Remove restriction #3
Open
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Author
|
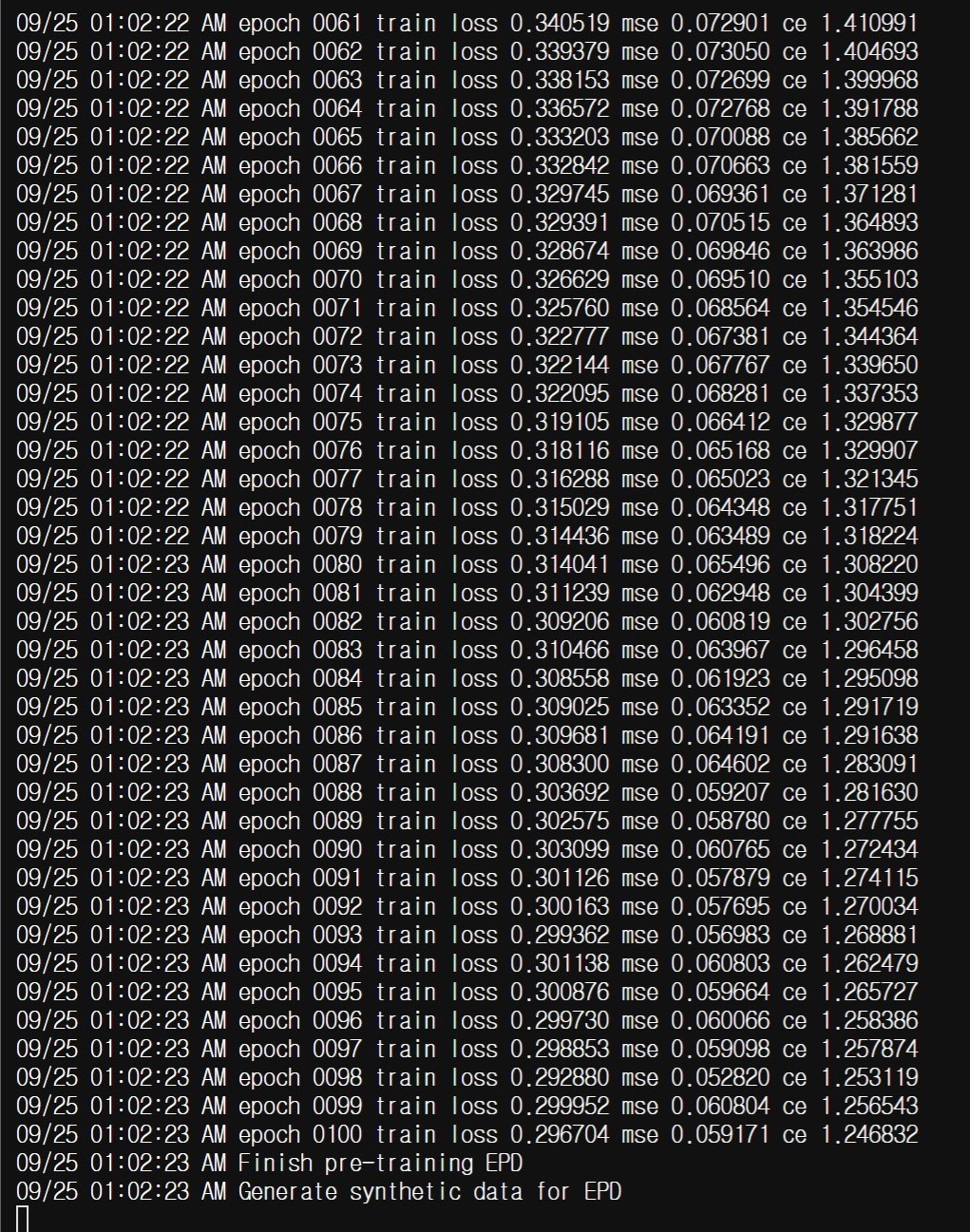
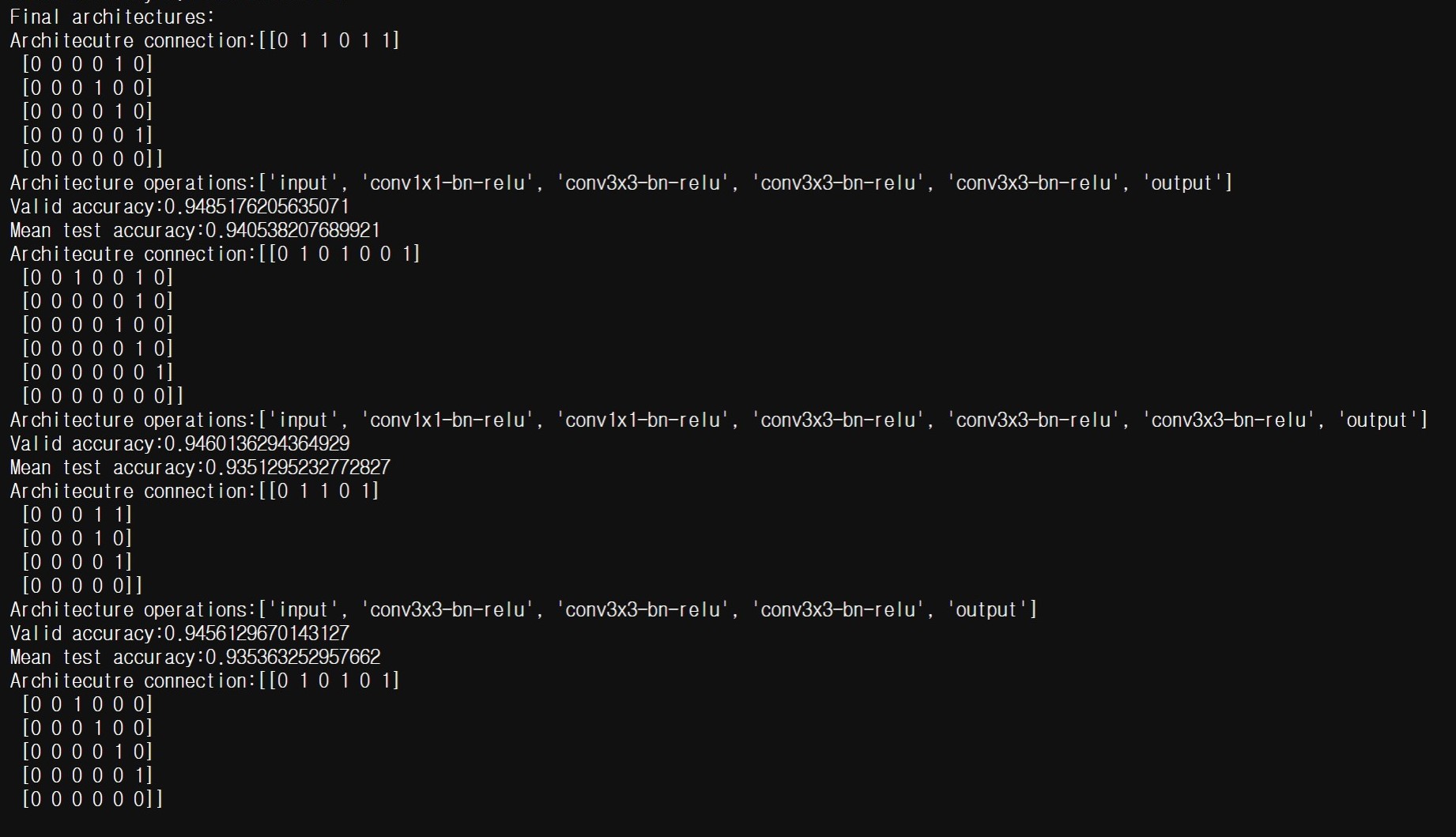
Checked that the loss is reducing. |
juice500ml
requested changes
Sep 26, 2020
 juice500ml
left a comment
juice500ml
left a comment
There was a problem hiding this comment.
Updating this code to self-supervised-nas will take more time. Let's make sure this works!
| mask = torch.zeros(bsz, x.size(1)) | ||
| for i,l in enumerate(x_len): | ||
| for j in range(l): | ||
| mask[i][j] = 1 |
There was a problem hiding this comment.
What about
for i, l in enumerate(x_len):
mask[i, :j] = 1
?
| if len(fixed_stat['module_operations']) < 7: | ||
| continue | ||
| #if len(fixed_stat['module_operations']) < 7: | ||
| # continue |
|
|
||
| def forward(self, x, encoder_hidden=None, encoder_outputs=None): | ||
| def forward(self, x, x_len, encoder_hidden=None, encoder_outputs=None): | ||
| # x is decoder_inputs = [0] + encoder_inputs[:-1] |
| self.offsets.append( (i + 3) * i // 2 - 1) | ||
|
|
||
| def forward(self, x, encoder_hidden=None, encoder_outputs=None): | ||
| def forward(self, x, x_len, encoder_hidden=None, encoder_outputs=None): |
There was a problem hiding this comment.
x_len feels like a somewhat misnomer. If i understood it correctly, it is somewhat like this:
x_len = [len(x) for x in xs]
So, maybe x_len_per_elem? x_len_list? Or at least some comments would be helpful!
| x = (residual + x) * math.sqrt(0.5) | ||
| predicted_softmax = F.log_softmax(self.out(x.view(-1, self.hidden_size)), dim=-1) | ||
| predicted_softmax = predicted_softmax.view(bsz, tgt_len, -1) | ||
| return predicted_softmax, None |
There was a problem hiding this comment.
Is predicted softmax returns sane values? If padded elements are zero-initialized, then probabilty values will be broken.
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Remove restriction of length of seq(=7)
sort seqs by length of seq in one batch.
pack_padded_sequence before rnn : make rnn ignore the inputs outside the length of the seq.
pad_packed_seqeunce after rnn : restore original shape.
pass mask to attention model : Because the length of seqs can be different each other in one batch, use mask to ignore out-of-length.
pack_padded_sequence before rnn : make rnn ignore the inputs outside the length of the seq.
pad_packed_seqeunce after rnn : restore original shape
add 'input_len' (list of length of seqs in one batch) -> pass to the encoder / decoder