment.
and available tools that the LLM can call
| <details> | ||
| <summary><strong>👨🍳 Chef's tip</strong></summary> | ||
|
|
||
| Capture more than you think you need. Storage is cheap; re-instrumenting later is not. |
There was a problem hiding this comment.
It's more like: backfilling past data that you didn't capture is impossible
There was a problem hiding this comment.
re-instrumenting later is not that bad, but your new "complete" data only starts from that moment, can't rewrite history
|
|
||
| ### Method 1: Automated LLM evaluations | ||
|
|
||
| Automated evaluations use LLM-as-a-judge to score sampled production traffic against your quality criteria. Each evaluation runs automatically on live data and returns a pass/fail result with reasoning, so you know why something failed. |
There was a problem hiding this comment.
Currently we only support LLMaaJ, but we're going to support other evaluators soon.
| <details> | ||
| <summary><strong>👨🍳 Chef's tip</strong></summary> | ||
|
|
||
| Don't over-index on any single method. Automated evals catch issues at scale, user feedback provides ground truth, and manual review keeps everything honest. The value is in how you combine them. |
There was a problem hiding this comment.
Exactly, I was going to mention this.
There was a problem hiding this comment.
PostHog AI have a weekly traces hour doing method 3.
|
|
||
| Everything connects automatically. Filter [session replays](/docs/session-replay) by LLM events or eval results. Build [funnels](/docs/product-analytics/funnels) or [retention](/docs/product-analytics/retention) insights broken down by AI quality metrics. Click from a generation directly to its associated replay. | ||
|
|
||
| Not sure where to start? Ask [PostHog AI](/ai). You can ask questions like "Which users had the most failed evaluations last week?" or "Show me retention for users who got hallucinations vs. those who didn't" – and it'll guide you through building the right insight. |
There was a problem hiding this comment.
Not sure if it works yet through PostHog AI. We haven't specifically built it/tried it. It's coming this quarter though.
There was a problem hiding this comment.
So it's up to you to decide whether to leave it because it will be added towards the end of Q1, or to reword/remove this.
|
|
||
| 1. Go to [Experiments](https://app.posthog.com/experiments) → **New experiment** | ||
| 2. Link it to your feature flag (the one controlling your prompt variant) | ||
| 3. Set your goal metrics — include both eval metrics (pass rate, feedback score) and product metrics (retention, conversion, task completion) |
There was a problem hiding this comment.
This is very rudimentary and we want to improve synergy between products. We don't expect anyone to actually be able to do this easily yet. Perhaps next quarter, we'll have better support with Experiments (especially as we launch Prompt Management).
|
Hey @ivanagas tagging you for review here but not a massive rush on this one, it can wait till next week if you have bigger priorities; also I'll implement all feedback at once (including Radu's) so will wait for your pass before diving in again :) thx! |
Second article in the PostHog recipe series, a step-by-step guide to building an LLM evaluation framework for production AI systems.
Targeting "LLM evaluation framework" (350/mo) as primary keyword, with secondary coverage of
LLM evaluation (1.1k),
LLM evaluation metrics (400),
LLM monitoring (350),
LLM monitoring tools (200),
LLM debugging (150),
LLM evaluation tools (150),
LLM evaluation benchmarks (100),
LLM cost optimization (90),
LLM evaluation methods (90),
best LLM evaluation tools (90),
LLM latency (70)
Supports the Evaluations feature launch and aligns with paid ads push on LLM analytics
Showcases LLM Analytics, Evaluations, Session Replay, Product Analytics, Surveys, Feature Flags, and Experiments as a connected stack
Checklist
vercel.jsonArticle checklist