A graph consists of vertices (or nodes) and edges (or paths)
Edges
- are connections between vertices
- e.g., roads between cities
- can have one-way direction or can be bidirectional
- can have weights
- e.g., time to travel between two cities
A directional graph has edges that are all directional (i.e., if there's an edge from A to B, there might not be one from B to A)
An acyclic graph contains no cycles (in a directed graph, there's no path starting from some vertex v that will take you back to v)
A weighted graph contains edges that hold a numerical value (e.g., cost, time, etc.)




A complete graph is a graph where each vertex has an edge to all other vertices in the graph

There are two main ways to represent a graph:
- Adjacency matrix
- Adjacency list
An adjacency matrix uses a 2-dimensional array to represent edges between two vertices
There are many ways to use an adjacency matrix to represent a matrix, but we will look at two variations
boolean[][] conn = new boolean[ N ][ N ];The matrix conn tells us if two vertices are connected
if ( conn[ i ][ j ] )
// there is an edge from vertex i to vertex j
else
// there is no edge from vertex i to vertex jint[][] cost = new int[ N ][ N ];The matrix cost tells us the cost (or edge weight) between two vertices
cost[ i ][ j ] = 7; // this means it costs 7 units to travel from vertex i to vertex j
cost[ i ][ j ] = 0; // this usually means there is no edge from vertiex i to vertex jPros
- Easy to check if there is an edge between i and j
- calling
matrix[ i ][ j ]will tell us if there is a connection
- calling
Cons
- To find all neighbors of vertex i, you would need to check the value of
matrix[ i ][ j ]for all j - Need to construct a 2-dimensional array of size N x N
Rather than making space for all N x N possible edge connections, an adjacency list keeps track of the vertices that a vertex has an edge to.
We are able to do this by creating an array that contains ArrayLists holding the values of the vertices that a vertex is connected to.
ArrayList<Integer>[] graph = new ArrayList<Integer>[ N + 1 ];
// For each vertex, we need to initialize the list of vertices the vertex has a connection to
for ( int i = 0; i <= N; i++ )
{
graph[ i ] = new ArrayList<Integer>();
}
graph[ i ].add( j ); // get the list of vertices for vertex i and add a connection to vertex j
ArrayList<Integer> neighbors = graph[ k ]; // get the list of vertices that vertex k is connected toPros
- Saves memory by only keeping track of edges that a vertex has
- Efficient to iterate over the edges of a vertex
- Doesn't need to go through all N vertices and check if there is a connection
Cons
- Difficult to quickly determine if there is an edge between two vertices
Breadth-first search (or BFS) is a form of graph traversal that starts at some vertex i and visits all of i's neighbors. It then visits all of the neighbors of i's neighbors. This process keeps going until there are no more vertices left to visit.
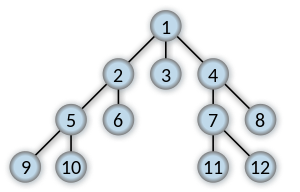
Imagine a "family tree", like one shown in the picture above. BFS will visit all vertices of the same level before moving on to the next level.
We start by visiting vertex 1.
Then, we visit all of 1's neighbors: 2, 3, 4
Then, we visit all of 1's neighbors' neighbors: 5, 6, 7, 8
Finally, we visit all of their neighbors: 9, 10, 11, 12

Above is another visual representation of the BFS process starting from the top vertex.
We need to use some data structure that will allow us to visit vertices "level-by-level", that is, visit every vertex at level j before we visit any vertex at level j+1.
In order to do this, we will be using a Queue since it follows the "first in, first out" ordering; this means if we put all the vertices at level j into the queue before the vertices at level j+1, we are guaranteed to visit the lower level vertices first.
Below are the steps to follow for BFS:
- Push the root vertex onto the queue
- Pop the queue to get the current vertex
- For each unvisited neighbor of the current vertex, mark them as visited and push them onto the queue
- Go back to step 2 until the queue is empty
// Initialize the queue
Queue<Integer> queue = new LinkedList<Integer>();
// This array will tell us if we have visited a vertex
boolean[] visited = new boolean[ N ];
// Push the root vertex onto the queue
queue.add( rootVertex );
// While there is a vertex still in the queue...
while ( !queue.isEmpty() )
{
// Get the current vertex
Integer current = queue.remove();
// Get the current vertex's neighbors
ArrayList<Integer> neighbors = graph[ current ];
// For each of the current vertex's neighbors...
foreach ( Integer neighbor : neighbors )
{
// If we haven't visited the neighbor...
if ( !visited[ neighbor ] )
{
// Add the neighbor to the queue
queue.add( neighbor );
// Mark the neighbor as visited
visited[ neighbor ] = true;
}
}
}Depth-first search (or DFS) is another form of graph traversal, but rather than visiting vertices "level-by-level", DFS aims to go as deep as possible in the graph before backtracking.

Imagine a "family tree", like one shown in the picture above. DFS will go as deep as it can in the graph before backtracking and repeating this process.
Starting at vertex 1, the graph will travel down the left side of the graph until it hits vertex 4, where it can no longer visit any unvisited vertices.
From vertex 4, it backtrack to vertex 3 and visits vertex 5, and since it can no longer visit any unvisited vertices, it backtracks to vertex 2, where it visits vertex 6.
This process repeats until the entire graph has been traversed.

Above is another visual representation of the DFS process starting from the top vertex.
The algorithm for DFS is very similar to that of BFS, except instead of using a Queue, we will be using a Stack.
Since a Stack follows the "last in, first out" ordering, when we are adding neighbors of a vertex to the Stack, the last one we push will be the next one we visit, allowing us to constantly go deeper into the graph rather than traversing level-by-level.
// Initialize the stack
Stack<Integer> stack = new Stack<Integer>();
// This array will tell us if we have visited a vertex
boolean[] visited = new boolean[ N ];
// Push the root vertex onto the stack
stack.push( rootVertex );
// While there is a vertex still in the stack...
while ( !stack.isEmpty() )
{
// Get the current vertex
Integer current = stack.pop();
// Get the current vertex's neighbors
ArrayList<Integer> neighbors = graph[ current ];
// For each of the current vertex's neighbors...
foreach ( Integer neighbor : neighbors )
{
// If we haven't visited the neighbor...
if ( !visited[ neighbor ] )
{
// Add the neighbor to the stack
stack.push( neighbor );
// Mark the neighbor as visited
visited[ neighbor ] = true;
}
}
}A tree is a special kind of graph that exhibits the following properties:
- Acyclic graph
- N vertices with N-1 edges
The graphs above that we used for BFS and DFS were both trees.

Above is another example of a tree.