The environment use for this project is the L-world. It's a set of 2 gridworlds with L-shaped 'walls' the run along the side as shown here:
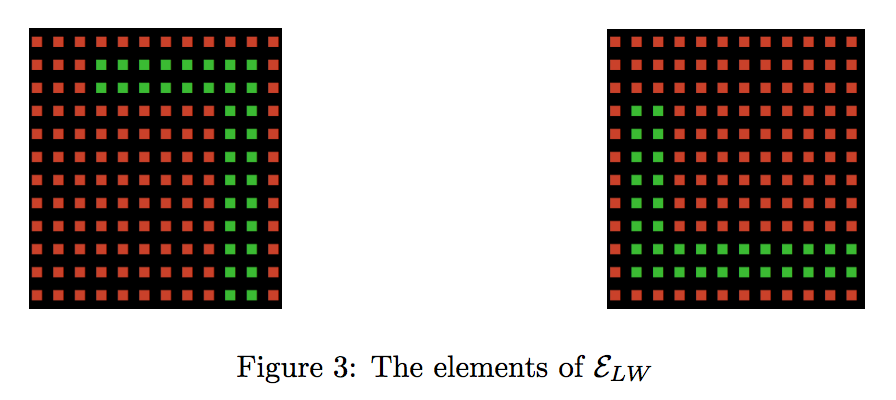
The agent cannot enter the GREEN squares in each case. The start state is the top left cell and the end state is the bottom right cell. A simple policy independent of the fact that green squares change isn't really possible since the environment changes and the optimal path is entirely different in each case.
The agent uses the following architecture to optimally determine the task( environment ) and solve it ( the agent can only observe a 5x5 square of states around it )
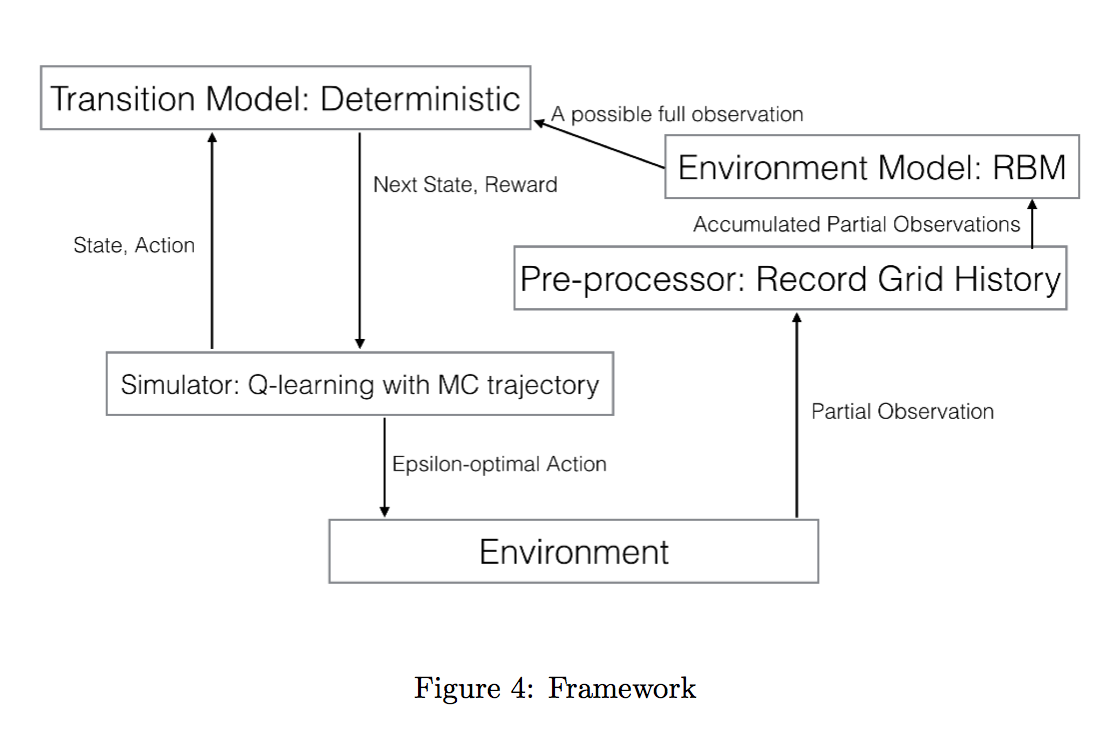
After running a fresh( randomly initialized ) agent on about 200 episodes, we see that the environment model has learnt the environment to a reasonable extent and can use the model to predict what the current task is:
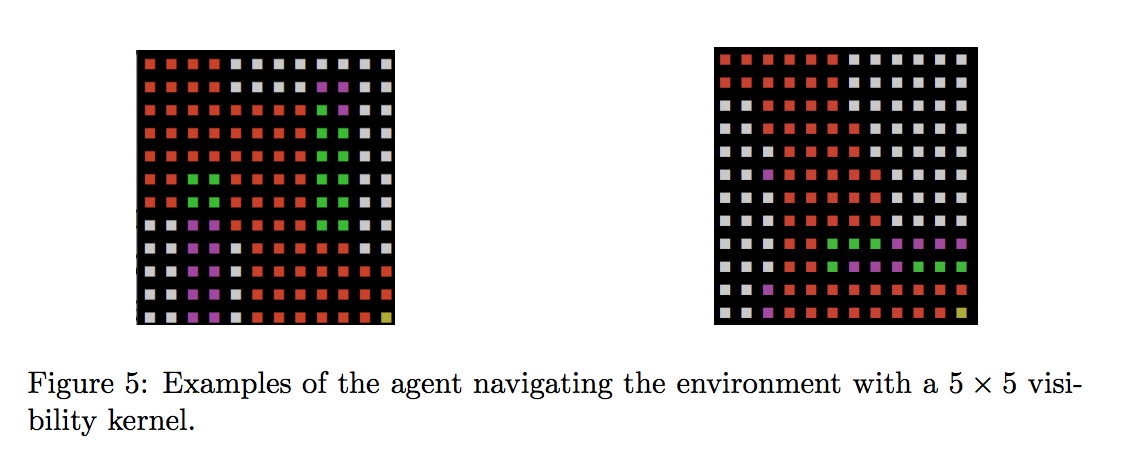
Agent - YELLOW
Observed Cell - RED
Hidden Cell - GREY
Imagined Wall - PURPLE
Observed Wall - GREEN
Model vs Model-free performance:
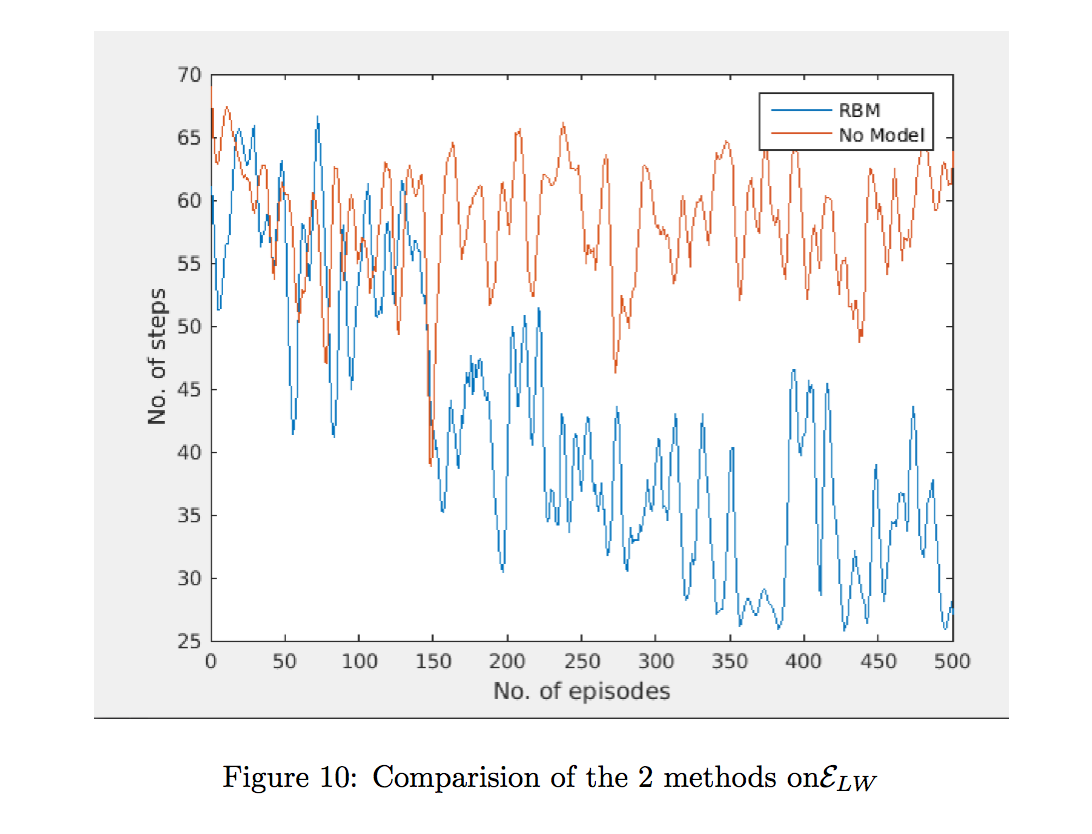
The Y-axis is the average number of steps required to reach the bottom-right square( Goal )