Lab Assignment 2
1.Nagababu Chilukuri, Class Id-26
2.Nikita Goyal, Class Id-7
3.Ronnie Dean Antwiler II, Class Id-1
This lab Assignment includes the Data Analysis, Data Exploration ,Cleaning of the data , Handling the missing values and predicting some results using various Machine Learning Algorithms. The Natural language process has also been used to understand various text analysis concepts.
The Dataset we used in completing the Lab Assignment was:
- Titantic
- Wine Quality
- Startups Sales and Profit
The main Objective is to understand and learn the various Machine learning Algorithm and NLP concepts using scikit Learn:
- KNN, SVM , Naive bayes Classifier
- K-mean Clustering
- Tokenization, Lemmatization,Trigrams
- Linear and Multiple Regression
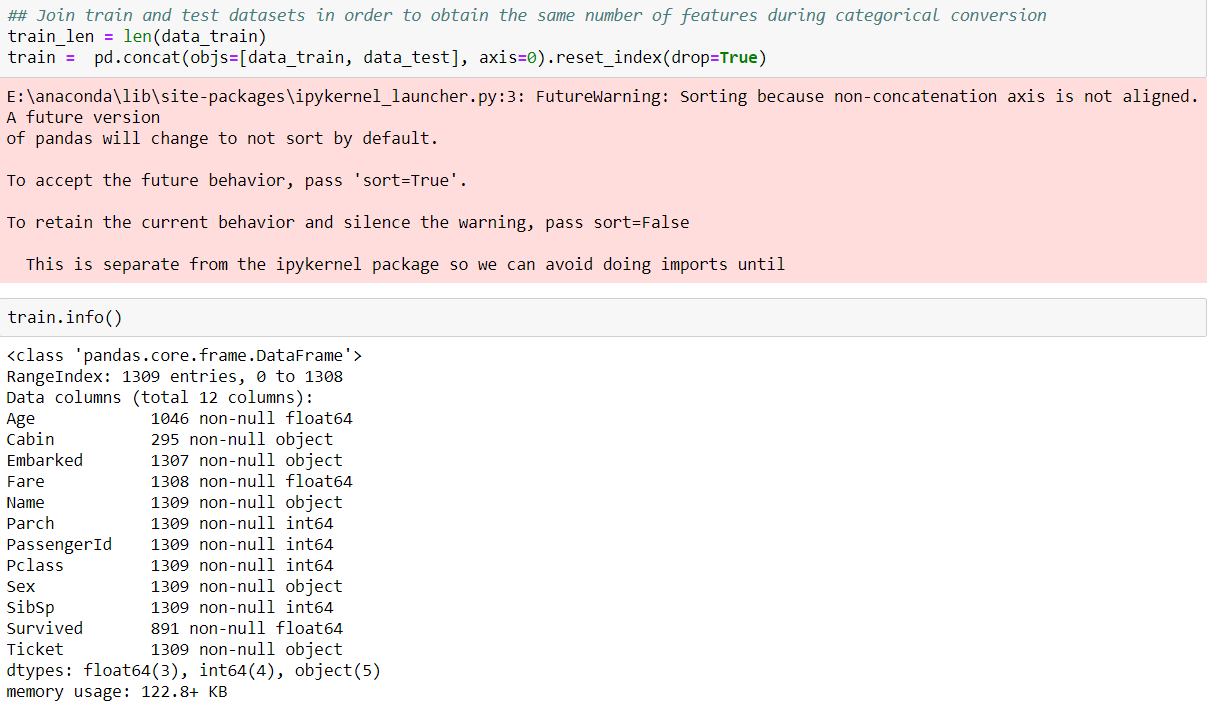
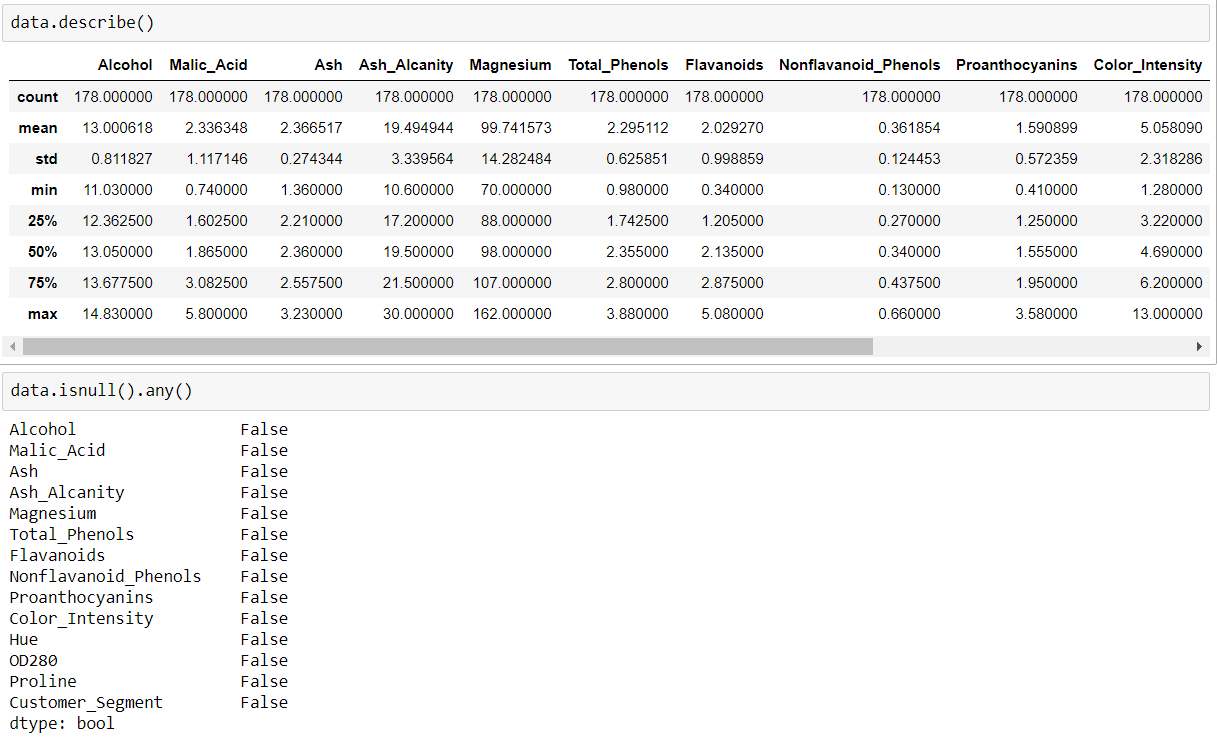
- Pick any dataset from the dataset sheet in the class sheet or online which includes both numeric and non-numeric features
- Perform exploratory data analysis on the data set (like Handling null values, removing the features not correlated to the target class, encoding the categorical features, ...)
- Apply the three classification algorithms Naïve Baye’s, SVM and KNN on the chosen data set and report which classifier gives better result.
Solution:
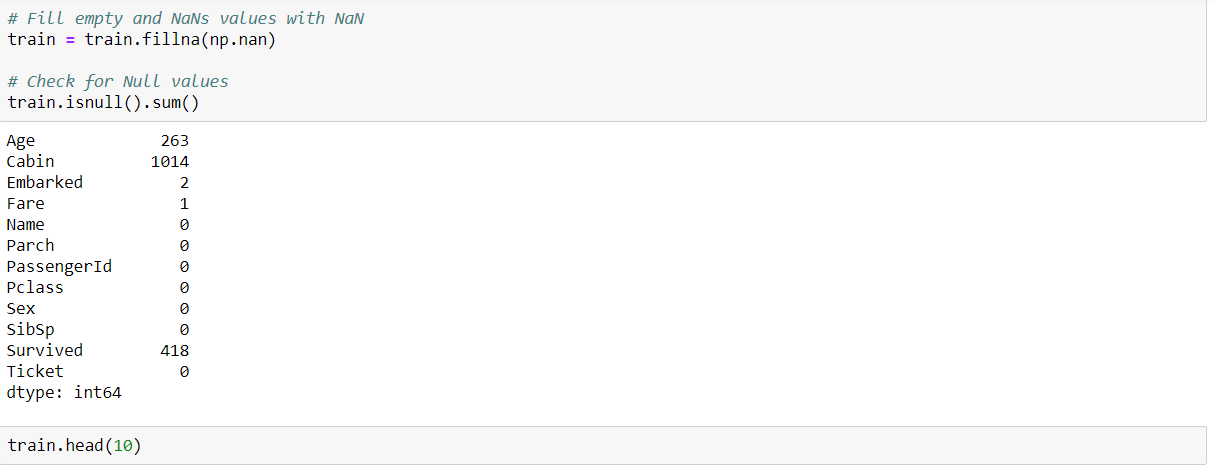
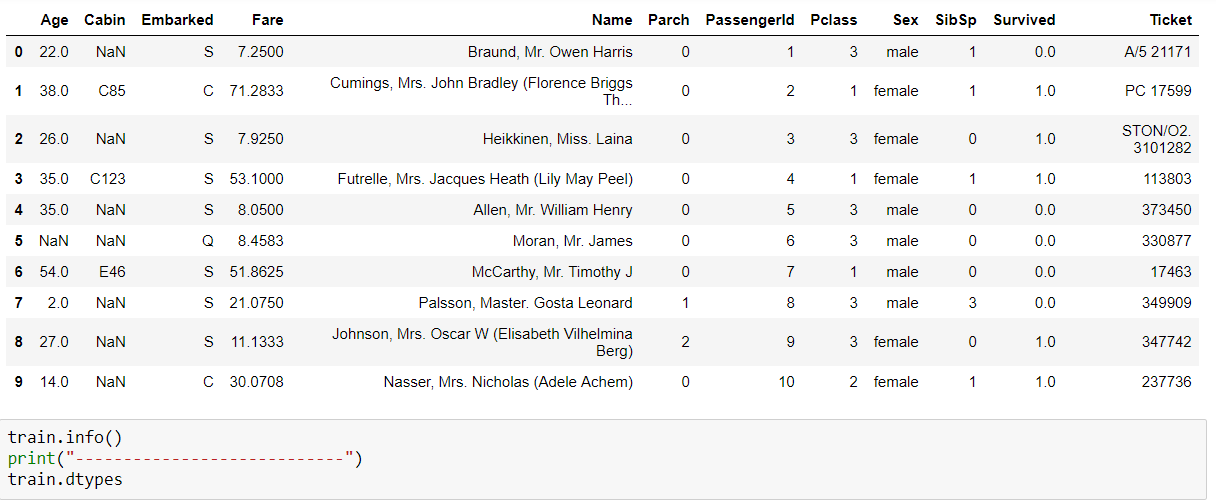
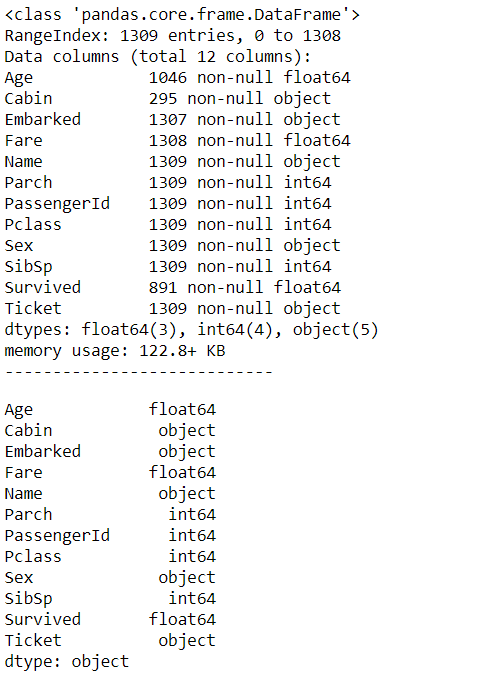
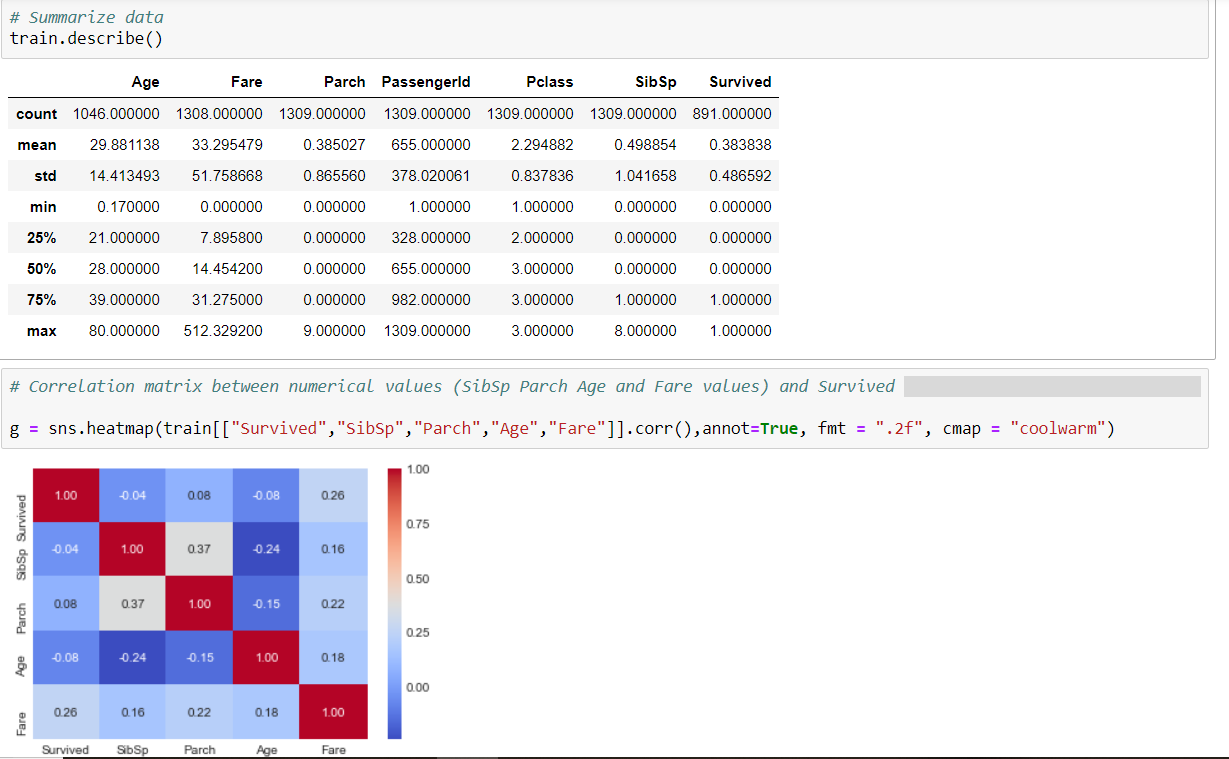
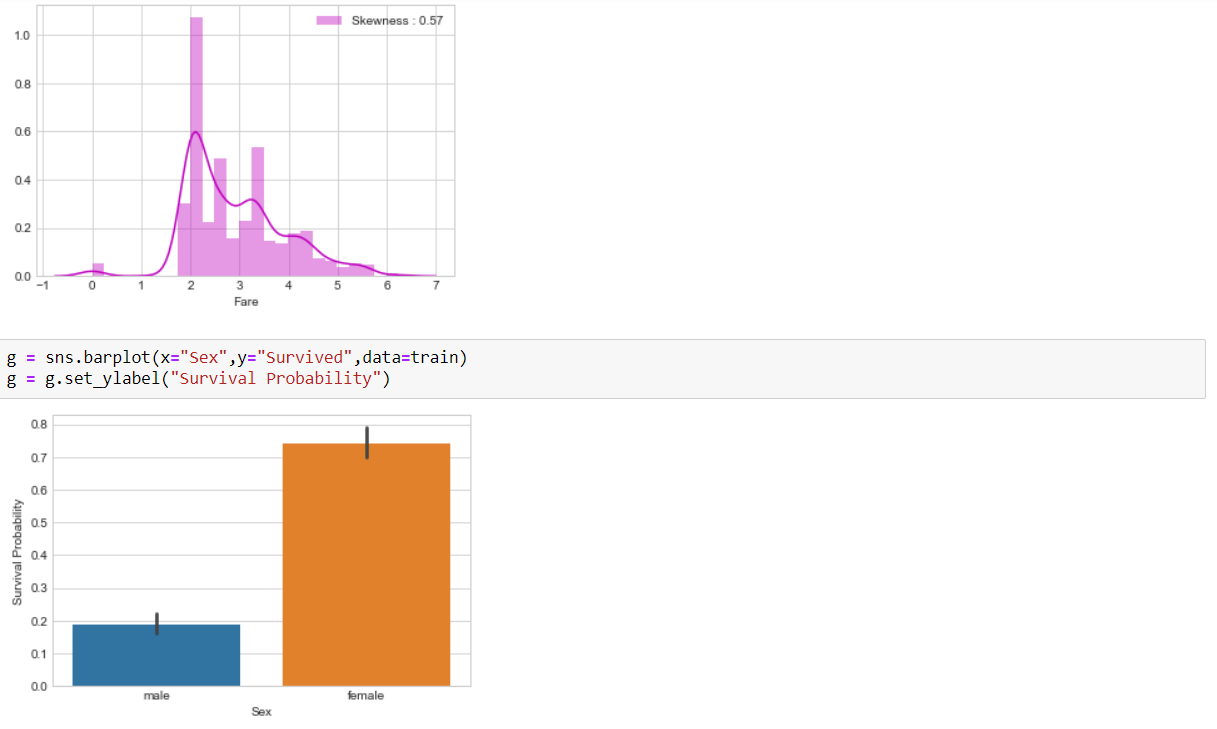
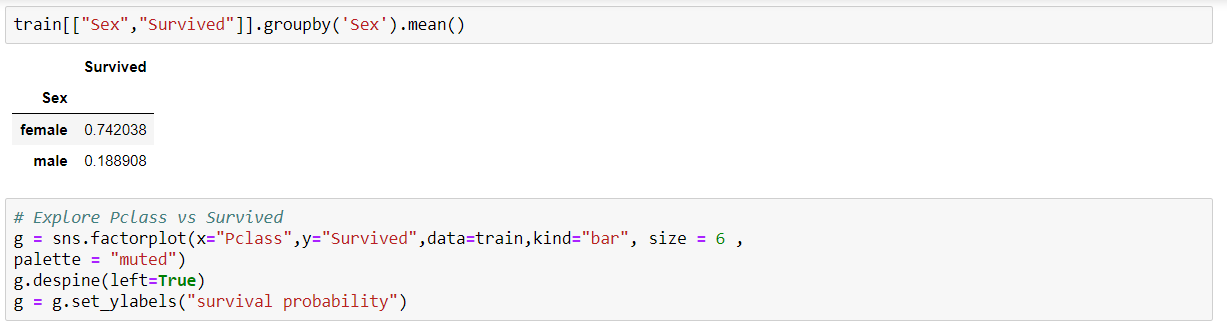
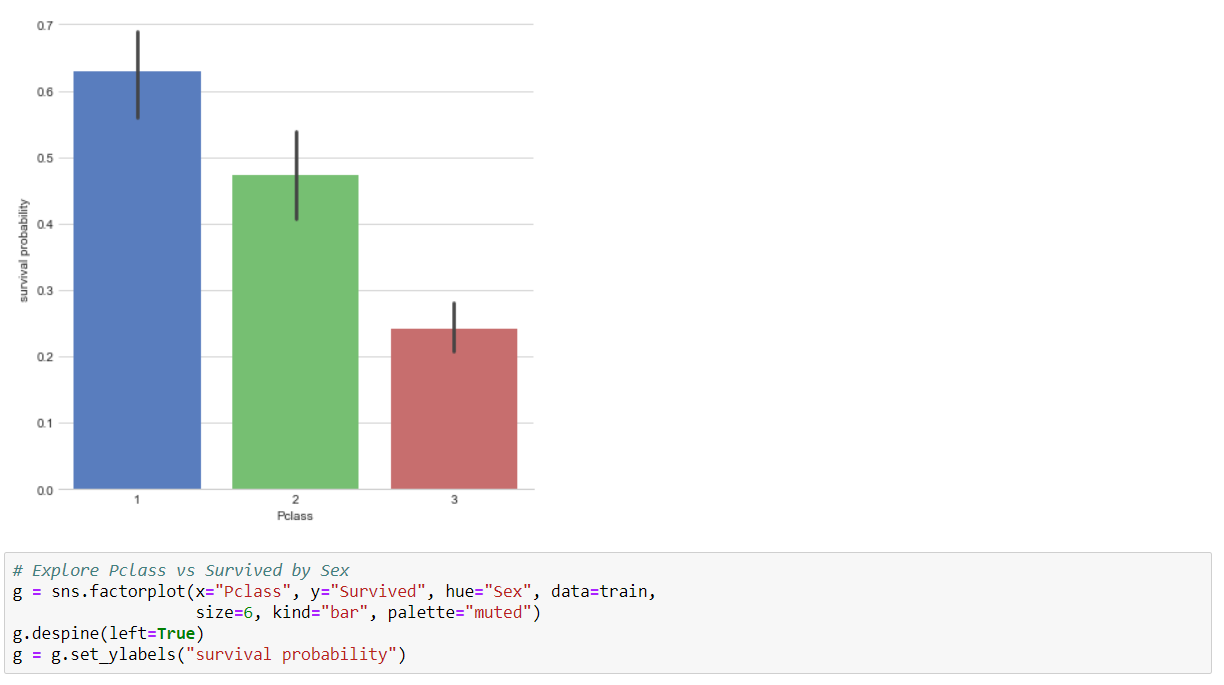
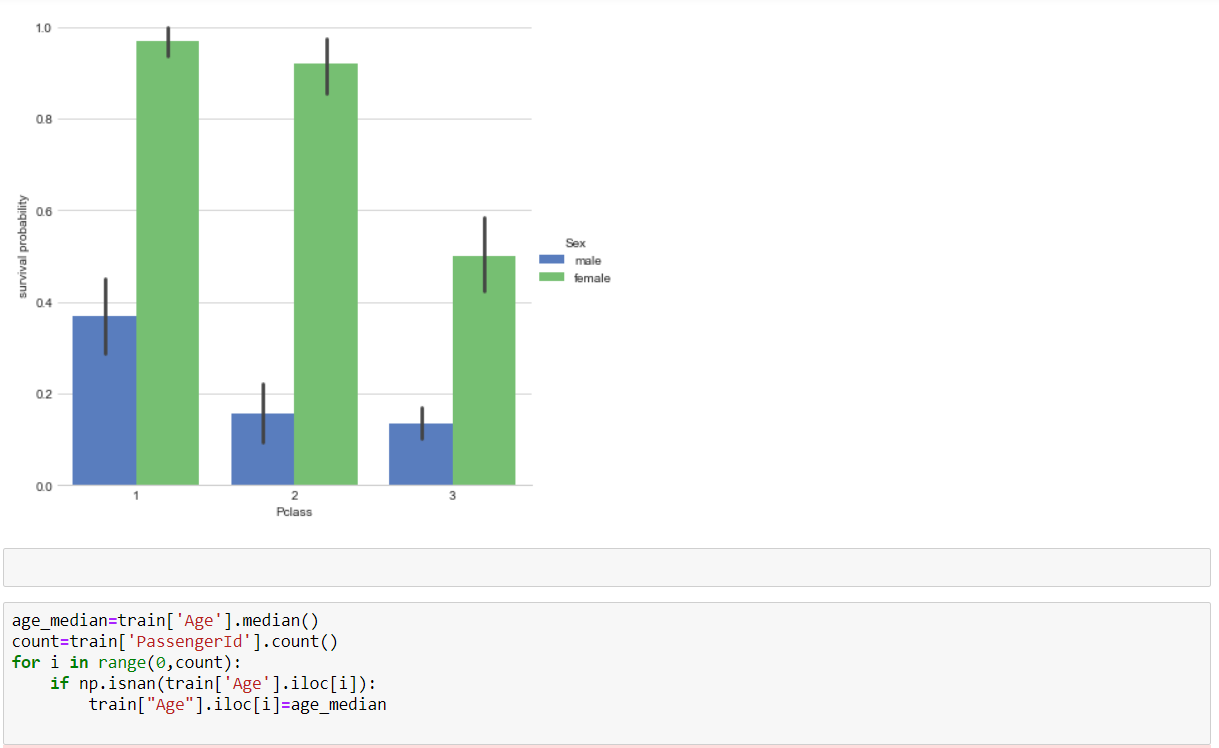
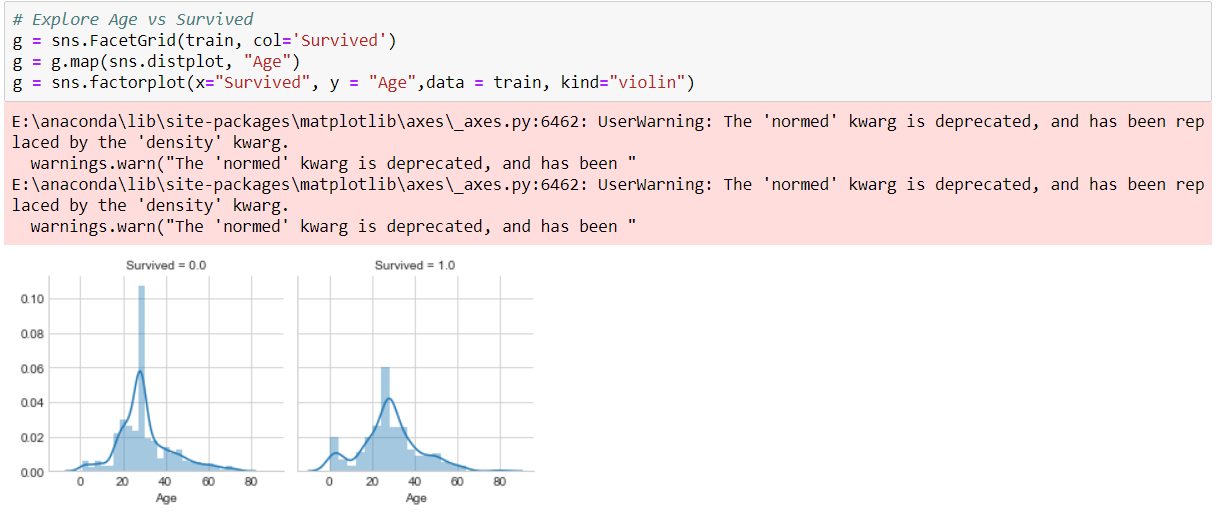
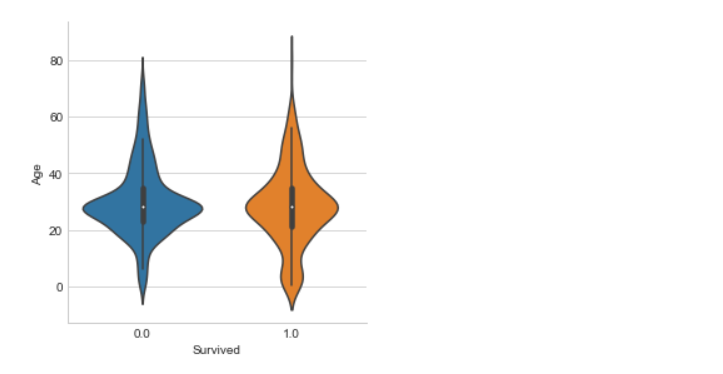
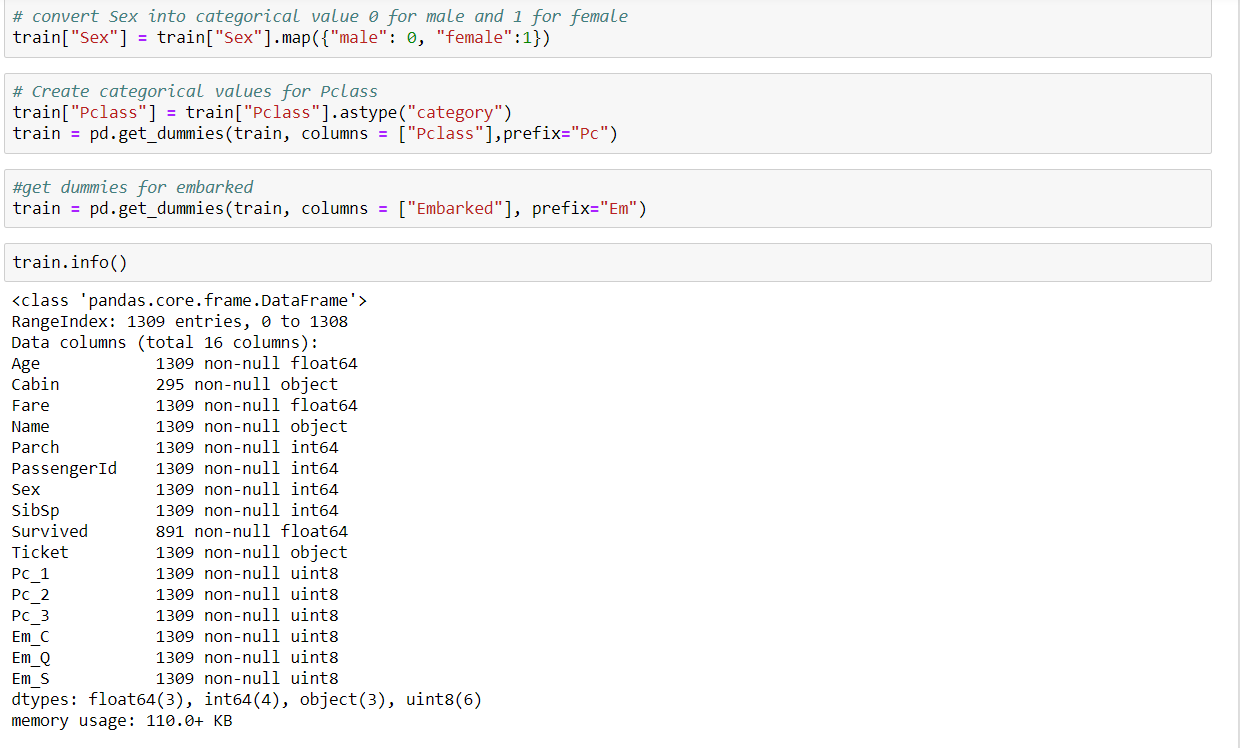
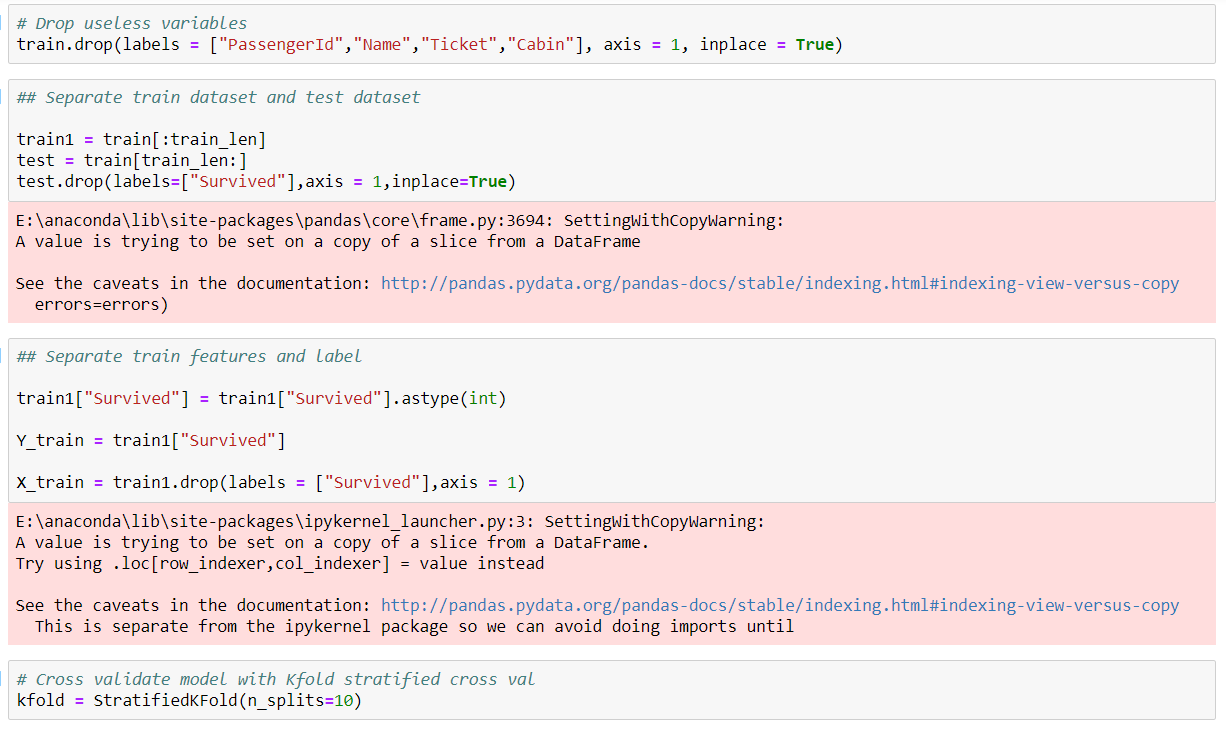
We use three Classifiers that is SVM, Naive Bayes and KNN Classifier to evaluate the model
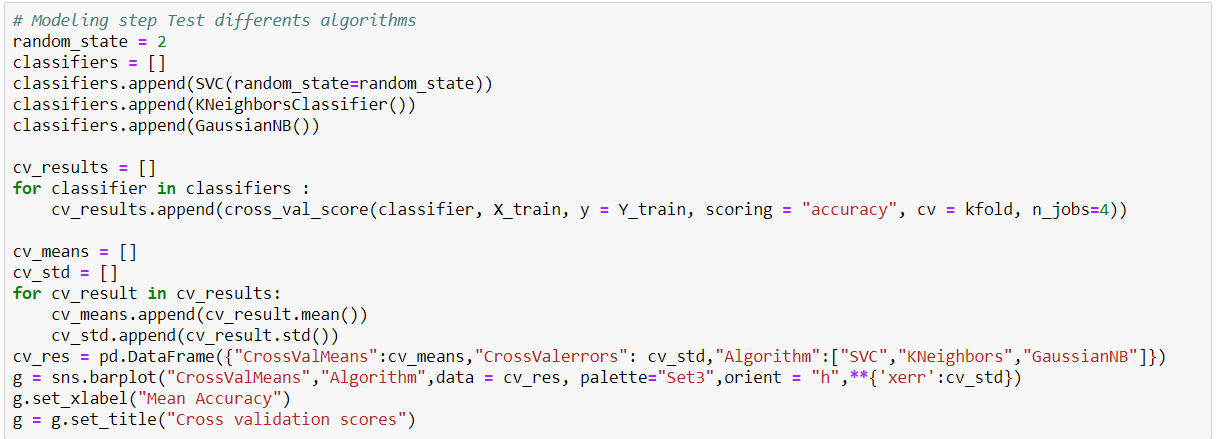
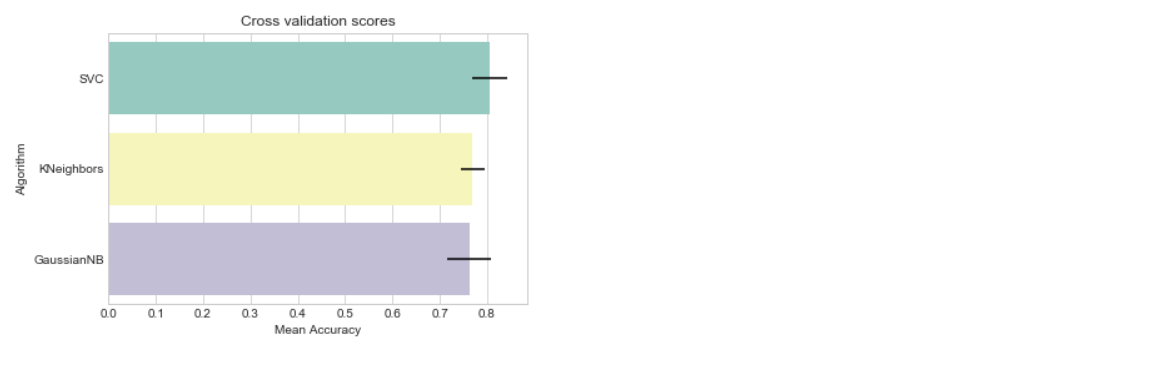
The SVM Classifier gives the highest accuracy score than other two Classifier.
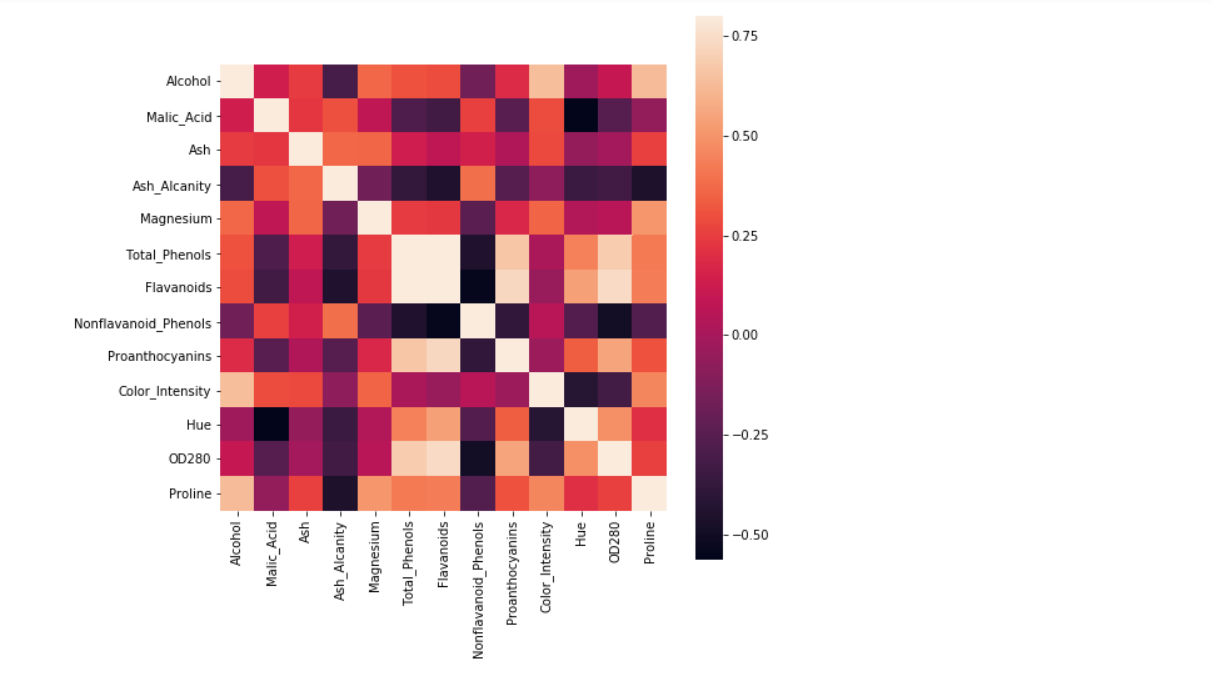
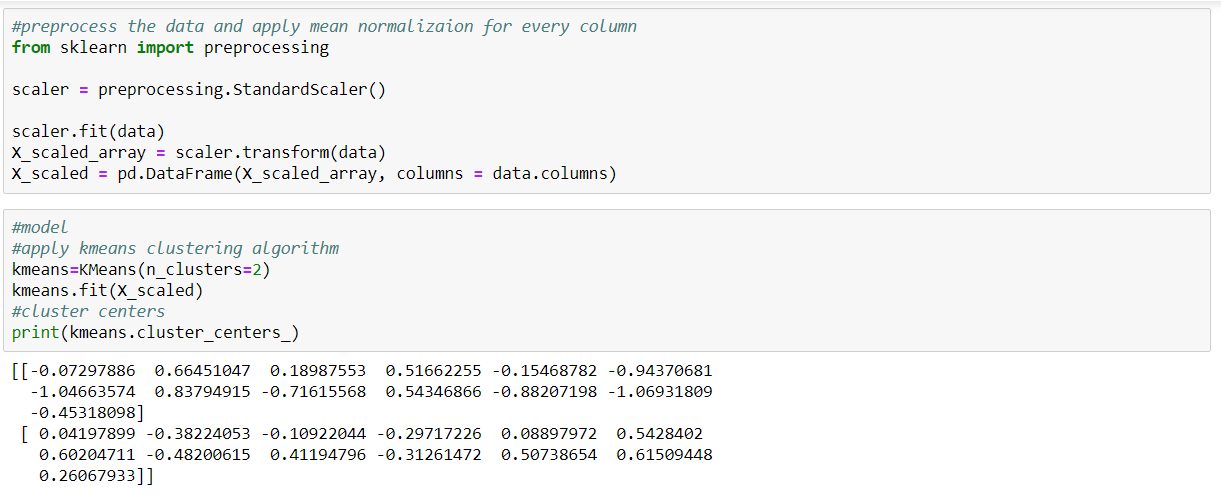
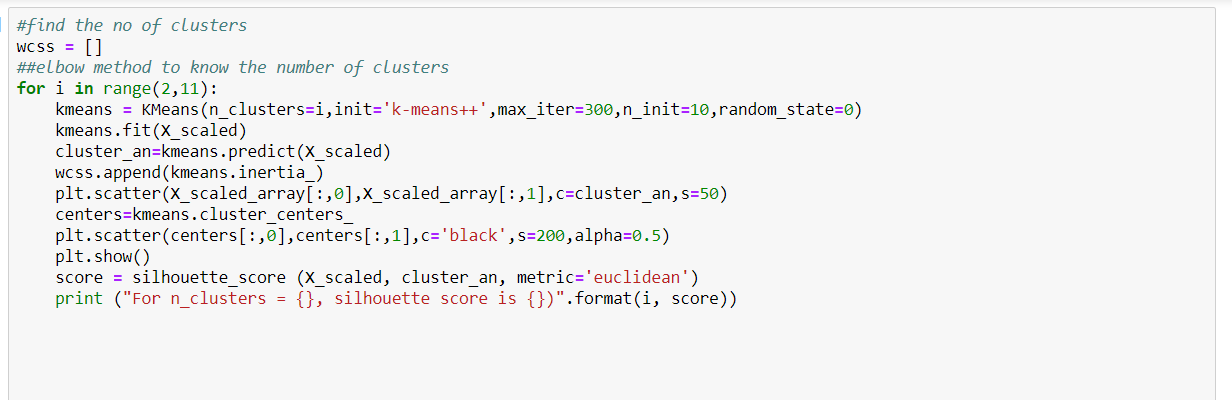
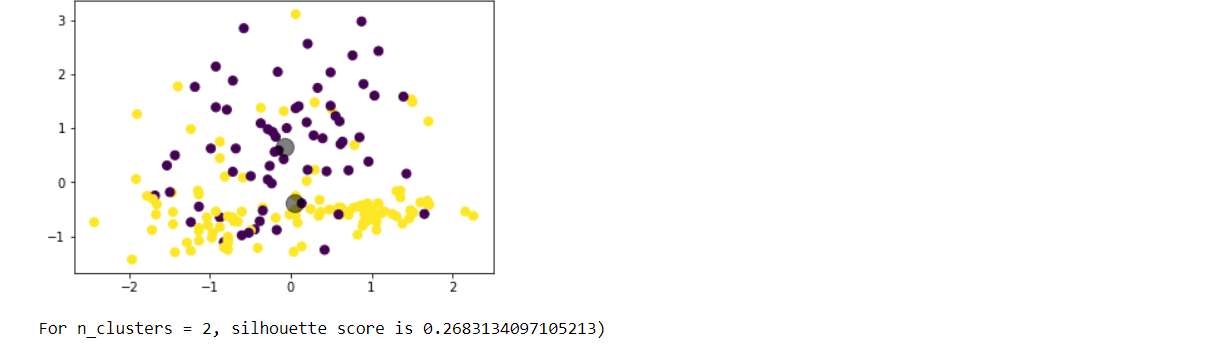
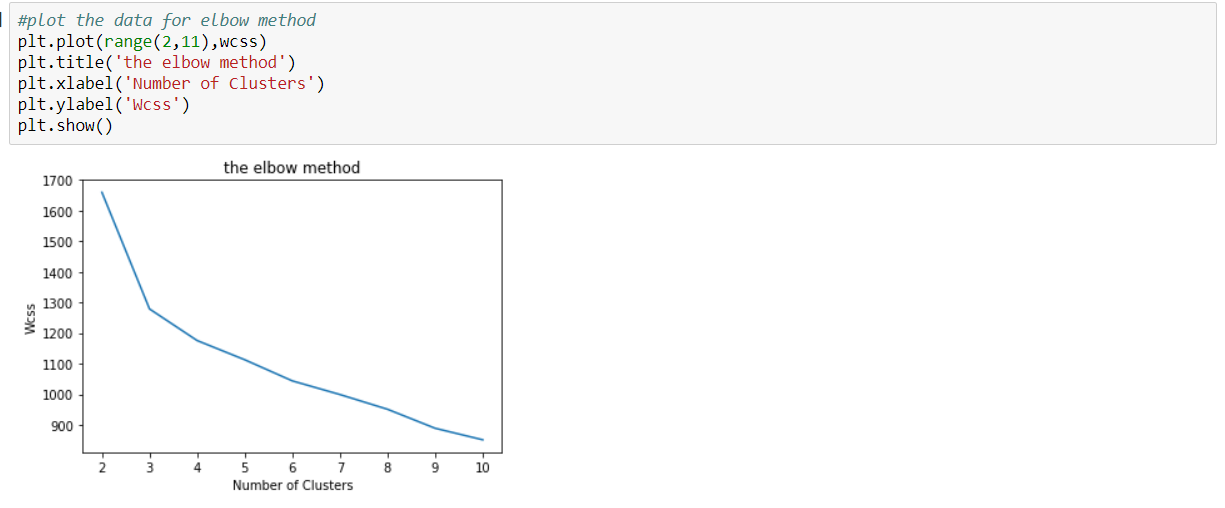
Choose any dataset of your choice. Apply K-means on the dataset and visualize the clusters using matplotlib or seaborn.
- Report which K is the best using the elbow method.
- Evaluate with silhouette score or other scores relevant for unsupervised approaches (before applying clustering clean the data set with the EDA learned in the class)
Solution:

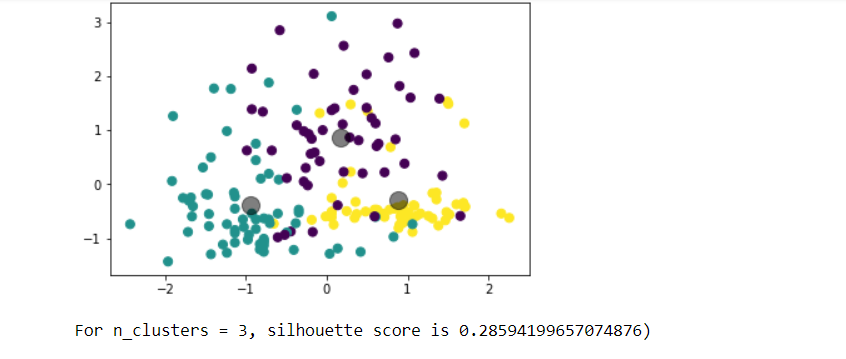
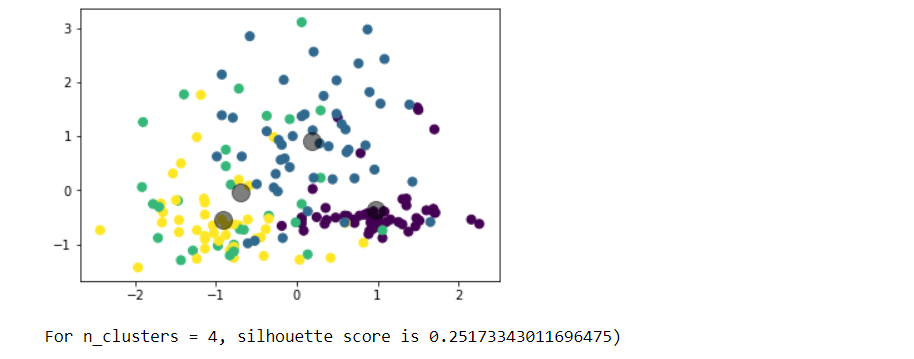
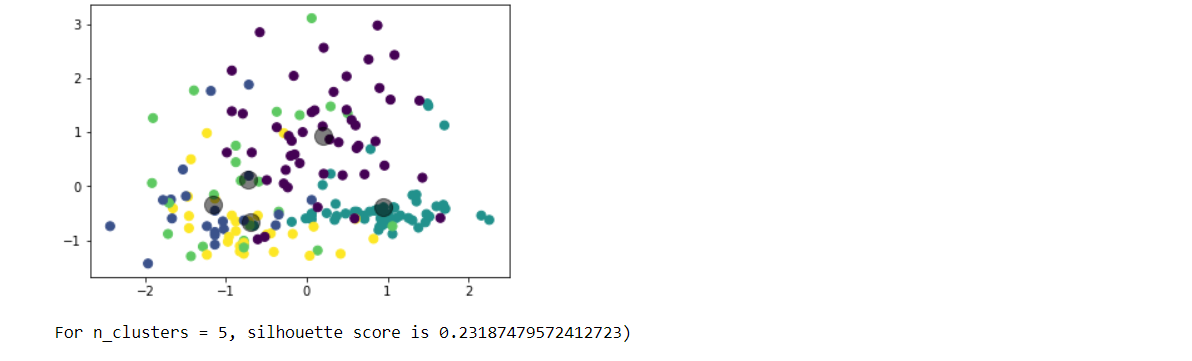
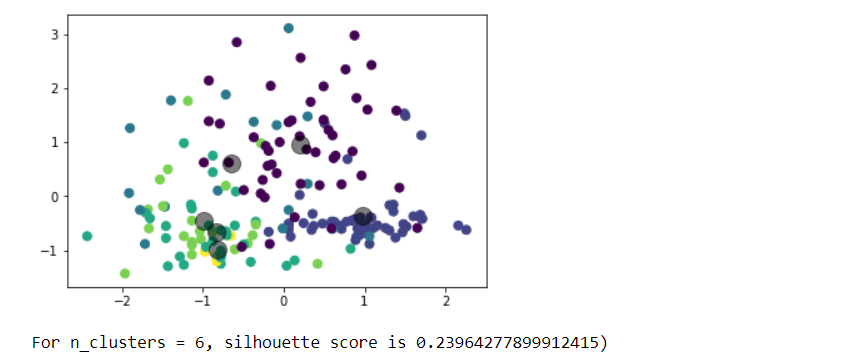
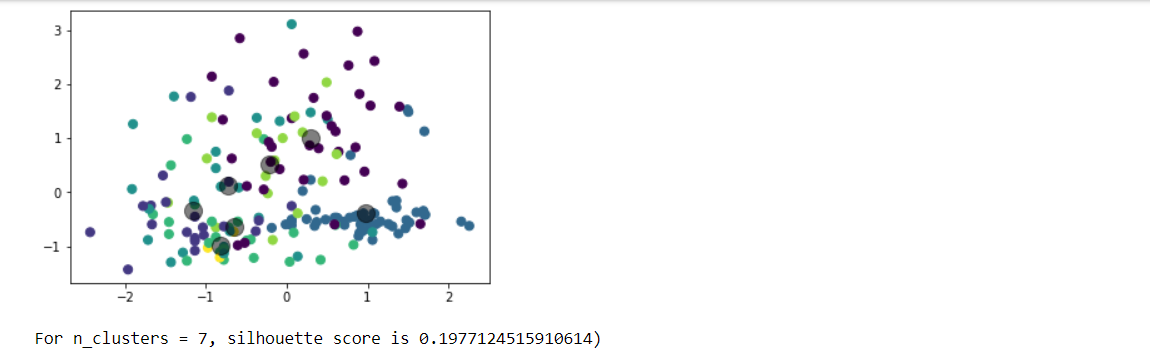
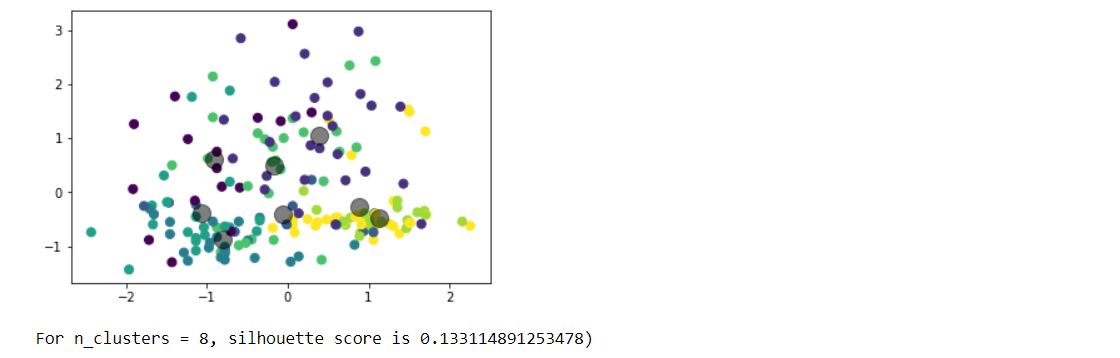
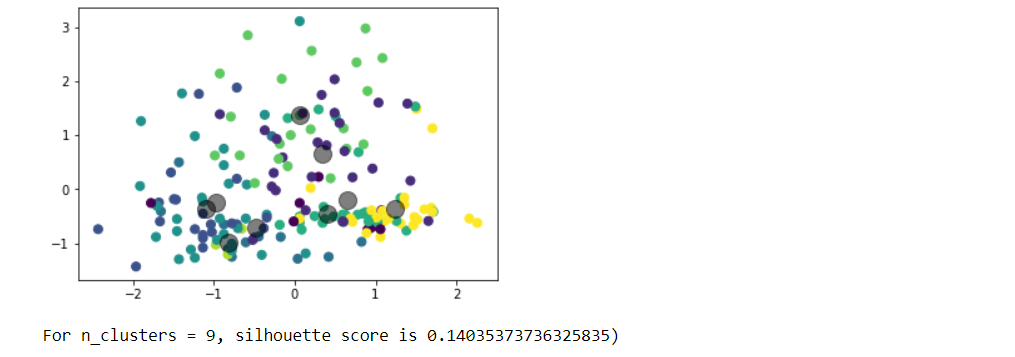
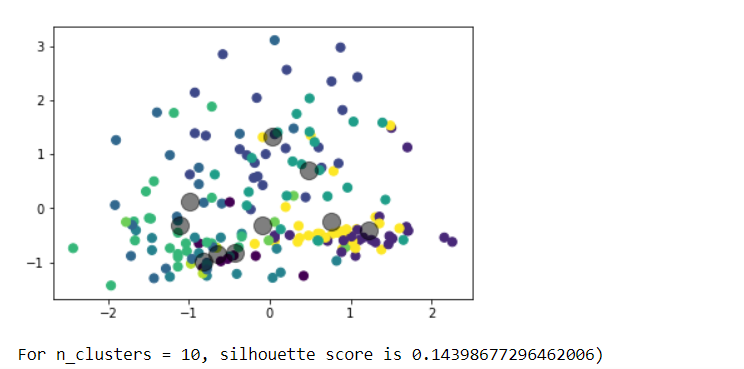
Write a program in which take an Input file, use the simple approach below to summarize a text file:Link to input file: https://umkc.box.com/s/7by0f4540cdbdp3pm60h5fxxffefsvrwa.
- Read the data from a file
- Tokenize the text into words and apply lemmatization technique on each word.
- Find all the trigrams for the words.
- Extract the top 10 of the most repeated trigrams based on their count.
- Go through the text in the file
- Find all the sentences with the most repeated tri-gramsg. Extract those sentences and concatenateh. Print the concatenated result
Solution
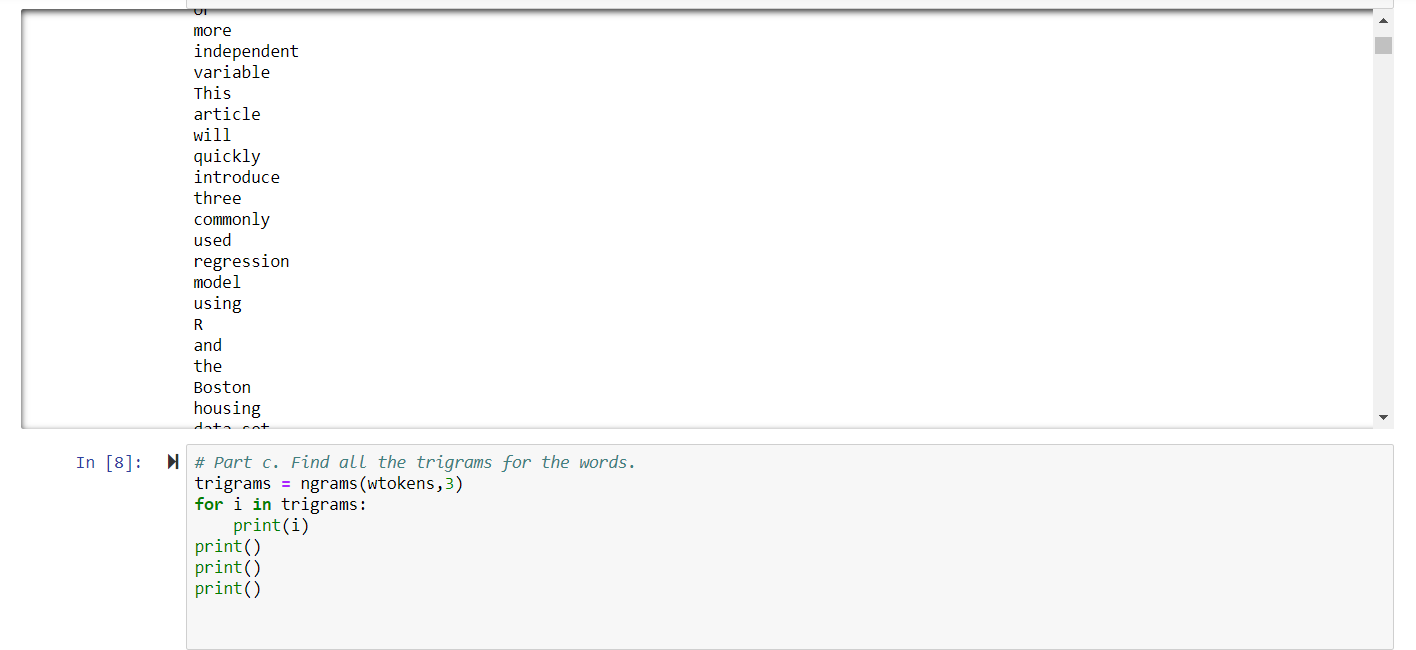
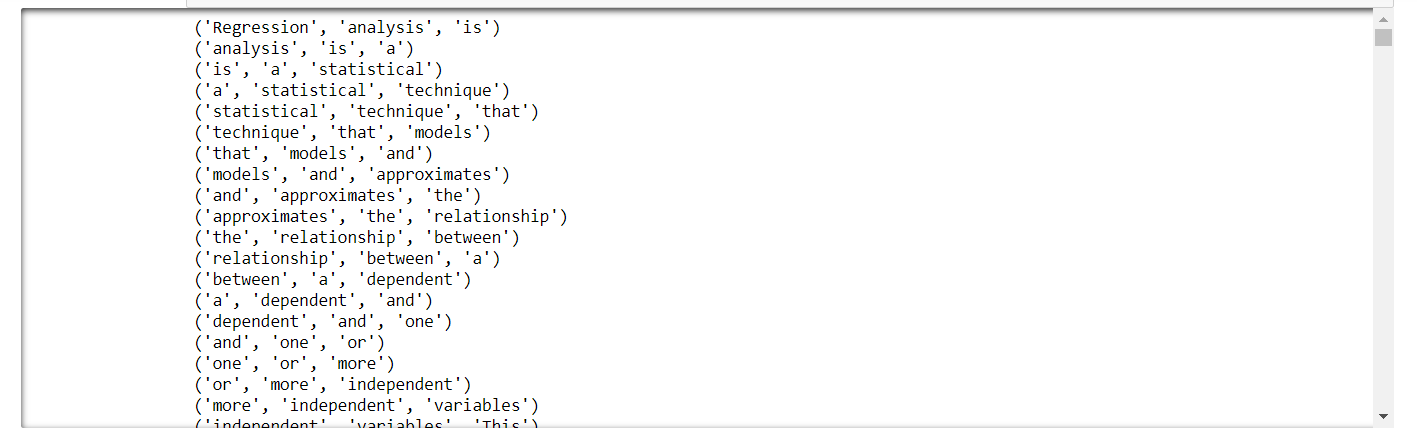
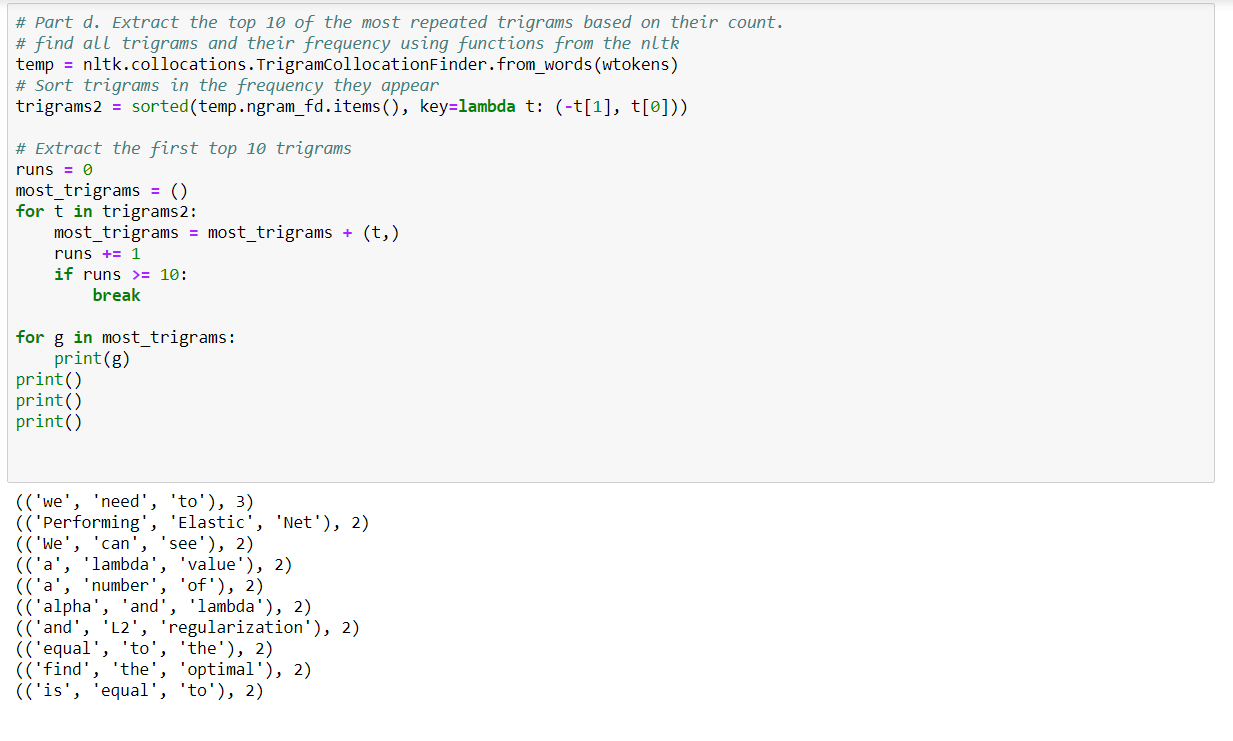

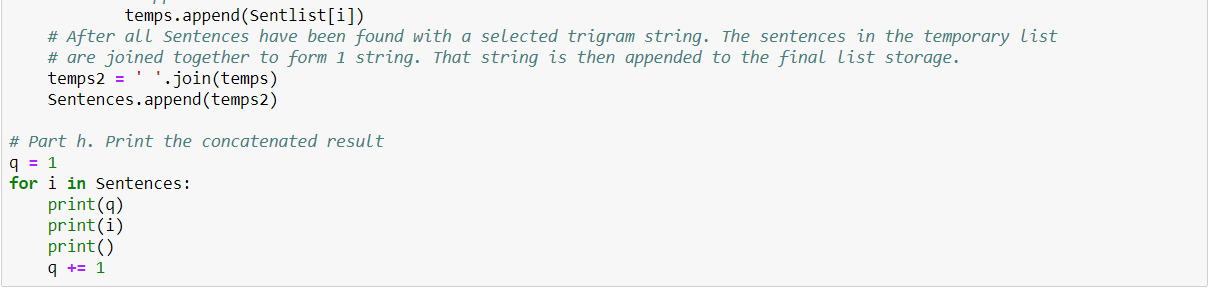
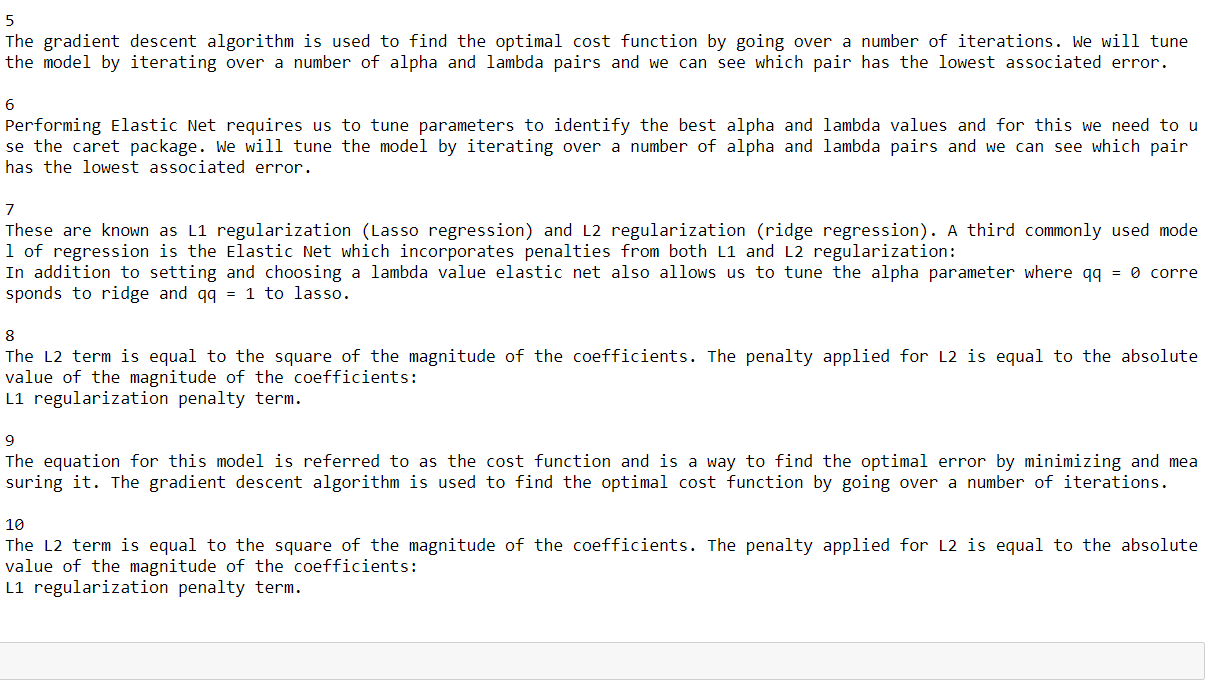
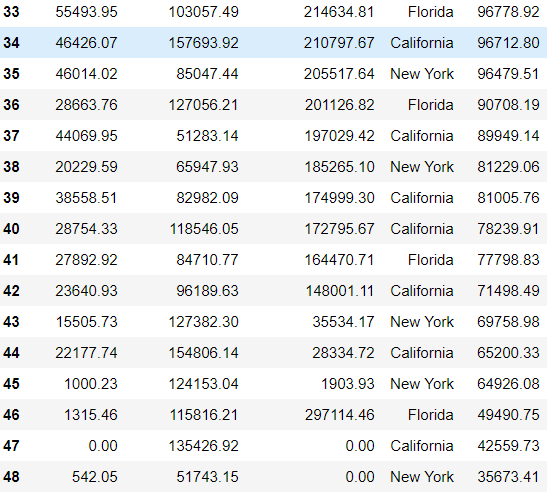
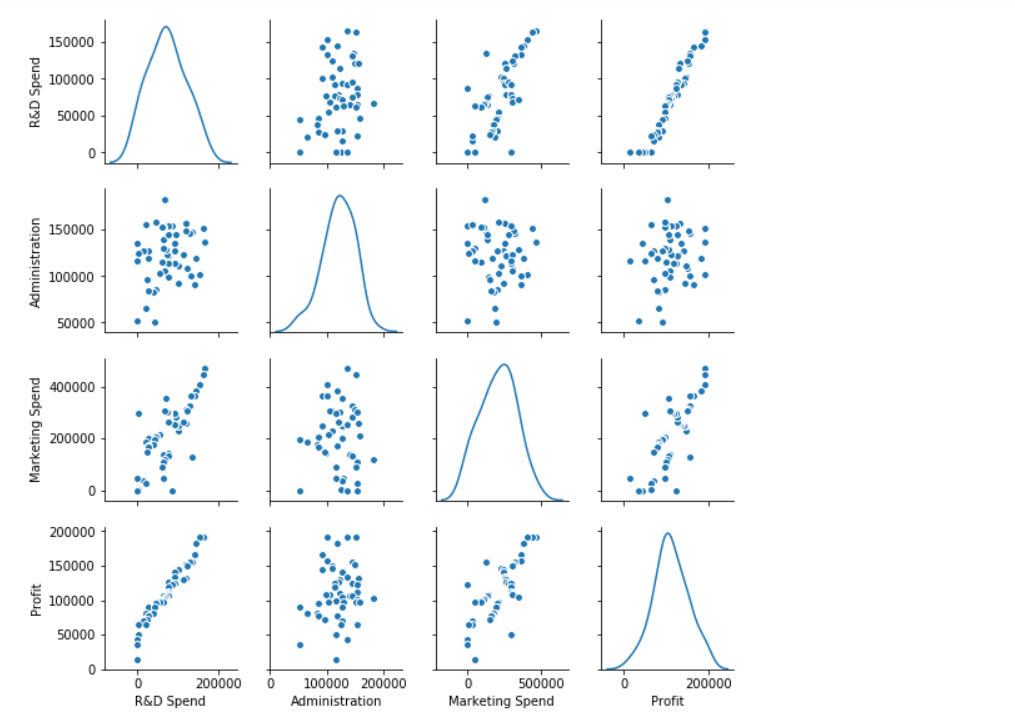
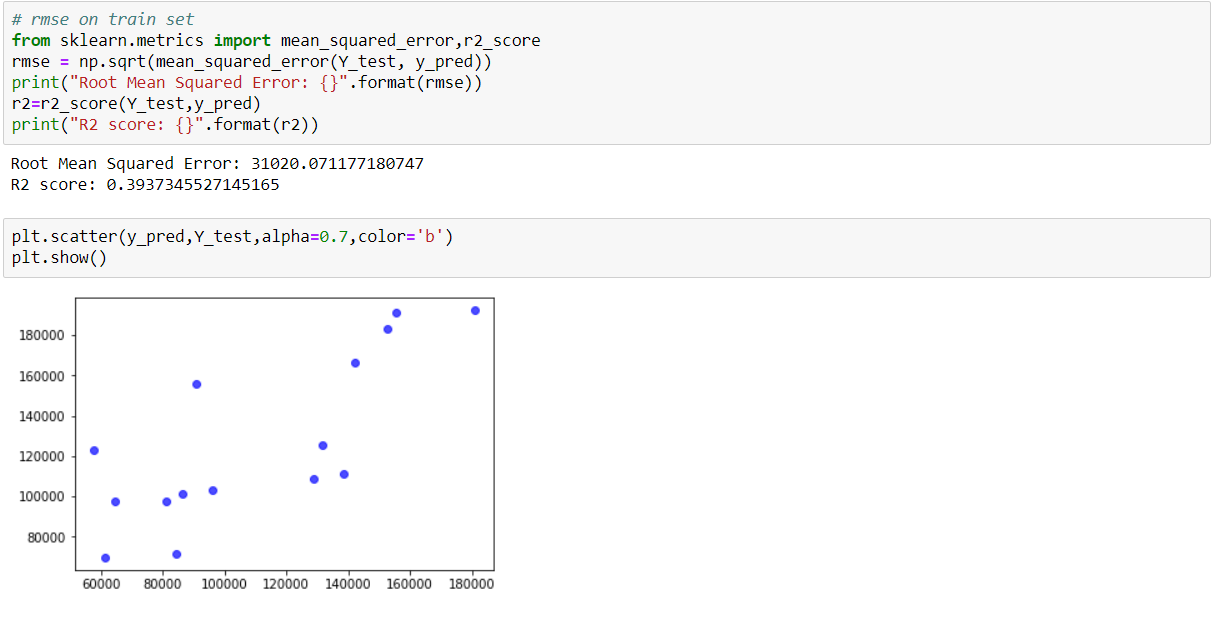
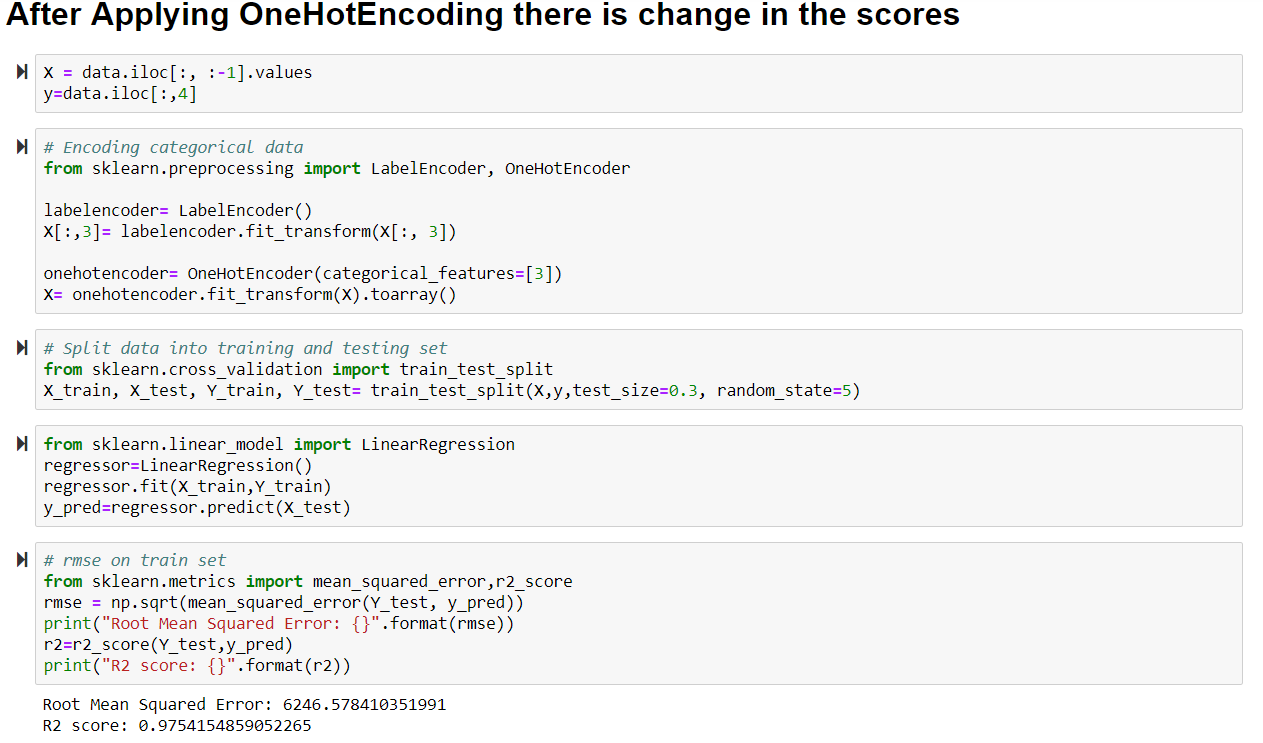
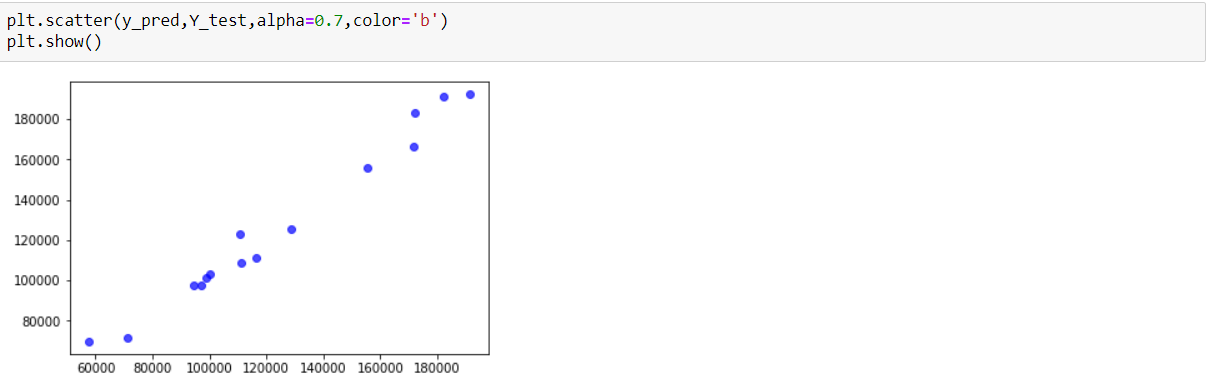
Create Multiple Regression by choosing a dataset of your choice (again before evaluating, clean the data set with the EDA learned in the class). Evaluate the model using RMSE and R2 and also report if you saw any improvement before and after the EDA.
### Solution: