Excel import export #157
Excel import export #157
Conversation
Implemented some import-export stuff from Excel. There is now a page where you can download dynamically generated excel files that accompany the rooms, judges, and teams which were imported, along with excel files containing team and speaker statistics so tournaments which don’t follow the standard MIT-TAB ranking can get the data they want. In the upload data form, I’ve added text which tells people what the headers are, so they don’t have to go digging in the manual to find out. The import system has also been reworked so that it overwrites preexisting data rather than simply skipping the entry. This means that changes applied in some excel document can be applied en-masse by importing the changed document.
wrote the df export commands, included pandas to requirements, updated header names to be consistent with csv general practices, swapped everything over to enumerate instead of java-esque arraylist style
over to next(i for i in haystack if i == needle) paradigm instead of explicit for-loops
unclear on whether the query set thing actually works, this is probably a safer way to get what i want, presumably you get a list or other query set from that, and then you get first
it now cleans the scratch type, attempting on string match then on a direct integer match. it also now includes a lot more error checking on whether teams and judges exist. also now based on the column names rather than column order. note that read_excel depends on pandas being present. also, included a fallback if someone uploads a CSV instead of an excel file also -- - started normalisation of my sections of the code for future possible transition to python 3. shouldn't be bad - corrected import error from pandas, requiring xlrd >= 1.0.0, reflected this change in the requirements.txt
stuff doesn't exist anymore anyway
* phone field removed from debaters * magic number set up wrong
tested old system on testing db, got 141454 ms of runtime. new method uses 22032 ms runtime. introduced strut to hold data and perform one conversion now simplifies processing by holding results directly in memory and not in the strange caching system
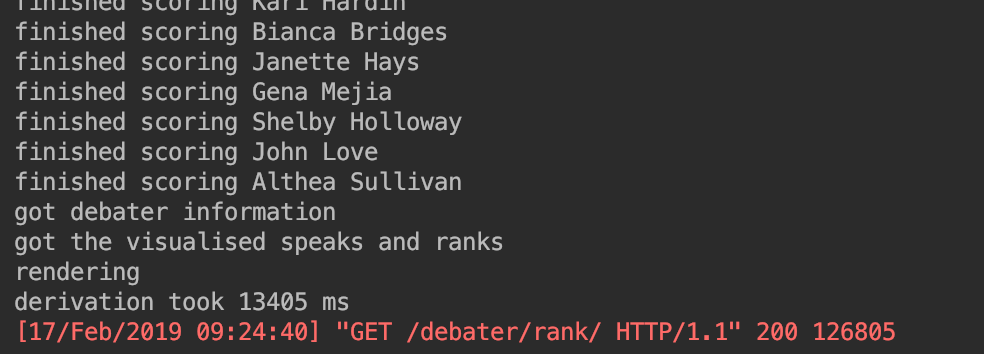
- created private adjustment functions in tab_logic - rewrote the debater score function to stop re-calling data that it already has, and instead perform functions on objects in memory - minor optimisation in `deb_team` to select first rather than the first element of all objects new optimisations reduce debater scoring runtime to 13405 ms
|
There is a reporting error on commit with tag It should have read, taking the retest value on face: That value comes from below:
This error did not occur in reporting of the other figures, although variance in figures is to be expected, and on retest of the method introduced in
And with reports from
I will also note that these numbers may be smaller than what other people get on their machines, as my computer has a fast SSD, greatly speeding IO times. |
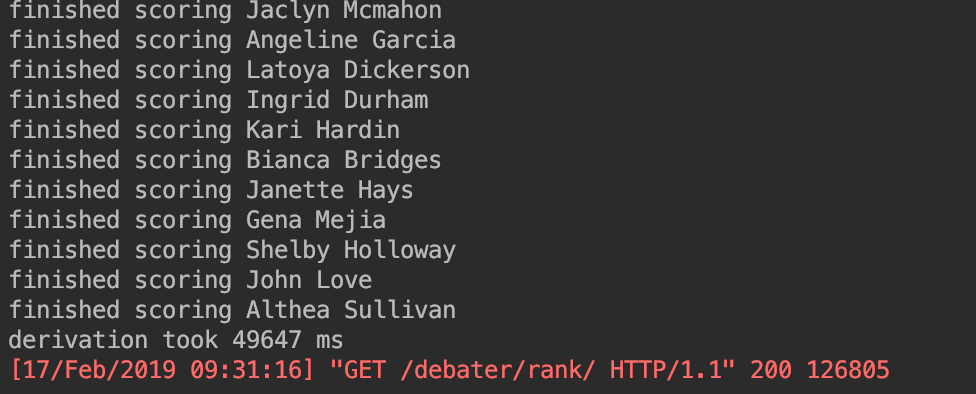
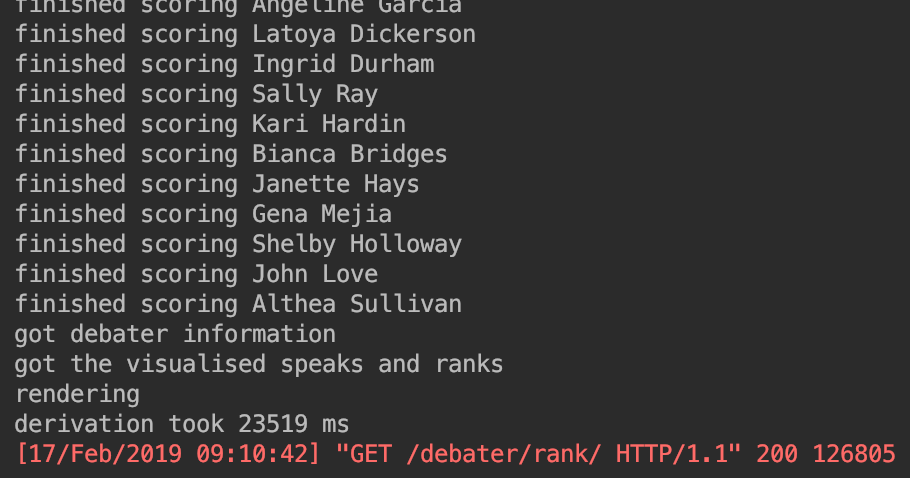
- introduced prefetch for round stats and for the rounds themselves to minimise on the number of database calls - optimised Bye and NoShow calls to use exists rather than Python duck- typing against empty lists - updated some of the debater speaks functions to use the new private internal adjustment functions - changed some uses of `range` to `xrange` since this is better in py2 new optimisations reduce debater scoring runtime to 10730 ms
unifying some of these speaker/rank calculations because they duplicate each other a lot
round calls are no longer made. shaved debater scoring runtime to 10128 ms
the number of repeated calls based on that struct introduced some basic prefetching to the `get_team_scores` call to help speed load times. changes reduced team rank load time from 40829 ms to 15539 ms. also fix for some bugs that were accidentally introduced to the team portion of the tab logic code when changing the debater side. my apologies.
around and screwed it up. this should fix that
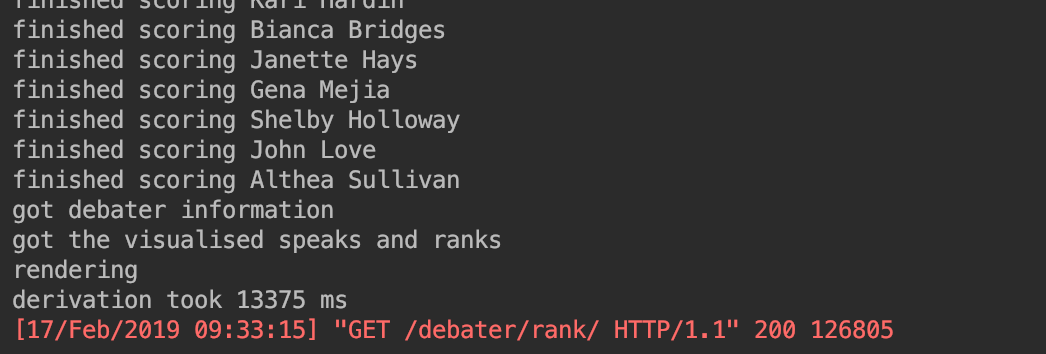
reduce the number of calls by saving the speaks and ranks and then adjusting them after the fact speaks and rank calculations for both are centred around two private methods which create, flatten, and sort lists of speaks or ranks reduced team scoreing time to 11647 ms
the teams speaks and ranks calculations. since the list itself is now cached and sums are cheap, this isn't a problem. corrected oversight in that sums were not provided in some sections
also corrected a summing oversight in the debaters code which i no longer use
that they work one failed, due to oversight of actually calling the function
more than a second off the load time, at least on my computer: load time falls from 6454 ms to 5093 ms in doing so, also rewrote the num_opps and num_govs in tab logic to use gov team related keys, which can be prefetched, rather than filtering from all round objects.
|
Super late here because I just noticed the changes to this PR -- just as a heads up, you may have to resolve some conflicts due to python3 upgrade being merged. Also, this PR size is pretty large, making it difficult for me to review thoroughly and be confident in approving it. Would you be willing to break it up into smaller tasks? I think a potentially good structure is:
|
| # single_adjusted_ranks_deb(debater), | ||
| # -double_adjusted_speaks_deb(debater), | ||
| # double_adjusted_ranks_deb(debater)) | ||
| self.speaker = s |
There was a problem hiding this comment.
Really love this approach, I'm thinking of doing a larger tab logic refactor FYI so I may include this there (and try to do some git-fu to make sure you're credited for the contribution)
| # tab_logic.tot_ranks_deb(s), | ||
| # tab_logic.deb_team(s)) for s in nov_speakers] | ||
|
|
||
| debater_scores = tab_logic.get_debater_scores() |
There was a problem hiding this comment.
Where is this function defined?
There was a problem hiding this comment.
tab_logic.py
def get_debater_scores():
return [DebaterScores(d, debater_score(d)) for d in
Debater.objects.prefetch_related('roundstats_set', 'roundstats_set__round', 'team_set',
'team_set__bye_set', 'team_set__noshow_set').all()]
# prefetch roundstats to save on ORM time
| try: | ||
| return d.team_set.all()[0] | ||
| except: | ||
| return d.team_set.first() |
There was a problem hiding this comment.
Interestingly, I'm finding that changing from all()[0] to first() actually makes things noticeably slower (adds about 1 second). Maybe it's because nobody is every really on more than 1 team, and first() adds some more sql logic that makes the query slower than getting all of them?
There was a problem hiding this comment.
Analytically, I would imagine that wouldn't be the case, since the former should produce an SQL query with more runtime than the latter. But empirics don't lie. Thinking about how that could be the case, perhaps it has to do with caching or prefetch changes?
|
|
||
| # SECURITY WARNING: don't run with debug turned on in production! | ||
| DEBUG = os.environ.get('DEBUG') | ||
| DEBUG = True |
b9653d1 to
29c52e5
Compare
Implemented some import-export stuff from Excel. There is now a page where you can download dynamically generated excel files that accompany the rooms, judges, and teams which were imported, along with excel files containing team and speaker statistics so tournaments which don’t follow the standard MIT-TAB ranking can get the data they want.
In the upload data form, I’ve added text which tells people what the headers are, so they don’t have to go digging in the manual to find out.
The import system, unlike in the previous version, does not overwrite preexisting data (though the functionality has been kept by a keyword).
I've tried to keep changes outside this to a minimum, but adding it to the level that one can actually access it via the web interface means digging through the template files. The main changes are the
import_xfiles, which I rewrote; theexport_xls_fileswhich I wrote; and the template changes.I also changed one thing in the tab logic to unify one of the uncached Round calls, but that was done semi-accidentally.
The way the template change is structured is that it primarily just goes to a view unconnected with the other ones. I think that is easier for you to check. It could trivially be put back into the main files.