
An open-source AI tool for auditing research papers with formal or quantitative models. Arbiter extracts claims, attempts machine verification of encodable mathematical claims using Z3/Knuckledragger, and stages structured multi-agent debates to expose the gap between what a paper proves and what it claims.
Works best on papers with explicit formal models — economics, theoretical CS, mechanism design, quantitative social science, optimization. Claim extraction and formalization are LLM-driven (untrusted heuristics); proof certificates are machine-checked (trusted). See trust model below.
Point Arbiter at a PDF — it extracts claims, finds contradictions, generates Z3/Knuckledragger proof certificates for encodable claims, designs specialist debate agents across multiple LLM providers (OpenAI, Anthropic, Google, Grok), and produces a structured verdict with every argument tracked.
Benchmark: 89.3% checker-passing on miniF2F (Claude Sonnet 4.5), but full audit of all 202 proved results finds only 16.3% genuinely valid (33/202 proved, 13.5% of all 244 problems). The 74.3% invalid rate includes 38.1% vacuous proofs and 14.4% trivial tails. The gap between checker-passing and genuinely-valid is the core finding of our audit paper. See benchmark paper for full taxonomy.
- Reads the paper — extracts every claim, assumption, proposition, and equation
- Finds the cracks — identifies contradictions, tensions, and Z3-encodable formal claims
- Designs the debate — creates specialist agents (e.g., Macroeconomist, TaxScholar, IO Theorist), gate rules, and a custom rubric
- Runs the debate — multi-round argumentation with real-time validity enforcement
- Delivers a verdict — multi-provider judge panel with scores, landed hits, and a structured argument map
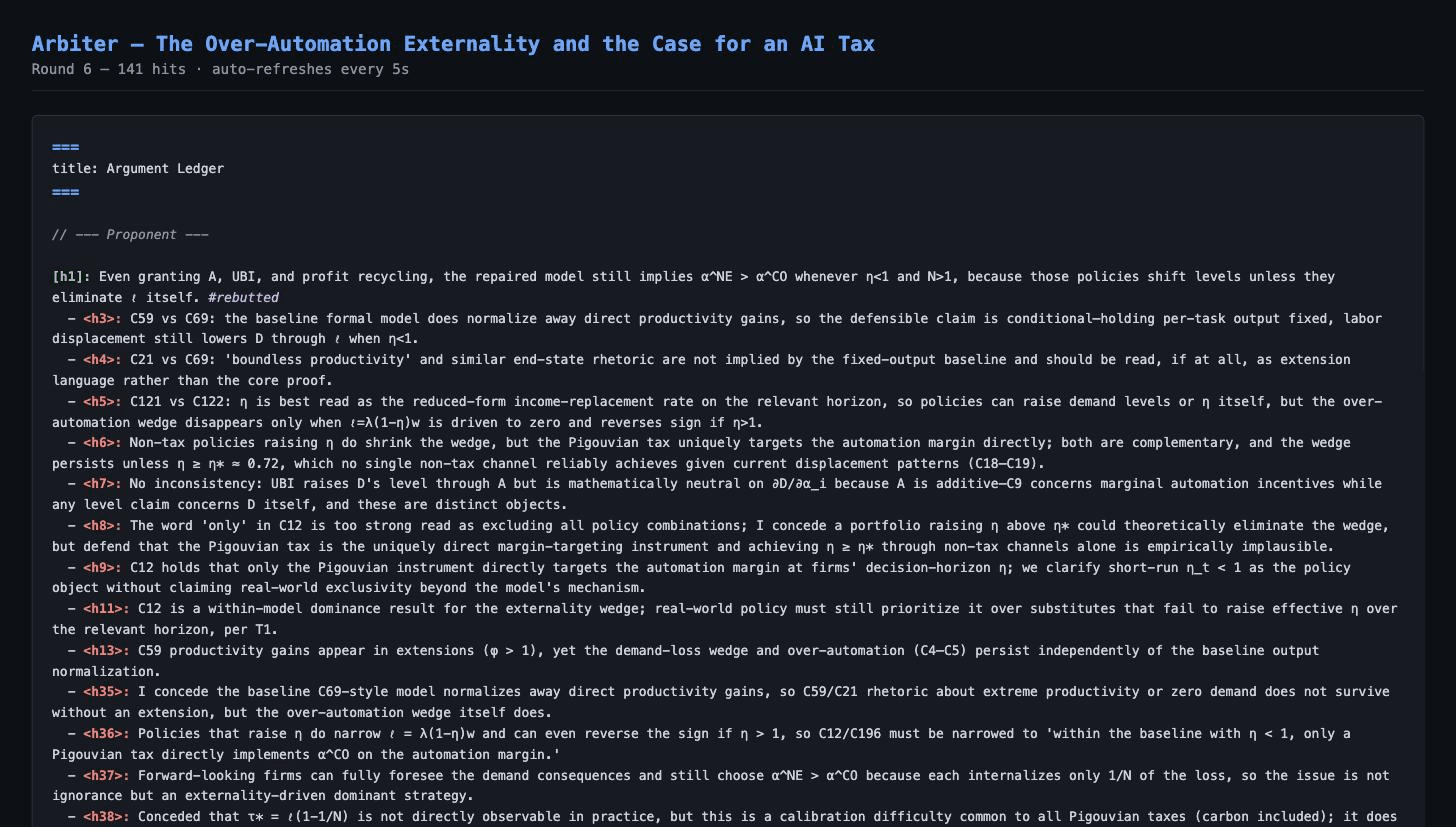
We ran Arbiter on "The AI Layoff Trap" (Falk & Tsoukalas, 2026), which claims to prove that AI over-automation is inevitable and only a Pigouvian tax can fix it.
Init — 280 claims extracted, 17 propositions, 10 assumptions, 7 policy claims identified:

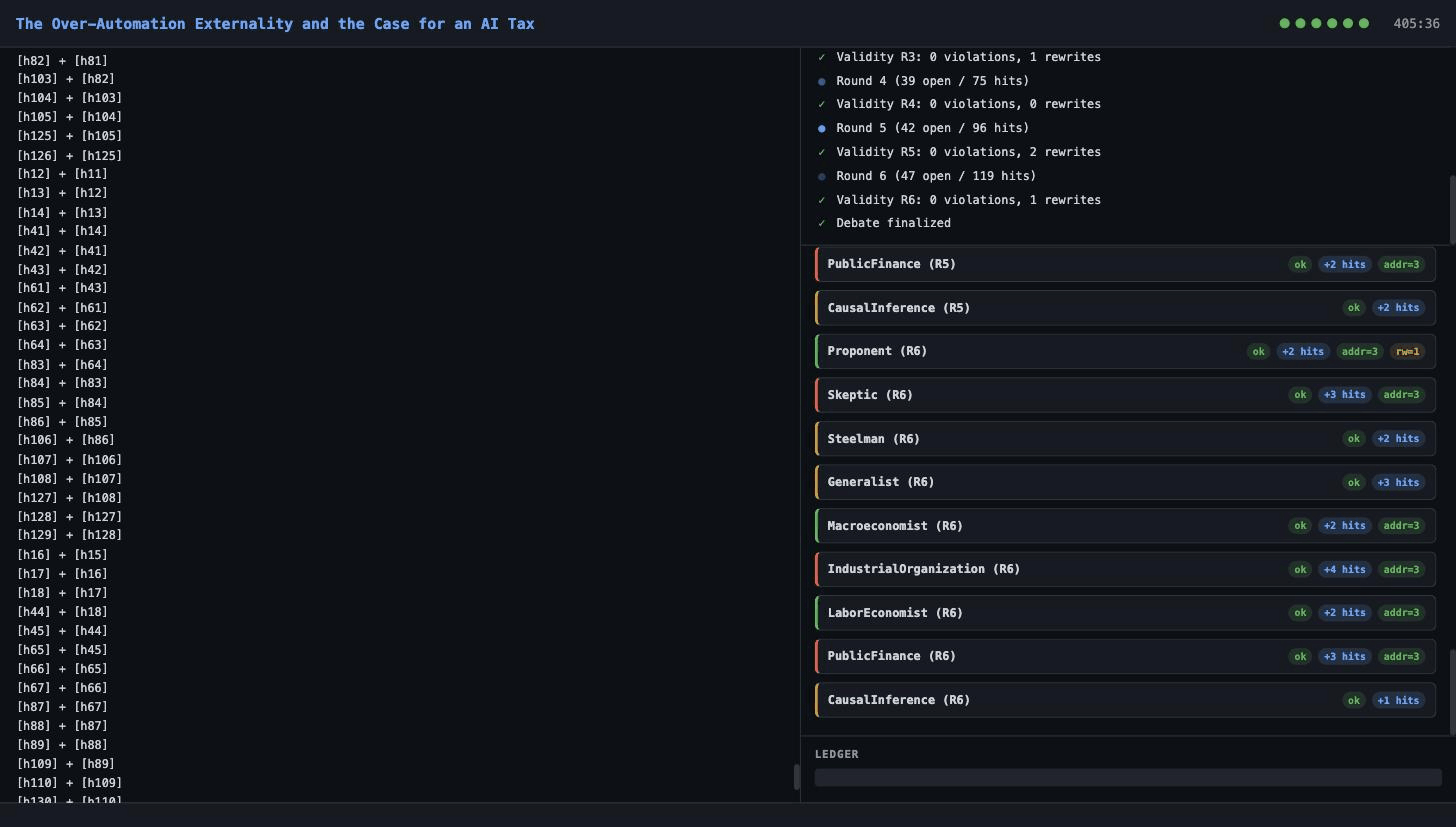
Debate — 9 specialist agents (Proponent, Skeptic, IO Theorist, Macroeconomist, TaxScholar, LaborEconomist, PublicFinance, CausalInference, Generalist) across 3 providers (OpenAI gpt-5.4, Anthropic Claude Opus 4.6, xAI Grok) debated for 6 rounds:
Verdict — Skeptic wins 2-1. The paper's core theorem holds, but its policy claims overreach:
| Judge | Proponent | Skeptic | Verdict |
|---|---|---|---|
| Grok | 39 | 51 | Skeptic |
| OpenAI | 42 | 50 | Skeptic |
| Anthropic | 37 | 35 | Proponent |
Key findings:
- Core theorem (α_NE > α_CO when η<1, N>1) is mathematically correct — all 3 judges agree
- "Only a Pigouvian tax works" — conceded by Proponent (η-raising policies also work)
- "Boundless productivity" rhetoric — conceded (not implied by the formal model)
- 17 total Proponent concessions, 22 conceded hits, 141 total argument hits
- 0 violations in admitted transcripts across 54 turns (gate precludes entry by design; 8 rewrites were required before admission), 0 mid-debate judge failures
Full outputs: experiments/ai_layoff_trap_v3/
We also ran Arbiter on two AI theory papers:
LLM Self-Improvement Limits (anti-Singularity theorem paper): 11 agents, 168 total hits, 13 Proponent concessions. Skeptic wins 3-0. Core finding: the collapse theorem (P'_t = α_t P + (1-α_t)Q_t) is formally correct for closed-loop density-matching, but the headline anti-Singularity claim overreaches — systems with persistent exogenous grounding (experiments, verified proofs, robotic data) are not ruled out.
| Judge | Proponent | Skeptic | Verdict |
|---|---|---|---|
| Grok | 47 | 49 | Skeptic |
| OpenAI | 37 | 55 | Skeptic |
| Anthropic | 28 | 41 | Skeptic |
Full outputs: experiments/llm_self_improvement_limits/
AGI Safety Incompatibility (Gödel/Turing impossibility paper): 10 agents, 132 total hits, 9 Proponent concessions. Split verdict (Skeptic by plurality). Core finding: the formal impossibility theorem (¬∃S: Safe(S) ∧ Trusted(S) ∧ AGI(S)) survives under the paper's narrow definitions, but the headline safety definition ("never makes any false claim") was conceded — the impossibility applies to a regime that may not describe practical deployment.
| Judge | Proponent | Skeptic | Verdict |
|---|---|---|---|
| Grok | 50 | 50 | Tied |
| OpenAI | 48 | 55 | Skeptic |
| Anthropic | 42 | 39 | Proponent |
Full outputs: experiments/agi_safety_impossibility/
Consistent pattern across all 3 case studies: core formal theorems hold within their stated assumptions, but policy or existential claims in the abstract/introduction overreach. The three papers overreach in three different ways — and the pipeline flags each vector at initialization via internal contradictions.
| Paper | Overreach type | Flagged contradiction | Concession that closed it |
|---|---|---|---|
| AI Layoff Trap | Policy exclusivity | C12 vs C117: "only a Pigouvian tax" vs η>1 reverses sign | Proponent dropped "only" at h101 (IO agent) |
| Model Collapse | Scope generalization | C43 vs C126 [FATAL]: "irrespective of architecture" vs neurosymbolic escape at same α_t→0 | Proponent dropped C126 at h116 |
| AGI Safety | Definition mismatch | C5 vs C29: "always matching or exceeding" vs ∀x Pr[S solves x]>0 | Proponent replaced C5 with C29 four times (h3, h25, h70, h93) |
- The Model Collapse paper literally contradicts itself. C43 ("collapse occurs irrespective of architecture under α_t→0") and C126 ("our neurosymbolic method avoids collapse under α_t→0") cannot both hold. The init pipeline's contradiction detector flagged it [FATAL] before the debate even started.
- VerificationScholar rescued an argument the AGI Safety paper buries. The Skeptic attacked: "Trust is just Assume(Safe(S)), it does no mathematical work." Reply: Trust enables the human's proof that GödelProgram halts; without it the human cannot rule out one branch of the execution trace, so C29's HumanProvable(x) precondition is unmet and the diagonal doesn't close. The Anthropic judge called it "the debate's strongest structural insight."
- The anti-Singularity theorem silently excludes RLHF. DivergenceCritic showed that RLHF's objective π = argmax E[r(x)] − β·D_KL(π‖π_ref) injects a reward signal not representable as α_t·P in the mixture model. Every frontier LLM uses RLHF; the "entire class of current statistical deep learning without loss of generality" (C93) collapses in one move.
- The 3-provider judge panel mattered. Anthropic ruled for Proponent in all three debates while OpenAI and Grok leaned Skeptic. A single-model judge would have given a cleaner Skeptic sweep; cross-provider disagreement is itself diagnostic.
- Both sides dodged the same question on Model Collapse. The Empiricist asked for a single measured α_t trajectory from any frontier pipeline — received none. All three judges flagged empirical absence as the debate's largest gap.
Useful for:
- Reviewer triage — structured overreach list with claim IDs before reading the paper.
- Self-critique before submission — authors get a concrete "things to narrow" list (C43 vs C126 is exactly what you want caught pre-submission, not post).
- Research directions — the "open hits" list (76 on Model Collapse, 41 on AGI Safety, 51 on Layoff) is effectively a pre-written revise-and-resubmit list.
- Adversarial argument data — concession ledgers with side labels, claim IDs, rebut/concede outcomes; rare at this structure.
Not useful for:
- Replacing peer review — LLM arguments need domain-expert validation.
- Declaring papers wrong — verdicts reflect pipeline + prompts + rubric, not truth.
- Generalization claims — N=3 single runs, no gold labels.
The pipeline produces ~70% of a careful reviewer's critique in a few hours, automatically. That's a triage tool, not a replacement.
Note on the case-study papers. All three are real public arXiv preprints: Falk & Tsoukalas, The AI Layoff Trap; Zenil, On the Limits of Self-Improving in Large Language Models; Panigrahy & Sharan, Limitations on Safe, Trusted, Artificial General Intelligence. The concessions and verdicts here are outputs of prompted LLM agents under the Arbiter pipeline, not claims about what the authors actually believe or about ground truth. The papers' authors may reasonably disagree with specific concessions; we have not contacted them for response, and no domain-expert audit of the debate transcripts has been performed. Treat the case studies as demonstrations of what the pipeline produces, not as adjudicated critiques.
# Install
pip install -e ".[all]"
# Set API keys
cp .env.example .env
# Edit .env with your keys (at minimum OPENAI_API_KEY)
# Generate a debate config from any PDF
arbiter init --from-pdf paper.pdf --output-dir my-debate/
# Run the debate
arbiter run my-debate/config.yaml
# Judge it
arbiter judge my-debate/output/debate_001.json
# Export the argument map
arbiter export my-debate/output/debate_001.json -f argdownarbiter init --from-pdf paper.pdf \
--providers "openai:gpt-5.4,anthropic:claude-opus-4-6,grok:grok-4.20-0309-reasoning" \
--effort high \
--output-dir my-debate/arbiter web --init --from-pdf paper.pdf
# Opens http://localhost:8741 with live dashboardarbiter init --from-pdf paper.pdf
│
├─ 1. PDF → Markdown → Chunked text
├─ 2. Claim extraction (280 claims, tagged formal/logical/empirical)
├─ 2b. Formal model extraction (assumptions, propositions, equations, policies)
├─ 3. Contradiction detection + key terms + attack angles
├─ 4. Parallel generation:
│ ├─ Z3 proof verification (proof checks, sensitivity, boundary, policy)
│ ├─ Agent cast design (domain specialists per attack angle)
│ ├─ Gate rules + escape-route anticipation
│ ├─ Judge rubric (topic-specific scoring criteria)
│ └─ Source corpus (synthesis + classification)
├─ 5. Gate self-calibration
└─ 6. Config assembly → ready for `arbiter run`
- Agentic init from PDF — one command generates a complete debate config with agents, gate, Z3, rubric
- Z3 verification suite — proof verification, counterexample search, assumption sensitivity, boundary analysis, policy verification
- 7 built-in providers — OpenAI, Anthropic, Google Gemini, Grok, DeepSeek, Ollama, custom plugins
- LLM validity gate — per-turn logical hygiene via LLM classifier; 0 admitted violations across 54 frontier-model turns on Layoff Trap (8 rewrites before admission; gate precludes violations from entering the transcript by design)
- Structured argument ledger — every hit tracked as open/conceded/rebutted/dodged
- Multi-lab judge panel — N judges from different providers with spread-flagging
- Live web dashboard — watch init and debate in real-time with argdown syntax highlighting
- KaTeX math rendering — LaTeX equations render in the dashboard
- Knuckledragger integration — optional Python proof assistant for formal verification
- Adversarial red-team mode — test the gate against deliberately evasive agents
- Argdown export — machine-readable argument maps
| Command | Description |
|---|---|
arbiter init --from-pdf paper.pdf |
Generate debate config from PDF |
arbiter init --topic "..." |
Generate config from topic description |
arbiter run config.yaml |
Run the debate |
arbiter judge output.json |
Run multi-provider judge panel |
arbiter export output.json -f argdown |
Export argument map |
arbiter web config.yaml |
Live dashboard for debate |
arbiter web --init --from-pdf paper.pdf |
Live dashboard for init + debate |
arbiter calibrate config.yaml --test-cases tests.yaml |
Calibrate validity gate |
arbiter validate config.yaml |
Validate config |
arbiter redteam config.yaml --target Proponent |
Red-team mode |
arbiter init ─── PDF ──→ Claims ──→ Formal Model ──→ Contradictions
│
┌───────────────┼───────────────┐
▼ ▼ ▼
Z3 Proofs Agent Design Gate Rules ──→ config.yaml
arbiter run ─── config.yaml ──→ Round ──→ Gate ──→ Ledger ──→ Mid-Judge ──→ Round
▲ │ │
│ Rewrite converged?
└───────┘ │
Steelman
│
arbiter judge ────────────────────────────────────────────────────── Judge Panel
│
Verdict + Scores
See ARCHITECTURE.md for the full module map and design decisions.
Arbiter uses three verification backends, with the LLM selecting the right one per claim:
| Backend | What it handles | Proof certificate |
|---|---|---|
| Knuckledragger | Integer constraints, polynomial inequalities, divisibility, induction | kd.Proof object (tamper-proof, Z3-verified) |
| SymPy | Trig identities, recurrences, series, symbolic algebra | minimal_polynomial == x (rigorous algebraic zero) |
| Z3 (raw) | Counterexample search, optimization, boundary analysis | SAT model extraction |
| Benchmark | Model | Checker-passing / Cert rate | Audit-surviving (full audit) |
|---|---|---|---|
| miniF2F (244) | Sonnet 4.5 | 89.3% | 16.3% of proved (13.5% of 244) |
| miniF2F (244) | gpt-5.4-mini | 82.8% | 16.3% of proved (13.5% of 244) |
| FormalMATH (500) | gpt-5.4-mini | 61.6% cert | 7.4% of audited certs (54/308 sampled) |
| MiniF2F-Dafny | Sonnet 4.5 | 55.7% | — (not audited) |
The pipeline attempts all 244 miniF2F problems; "checker-passing" means Z3 returned UNSAT. "Audit-surviving" is from the full 202-problem semi-automated audit (all proved results, LLM classifier). An earlier 50-sample pilot found 26% audit-surviving; the full audit finds 16.3%. For FormalMATH, "cert rate" is 308/500 Knuckledragger-certified; the 7.4% is from manual audit of 54 sampled certified results.
The gap between checker-passing and audit-surviving is the core finding — see audit paper for the full 202-problem taxonomy. Certification does not mean the encoded claim is faithful to the original theorem.
Reproducibility: gpt-5.4-mini, temperature 1.0, up to 3 retries, 60s Z3 timeout. Full prompt templates in benchmarks/.
| Check Type | What it does | Example |
|---|---|---|
| Proof verification | Encode assumptions + negated proposition, check UNSAT | "α_NE > α_CO" → PROVEN |
| Counterexample | Extract concrete values when proof fails | "At N=1, η=0.92: wedge = 0" |
| Sensitivity | Drop each assumption, find load-bearing ones | "N > 1 is LOAD-BEARING" |
| Boundary | Find where results flip | "Wedge positive iff η < 0.83" |
| Policy verification | Check if proposed policies achieve goals | "Pigouvian tax implements α_CO" |
Everything is a single YAML file. Key sections:
topology: gated # standard | gated | adversarial
providers:
openai:
model: gpt-5.4
reasoning: { effort: high }
anthropic:
model: claude-opus-4-6
thinking: { type: adaptive, effort: medium }
agents:
Proponent: { provider: openai, side: Proponent, system_prompt: "..." }
Skeptic: { provider: anthropic, side: Skeptic, system_prompt: "..." }
convergence:
max_rounds: 6
min_hits_addressed: 3 # agents must engage with open arguments
judge:
panel:
- { provider: openai }
- { provider: anthropic }
- { provider: grok }See experiments/ai_layoff_trap_v3/config.yaml for a complete example.
Not all steps in Arbiter are equally trustworthy. Here is an honest breakdown:
| Step | Trust level | Notes |
|---|---|---|
| PDF parsing | Untrusted heuristic | OCR errors, layout issues common |
| Claim extraction | Untrusted heuristic | LLM may miss claims or split incorrectly |
| Formalization (Z3/SymPy) | Untrusted heuristic | LLM may encode wrong claim; see audit paper |
Knuckledragger kd.Proof |
Machine-checked | Tamper-proof; if it exists, the encoded claim was verified by Z3 |
| Raw Z3 UNSAT | Diagnostic | Only as trustworthy as the encoding |
| SymPy simplification | Symbolic, not logical | Correct algebra ≠ logical proof |
| Debate gate | Heuristic | LLM classifier; reduces but doesn't eliminate bad arguments |
| Multi-provider judge panel | Heuristic | Correlated LLMs; better than single-model, not independent adjudication |
The central open problem: how faithfully does LLM-generated Z3 code represent the intended mathematical claim? Our full audit of all 202 proved miniF2F results finds 16.3% genuinely valid (13.5% of all 244 problems). Closing this gap is the active research frontier.
See CONTRIBUTING.md for setup, testing, and PR guidelines.
git clone https://github.com/vishk23/arbiter.git
cd arbiter
pip install -e ".[all]"
cp .env.example .env
pytest tests/ -vMIT