diff --git a/ja/use-dify/nodes/ifelse.mdx b/ja/use-dify/nodes/ifelse.mdx
index c864b4ecc..51f7c387f 100644
--- a/ja/use-dify/nodes/ifelse.mdx
+++ b/ja/use-dify/nodes/ifelse.mdx
@@ -6,7 +6,6 @@ icon: "code-branch"
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/ifelse)を参照してください。
-
If-Elseノードは、定義した条件に基づいて実行を異なるパスにルーティングすることで、ワークフローに意思決定ロジックを追加します。変数を評価し、ワークフローが従うべき分岐を決定します。
@@ -29,11 +28,11 @@ If-Elseノードは、定義した条件に基づいて実行を異なるパス
- **Contains** / **Not contains** - テキストが特定の単語やフレーズを含むかチェック
+ **Contains** / **Not contains** - 値が特定の単語やフレーズを含むかチェック
**Starts with** / **Ends with** - パターンマッチングのためにテキストの始まりや終わりをテスト
- **Is** / **Is not** - 正確なテキスト比較のための完全値マッチング
+ **Is** / **Is not** - 完全値マッチング
@@ -59,18 +58,6 @@ If-Elseノードは、定義した条件に基づいて実行を異なるパス
## 変数参照
-条件で以前のワークフローノードからの任意の変数を参照します。変数は、ユーザー入力、大規模言語モデルのレスポンス、API呼び出し、または他のワークフローノード出力から取得できます。
-
-変数セレクターを使用して利か、`{{variable_name}}`構文を使用して変数名を直接入力します。
-
-## 共通パターン
-
-**コンテンツルーティング** - カテゴリ、言語、または複雑さに基づいて、異なるタイプのコンテンツを専用の処理ノードに振り分けます。
-
-**ユーザー役割管理** - ユーザー権限、サブスクリプションレベル、またはアカウントタイプに基づいて異なるワークフロー動作を実装します。
-
-**エラーハンドリング** - レスポンス状態コード、データ妥当性、または処理結果をチェックして、ワークフローを適切にルーティングします。
-
-**動的処理** - 入力特性、処理結果、または外部条件に基づいてワークフロー動作を調整します。
+条件で以前のワークフローノードからの任意の変数を参照します。変数は、ユーザー入力、LLMレスポンス、API呼び出し、または他のワークフローノード出力から取得できます。
-**マルチパスワークフロー** - アプリケーションのさまざまなシナリオやエッジケースを処理する洗練された分岐ロジックを作成します。
+変数セレクターを使用して利用可能な変数から選択するか、`{{variable_name}}`構文を使用して変数名を直接入力します。
\ No newline at end of file
diff --git a/ja/use-dify/nodes/list-operator.mdx b/ja/use-dify/nodes/list-operator.mdx
index a287c5554..e0400a3fe 100644
--- a/ja/use-dify/nodes/list-operator.mdx
+++ b/ja/use-dify/nodes/list-operator.mdx
@@ -6,9 +6,10 @@ icon: "filter"
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/list-operator)を参照してください。
-
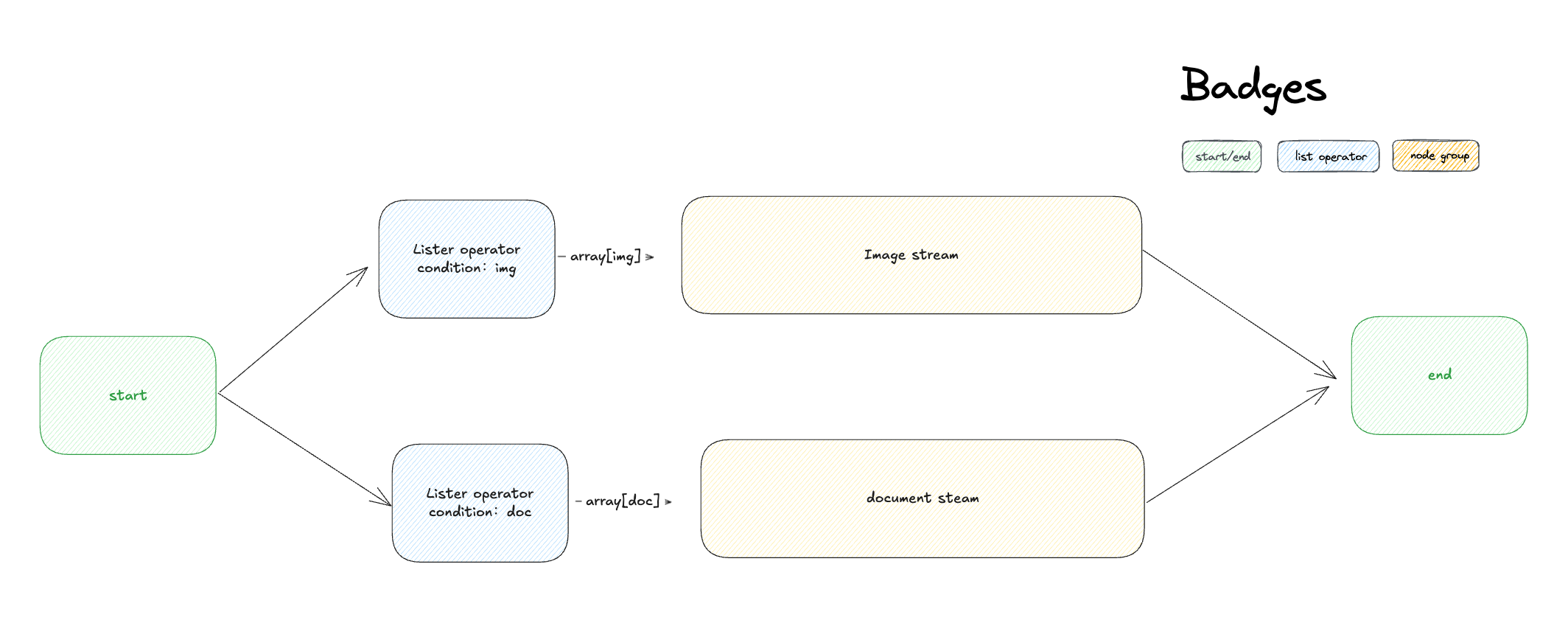
リスト演算子ノードは、配列のフィルタリング、ソート、特定の要素の選択を行います。混合ファイルアップロード、大規模なデータセット、または下流処理の前に分離や整理が必要な配列データを扱う際に使用します。
+サポートされる入力データ型には、`array[string]`、`array[number]`、`array[file]`、`array[boolean]`があります。
+
 @@ -23,16 +24,6 @@ icon: "filter"
@@ -23,16 +24,6 @@ icon: "filter"
 -## サポートされるデータ型
-
-ノードは適切なフィルタリングオプションを使用して、さまざまな配列タイプを処理します:
-
-**Array[string]** - テキストリスト、カテゴリ、名前、または任意の文字列コレクション
-
-**Array[number]** - 数値データ、スコア、測定値、または計算結果
-
-**Array[file]** - 豊富なメタデータフィルタリング機能を持つ混合ファイルアップロード
-
## 操作
### フィルタリング
@@ -79,7 +70,7 @@ icon: "filter"
**result** - バルク処理用の完全なフィルタリングおよびソート済み配列
-**first_record** - 先頭からの単一要素、「プテム選択に最適
+**first_record** - 先頭からの単一要素、「主要」または「最新」アイテム選択に最適
**last_record** - 末尾からの単一要素、「最新」または「最終」選択に有用
@@ -95,31 +86,9 @@ icon: "filter"
1. **混合アップロードの設定** - 複数のファイルタイプを受け入れるファイルアップロード機能を有効化
2. **タイプ別に分割** - 異なるフィルターを持つ別々のリスト演算子ノードを使用:
- - `type = "image"`でフィルタリング → ビジョン機能を持つ大規模言語モデルにルーティング
+ - `type = "image"`でフィルタリング → ビジョン機能を持つLLMにルーティング
- `type = "document"`でフィルタリング → 文書抽出器にルーティング
3. **適切に処理** - 画像は直接分析され、文書はテキスト抽出が行われる
4. **結果を結合** - 処理された出力を統一されたレスポンスにマージ
-このパターンは、異なるファイルタイプを適切なプロセッサーに自動的にルーティングし、シームレスなマルチモーダルユーザーエクスペリエンスを作成します。
-
-## 一般的な使用例
-
-**ファイルタイプルーティング** - 混合アップロードをコンテンツタイプに基づいて専門的な処理パイプラインに分離
-
-**データフィルタリング** - 特定の基準に基づいて大規模なデータセットから関連するサブセットを抽出
-
-**コンテンツ優先順位付け** - コレクションから最も重要または最新のアイテムをソートして選択
-
-**品質管理** - 処理前に無効、過大サイズ、またはサポートされていないコンテンツをフィルターで除外
-
-**バッチ準備** - 下流の反復処理や並列処理のためにデータを管理可能なチャンクに整理
-
-## ベストプラクティス
-
-**フィルター基準の計画** - 下流処理要件に基づいて明確なフィルタリングルールを定義
-
-**適切な出力タイプの使用** - 下流ノードがデータをどのように使用するかに基づいて、完全な配列、最初のレコード、または最後のレコードを選択
-
-**空の結果の処理** - フィルターが一致しない場合の対処法を検討し、適切なフォールバックロジックを計画
-
-**実データでのテスト** - 本番環境での信頼性のある動作を保証するために、実際のユーザーアップロードでフィルタリング動作を検証
+このパターンは、異なるファイルタイプを適切なプロセッサーに自動的にルーティングし、シームレスなマルチモーダルユーザーエクスペリエンスを作成します。
\ No newline at end of file
diff --git a/ja/use-dify/nodes/user-input.mdx b/ja/use-dify/nodes/user-input.mdx
index a34f4fbb6..837f7a5df 100644
--- a/ja/use-dify/nodes/user-input.mdx
+++ b/ja/use-dify/nodes/user-input.mdx
@@ -1,16 +1,18 @@
---
title: "ユーザー入力"
-description: "ワークフローとチャットフローアプリケーションのエントリーポイント"
+description: "ワークフローとチャットフローアプリケーションを開始するためのユーザー入力を収集します"
icon: "input-text"
---
- ⚠️ このドキュメントは AI によって自動翻訳されています。不正確な点がある場合は、[英語版](/en/use-dify/nodes/user-input)を参照してください。
+ ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/user-input)を参照してください。
## はじめに
-ユーザー入力ノードは、アプリケーションの実行時にエンドユーザーから収集する情報を定義できる開始ノードの一種です。
+ユーザー入力ノードでは、アプリケーションへの入力としてエンドユーザーから収集する内容を定義できます。
-このノードで開始するアプリケーションは、直接的なユーザー操作または API 呼び出しによって開始される*オンデマンド*で実行されます。これらのアプリケーションをスタンドアロンの Web アプリや MCP サーバーとして公開したり、バックエンドサービス API を介して公開したり、他の Dify アプリケーションでツールとして使用したりすることもできます。
+このノードで開始するアプリケーションは*オンデマンド*で実行され、直接的なユーザー操作または API 呼び出しによって開始できます。
+
+これらのアプリケーションをスタンドアロンの Web アプリや MCP サーバーとして公開したり、バックエンドサービス API を介して公開したり、他の Dify アプリケーションでツールとして使用したりすることもできます。
各アプリケーションキャンバスには、ユーザー入力ノードを 1 つだけ含めることができます。
@@ -34,16 +36,16 @@ icon: "input-text"
### カスタム
-ユーザー入力ノードでカスタム入力フィールドを構成して、エンドユーザーから情報を収集できます。各フィールドは、ダウンストリームノードが参照できる変数になります。たとえば、変数名 `user_name` の入力フィールドを追加すると、ワークフロー全体で `{{user_name}}` として参照できます。
-
-さまざまな種類のユーザー入力を処理するために、7 種類の入力フィールドから選択できます。
+ユーザー入力ノードでカスタム入力フィールドを設定して、さまざまな種類のユーザー入力を収集できます。各フィールドは、下流のノードから参照できる変数になります。
**ラベル名**はエンドユーザーに表示されます。
- チャットフローアプリケーションでは、任意の入力変数を**非表示**にして、エンドユーザーには見えないようにしつつ、チャットフロー内で参照可能な状態を維持できます。
+ チャットフローアプリケーションでは、任意のユーザー入力フィールドを**非表示**にして、エンドユーザーには見えないようにしつつ、チャットフロー内で参照可能な状態を維持できます。
+
+ **必須**フィールドは非表示にできないことに注意してください。
#### テキスト入力
@@ -51,11 +53,11 @@ icon: "input-text"
- 短いテキストフィールドは最大 256 文字を受け付けます。名前、メールアドレス、タイトル、または 1 行に収まる短いテキスト入力に使用します。
+ 最大 256 文字を受け付けます。名前、メールアドレス、タイトル、または 1 行に収まる短いテキスト入力に使用します。
- 段落フィールドは長さ制限なしの長文テキストを許可します。詳細な応答や説明のために、ユーザーに複数行のテキストエリアを提供します。
+ 長さ制限なしの長文テキストを許可します。詳細な応答や説明のために、ユーザーに複数行のテキストエリアを提供します。
@@ -64,15 +66,21 @@ icon: "input-text"
- 選択フィールドは、事前定義されたオプションを含むドロップダウンメニューを表示します。ユーザーはリストされたオプションからのみ選択でき、データの一貫性を確保し、無効な入力を防ぎます。
+ 事前定義されたオプションを含むドロップダウンメニューを表示します。ユーザーはリストされたオプションからのみ選択でき、データの一貫性を確保し、無効な入力を防ぎます。
- 数値フィールドは数値のみに入力を制限します—数量、評価、ID、または数学的処理を必要とするデータに最適です。
+ 数値のみに入力を制限します。数量、評価、ID、または数学的処理を必要とするデータに最適です。
- チェックボックスフィールドは、シンプルなはい/いいえオプションを提供します。ユーザーがボックスをチェックすると、出力は `true` になります。それ以外の場合は `false` になります。確認や二者択一が必要な場合に使用します。
+ シンプルなはい/いいえオプションを提供します。ユーザーがボックスをチェックすると、出力は `true` になり、それ以外の場合は `false` になります。確認や二者択一が必要な場合に使用します。
+
+
+
+ JSON オブジェクト形式のデータを受け付けます。複雑でネストされたデータ構造をアプリケーションに渡すのに最適です。
+
+ オプションで JSON スキーマを定義して、入力を検証し、期待される構造についてユーザーをガイドできます。これにより、他のノードでオブジェクトの個々のプロパティを参照することもできます。
@@ -80,11 +88,12 @@ icon: "input-text"
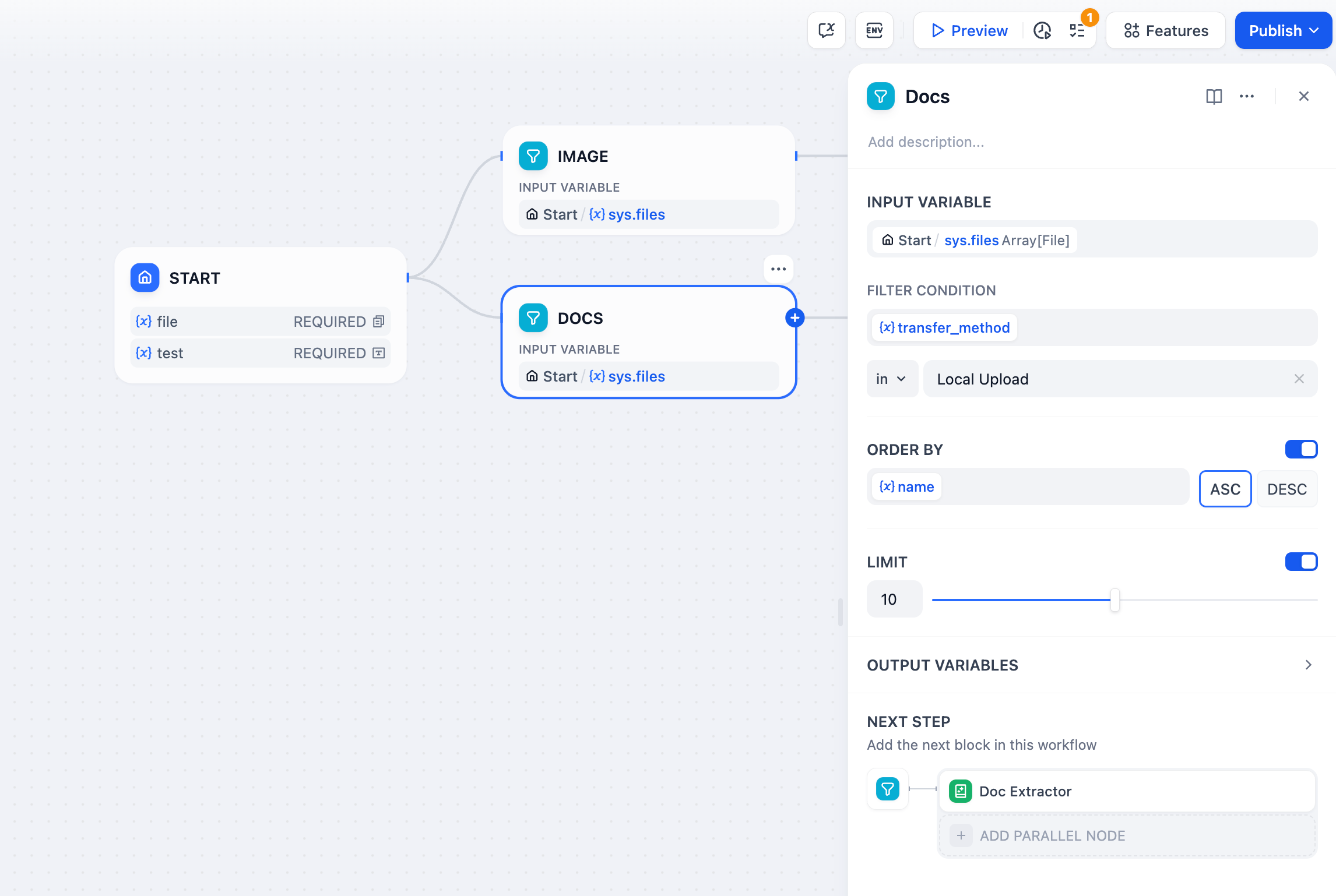
- 単一ファイルフィールドを使用すると、ユーザーはデバイスまたはファイル URL を介して、サポートされている任意のタイプの 1 つのファイルをアップロードできます。アップロードされたファイルは、ファイルメタデータ(名前、サイズ、タイプなど)を含む変数として利用できます。
+ ユーザーはデバイスまたはファイル URL を介して、サポートされている任意のタイプの 1 つのファイルをアップロードできます。アップロードされたファイルは、ファイルメタデータ(名前、サイズ、タイプなど)を含む変数として利用できます。
- ファイルリストフィールドは単一ファイルと同様に機能しますが、一度に複数のファイルのアップロードをサポートします。ドキュメント、画像、その他のファイルのバッチを一緒に処理する場合に便利です。
+ 一度に複数のファイルのアップロードをサポートします。ドキュメント、画像、その他のファイルのバッチを一緒に処理する場合に便利です。
+
リスト演算子ノードを使用して、アップロードされたファイルリストから特定のファイルをフィルタリング、並べ替え、または抽出して、さらに処理することができます。
@@ -93,16 +102,16 @@ icon: "input-text"
**ファイル処理**
-ユーザー入力ノードを介してアップロードされたファイルは、後続のノードによって適切に処理される必要があります。ユーザー入力ノードはファイルを収集するだけで、コンテンツを読み取ったり解析したりしません。
-
-したがって、ファイルコンテンツを抽出して処理するために特定のノードを接続する必要があります。例えば:
+ユーザー入力ノードはファイルを収集するだけで、コンテンツを読み取ったり解析したりしないため、アップロードされたファイルは後続のノードによって適切に処理される必要があります。例えば:
- ドキュメントファイルは、LLM がそのコンテンツを理解できるように、テキスト抽出のためにドキュメント抽出器ノードにルーティングできます。
+
- 画像は、ビジョン機能を持つ LLM ノードまたは専用の画像処理ツールノードに送信できます。
+
- CSV や JSON などの構造化データファイルは、コードノードを使用して解析および変換できます。
- ユーザーが混在タイプの複数のファイル(画像とドキュメントなど)をアップロードする場合、リスト演算子ノードを使用してファイルタイプ別に分離してから、適切な処理ブランチにルーティングできます。
+ ユーザーが混在タイプの複数のファイル(画像とドキュメントなど)をアップロードする場合、リスト演算子ノードを使用してファイルタイプ別に分離してから、異なる処理ブランチにルーティングできます。
## 次のステップ
@@ -110,5 +119,7 @@ icon: "input-text"
ユーザー入力ノードを設定したら、収集したデータを処理する他のノードに接続できます。一般的なパターンには次のものがあります:
- 入力を LLM ノードに送信して処理する。
-- ナレッジ検索ノードを使用して、入力に基づいて関連情報を検索する。
-- 入力に基づいて条件ロジックを使用して実行パスを異なるブランチにルーティングする。
+
+- ナレッジ検索ノードを使用して、入力に関連する情報を検索する。
+
+- If/Else ノードを使用して、入力に基づいて条件分岐を作成する。
\ No newline at end of file
diff --git a/ja/use-dify/nodes/variable-aggregator.mdx b/ja/use-dify/nodes/variable-aggregator.mdx
index 0c7db92c0..7efce6a75 100644
--- a/ja/use-dify/nodes/variable-aggregator.mdx
+++ b/ja/use-dify/nodes/variable-aggregator.mdx
@@ -6,7 +6,6 @@ icon: "merge"
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/variable-aggregator)を参照してください。
-
変数アグリゲーターノードは、異なる実行パスからの変数を単一の統一された出力に結合します。複数のブランチが類似の出力を生成する場合、このノードは一つの一貫した変数参照を作成することで、下流での重複処理の必要性を排除します。
## 分岐の問題
@@ -52,9 +51,10 @@ icon: "merge"
**同一型ルール** - すべての集約された変数は同じデータ型である必要があります。最初の変数(例:文字列)を接続すると、ノードは他のブランチから同じ型の変数のみを受け入れます。
**サポートされる型:**
-- **文字列** - 異なる処理力
+- **文字列** - 異なる処理ブランチからのテキスト出力
- **数値** - 数値計算、スコア、または測定値
- **オブジェクト** - 類似のスキーマを持つ構造化データオブジェクト
+- **ブール値** - True/false値
- **配列** - リスト、コレクション、または複数の結果
### 出力動作
@@ -67,24 +67,4 @@ icon: "merge"
高度なワークフロー(v0.6.10+)では、複数の変数グループを同時に集約できます。各グループは独自の型制約を維持し、同一ノード内で異なるデータ型を並行して集約することができます。
-これは、ブランチが複数の関連する出力を生成し、それらを個別に結合する必要がある場合に便利です - たとえば、異なる処理パスからのテキスト要約と数値スコアの両方を集約する場合です。
-
-## 一般的な使用例
-
-**マルチカテゴリ処理** - 異なるコンテンツタイプには専用の処理が必要ですが、共通の下流ロジックに供給される類似の出力を生成します。
-
-**条件付きデータソース** - 異なる条件が異なる知識検索やAPI呼び出しをトリガーしますが、すべての結果には同じ最終処理が必要です。
-
-**ブランチ結果の統合** - 複雑な分岐ロジックがさまざまな出力を生成しますが、最終的には統一された処理が必要です。
-
-**エラー処理** - メイン処理とフォールバックブランチが異なるが互換性のある結果を生成し、下流ノードが一貫して処理できます。
-
-## ベストプラクティス
-
-**データ型の計画** - 変数アグリゲーターに接続する前に、すべてのブランチが互換性のあるデータ型を生成することを確認します。
-
-**一貫した出力構造** - オブジェクトや配列を集約する際は、予測可能な下流処理のためにすべてのブランチで一貫した構造を維持します。
-
-**説明的な名前を使用** - 集約された変数には、複数の可能なソースからの結果を含むことを明確に示す名前を付けます。
-
-**すべてのブランチをテスト** - 各可能な実行パスが、集約時に正しく動作する有効な出力を生成することを確認します。
+これは、ブランチが複数の関連する出力を生成し、それらを個別に結合する必要がある場合に便利です - たとえば、異なる処理パスからのテキスト要約と数値スコアの両方を集約する場合です。
\ No newline at end of file
diff --git a/ja/use-dify/nodes/variable-assigner.mdx b/ja/use-dify/nodes/variable-assigner.mdx
index 8f8e58e4f..c05106c60 100644
--- a/ja/use-dify/nodes/variable-assigner.mdx
+++ b/ja/use-dify/nodes/variable-assigner.mdx
@@ -6,8 +6,7 @@ icon: "pen-to-square"
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/variable-assigner)を参照してください。
-
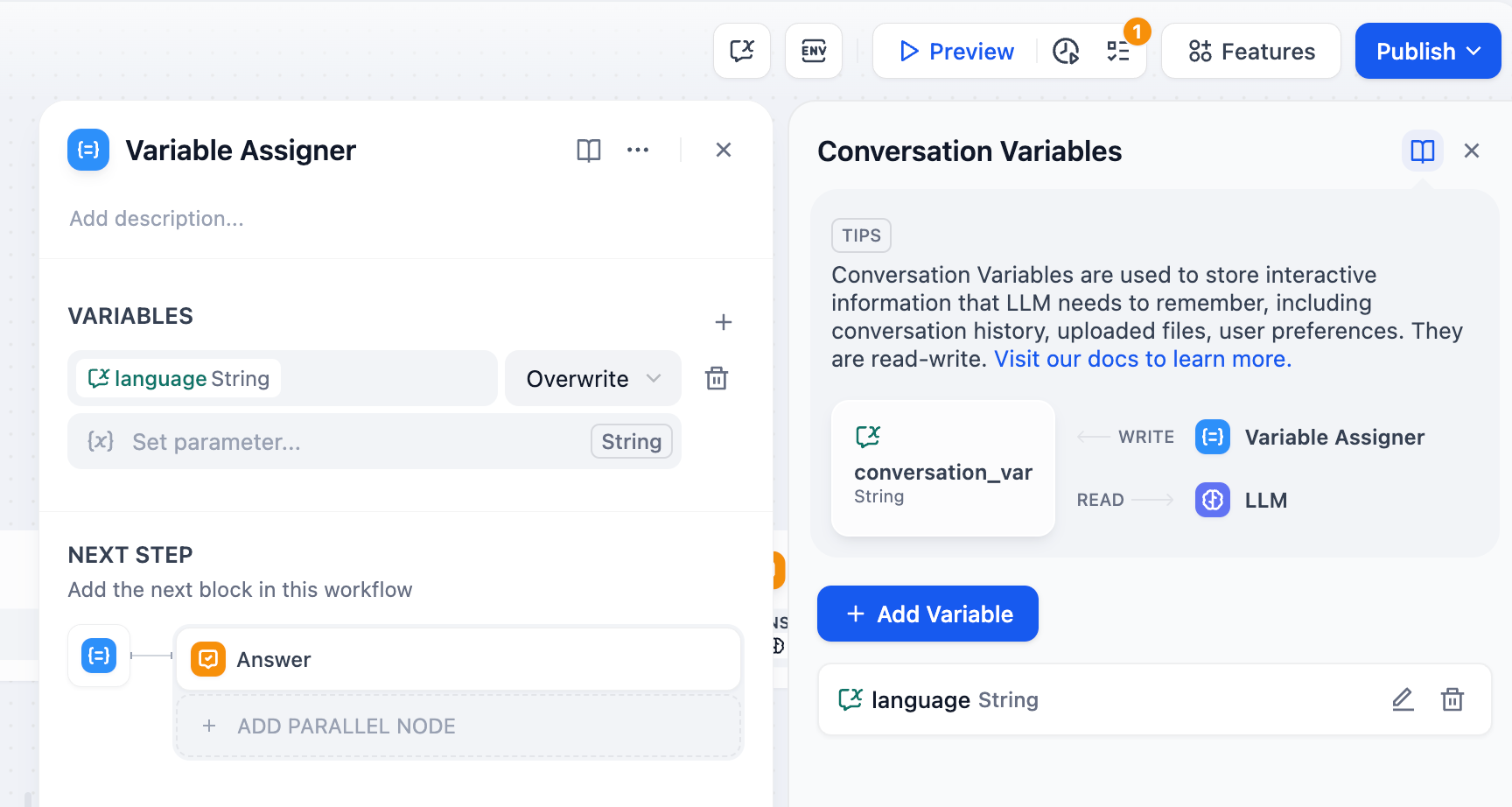
-変数アサイナーノードは、会話変数への書き込み(さまざまなタイプの変数については[こちら](jp/use-dify/getting-started/key-concepts#variables)を参照)によってチャットフローアプリケーションの永続的なデータを管理します。各実行でリセットされる通常のワークフロー変数とは異なり、会話変数はチャットセッション全体を通じて持続します。
+変数アサイナーノードは、会話変数への書き込み(さまざまなタイプの変数については[こちら](/ja/use-dify/getting-started/key-concepts#変数)を参照)によってチャットフローアプリケーションの永続的なデータを管理します。各実行でリセットされる通常のワークフロー変数とは異なり、会話変数はチャットセッション全体を通じて持続します。
-## サポートされるデータ型
-
-ノードは適切なフィルタリングオプションを使用して、さまざまな配列タイプを処理します:
-
-**Array[string]** - テキストリスト、カテゴリ、名前、または任意の文字列コレクション
-
-**Array[number]** - 数値データ、スコア、測定値、または計算結果
-
-**Array[file]** - 豊富なメタデータフィルタリング機能を持つ混合ファイルアップロード
-
## 操作
### フィルタリング
@@ -79,7 +70,7 @@ icon: "filter"
**result** - バルク処理用の完全なフィルタリングおよびソート済み配列
-**first_record** - 先頭からの単一要素、「プテム選択に最適
+**first_record** - 先頭からの単一要素、「主要」または「最新」アイテム選択に最適
**last_record** - 末尾からの単一要素、「最新」または「最終」選択に有用
@@ -95,31 +86,9 @@ icon: "filter"
1. **混合アップロードの設定** - 複数のファイルタイプを受け入れるファイルアップロード機能を有効化
2. **タイプ別に分割** - 異なるフィルターを持つ別々のリスト演算子ノードを使用:
- - `type = "image"`でフィルタリング → ビジョン機能を持つ大規模言語モデルにルーティング
+ - `type = "image"`でフィルタリング → ビジョン機能を持つLLMにルーティング
- `type = "document"`でフィルタリング → 文書抽出器にルーティング
3. **適切に処理** - 画像は直接分析され、文書はテキスト抽出が行われる
4. **結果を結合** - 処理された出力を統一されたレスポンスにマージ
-このパターンは、異なるファイルタイプを適切なプロセッサーに自動的にルーティングし、シームレスなマルチモーダルユーザーエクスペリエンスを作成します。
-
-## 一般的な使用例
-
-**ファイルタイプルーティング** - 混合アップロードをコンテンツタイプに基づいて専門的な処理パイプラインに分離
-
-**データフィルタリング** - 特定の基準に基づいて大規模なデータセットから関連するサブセットを抽出
-
-**コンテンツ優先順位付け** - コレクションから最も重要または最新のアイテムをソートして選択
-
-**品質管理** - 処理前に無効、過大サイズ、またはサポートされていないコンテンツをフィルターで除外
-
-**バッチ準備** - 下流の反復処理や並列処理のためにデータを管理可能なチャンクに整理
-
-## ベストプラクティス
-
-**フィルター基準の計画** - 下流処理要件に基づいて明確なフィルタリングルールを定義
-
-**適切な出力タイプの使用** - 下流ノードがデータをどのように使用するかに基づいて、完全な配列、最初のレコード、または最後のレコードを選択
-
-**空の結果の処理** - フィルターが一致しない場合の対処法を検討し、適切なフォールバックロジックを計画
-
-**実データでのテスト** - 本番環境での信頼性のある動作を保証するために、実際のユーザーアップロードでフィルタリング動作を検証
+このパターンは、異なるファイルタイプを適切なプロセッサーに自動的にルーティングし、シームレスなマルチモーダルユーザーエクスペリエンスを作成します。
\ No newline at end of file
diff --git a/ja/use-dify/nodes/user-input.mdx b/ja/use-dify/nodes/user-input.mdx
index a34f4fbb6..837f7a5df 100644
--- a/ja/use-dify/nodes/user-input.mdx
+++ b/ja/use-dify/nodes/user-input.mdx
@@ -1,16 +1,18 @@
---
title: "ユーザー入力"
-description: "ワークフローとチャットフローアプリケーションのエントリーポイント"
+description: "ワークフローとチャットフローアプリケーションを開始するためのユーザー入力を収集します"
icon: "input-text"
---
- ⚠️ このドキュメントは AI によって自動翻訳されています。不正確な点がある場合は、[英語版](/en/use-dify/nodes/user-input)を参照してください。
+ ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/user-input)を参照してください。
## はじめに
-ユーザー入力ノードは、アプリケーションの実行時にエンドユーザーから収集する情報を定義できる開始ノードの一種です。
+ユーザー入力ノードでは、アプリケーションへの入力としてエンドユーザーから収集する内容を定義できます。
-このノードで開始するアプリケーションは、直接的なユーザー操作または API 呼び出しによって開始される*オンデマンド*で実行されます。これらのアプリケーションをスタンドアロンの Web アプリや MCP サーバーとして公開したり、バックエンドサービス API を介して公開したり、他の Dify アプリケーションでツールとして使用したりすることもできます。
+このノードで開始するアプリケーションは*オンデマンド*で実行され、直接的なユーザー操作または API 呼び出しによって開始できます。
+
+これらのアプリケーションをスタンドアロンの Web アプリや MCP サーバーとして公開したり、バックエンドサービス API を介して公開したり、他の Dify アプリケーションでツールとして使用したりすることもできます。
各アプリケーションキャンバスには、ユーザー入力ノードを 1 つだけ含めることができます。
@@ -34,16 +36,16 @@ icon: "input-text"
### カスタム
-ユーザー入力ノードでカスタム入力フィールドを構成して、エンドユーザーから情報を収集できます。各フィールドは、ダウンストリームノードが参照できる変数になります。たとえば、変数名 `user_name` の入力フィールドを追加すると、ワークフロー全体で `{{user_name}}` として参照できます。
-
-さまざまな種類のユーザー入力を処理するために、7 種類の入力フィールドから選択できます。
+ユーザー入力ノードでカスタム入力フィールドを設定して、さまざまな種類のユーザー入力を収集できます。各フィールドは、下流のノードから参照できる変数になります。
**ラベル名**はエンドユーザーに表示されます。
- チャットフローアプリケーションでは、任意の入力変数を**非表示**にして、エンドユーザーには見えないようにしつつ、チャットフロー内で参照可能な状態を維持できます。
+ チャットフローアプリケーションでは、任意のユーザー入力フィールドを**非表示**にして、エンドユーザーには見えないようにしつつ、チャットフロー内で参照可能な状態を維持できます。
+
+ **必須**フィールドは非表示にできないことに注意してください。
#### テキスト入力
@@ -51,11 +53,11 @@ icon: "input-text"
- 短いテキストフィールドは最大 256 文字を受け付けます。名前、メールアドレス、タイトル、または 1 行に収まる短いテキスト入力に使用します。
+ 最大 256 文字を受け付けます。名前、メールアドレス、タイトル、または 1 行に収まる短いテキスト入力に使用します。
- 段落フィールドは長さ制限なしの長文テキストを許可します。詳細な応答や説明のために、ユーザーに複数行のテキストエリアを提供します。
+ 長さ制限なしの長文テキストを許可します。詳細な応答や説明のために、ユーザーに複数行のテキストエリアを提供します。
@@ -64,15 +66,21 @@ icon: "input-text"
- 選択フィールドは、事前定義されたオプションを含むドロップダウンメニューを表示します。ユーザーはリストされたオプションからのみ選択でき、データの一貫性を確保し、無効な入力を防ぎます。
+ 事前定義されたオプションを含むドロップダウンメニューを表示します。ユーザーはリストされたオプションからのみ選択でき、データの一貫性を確保し、無効な入力を防ぎます。
- 数値フィールドは数値のみに入力を制限します—数量、評価、ID、または数学的処理を必要とするデータに最適です。
+ 数値のみに入力を制限します。数量、評価、ID、または数学的処理を必要とするデータに最適です。
- チェックボックスフィールドは、シンプルなはい/いいえオプションを提供します。ユーザーがボックスをチェックすると、出力は `true` になります。それ以外の場合は `false` になります。確認や二者択一が必要な場合に使用します。
+ シンプルなはい/いいえオプションを提供します。ユーザーがボックスをチェックすると、出力は `true` になり、それ以外の場合は `false` になります。確認や二者択一が必要な場合に使用します。
+
+
+
+ JSON オブジェクト形式のデータを受け付けます。複雑でネストされたデータ構造をアプリケーションに渡すのに最適です。
+
+ オプションで JSON スキーマを定義して、入力を検証し、期待される構造についてユーザーをガイドできます。これにより、他のノードでオブジェクトの個々のプロパティを参照することもできます。
@@ -80,11 +88,12 @@ icon: "input-text"
- 単一ファイルフィールドを使用すると、ユーザーはデバイスまたはファイル URL を介して、サポートされている任意のタイプの 1 つのファイルをアップロードできます。アップロードされたファイルは、ファイルメタデータ(名前、サイズ、タイプなど)を含む変数として利用できます。
+ ユーザーはデバイスまたはファイル URL を介して、サポートされている任意のタイプの 1 つのファイルをアップロードできます。アップロードされたファイルは、ファイルメタデータ(名前、サイズ、タイプなど)を含む変数として利用できます。
- ファイルリストフィールドは単一ファイルと同様に機能しますが、一度に複数のファイルのアップロードをサポートします。ドキュメント、画像、その他のファイルのバッチを一緒に処理する場合に便利です。
+ 一度に複数のファイルのアップロードをサポートします。ドキュメント、画像、その他のファイルのバッチを一緒に処理する場合に便利です。
+
リスト演算子ノードを使用して、アップロードされたファイルリストから特定のファイルをフィルタリング、並べ替え、または抽出して、さらに処理することができます。
@@ -93,16 +102,16 @@ icon: "input-text"
**ファイル処理**
-ユーザー入力ノードを介してアップロードされたファイルは、後続のノードによって適切に処理される必要があります。ユーザー入力ノードはファイルを収集するだけで、コンテンツを読み取ったり解析したりしません。
-
-したがって、ファイルコンテンツを抽出して処理するために特定のノードを接続する必要があります。例えば:
+ユーザー入力ノードはファイルを収集するだけで、コンテンツを読み取ったり解析したりしないため、アップロードされたファイルは後続のノードによって適切に処理される必要があります。例えば:
- ドキュメントファイルは、LLM がそのコンテンツを理解できるように、テキスト抽出のためにドキュメント抽出器ノードにルーティングできます。
+
- 画像は、ビジョン機能を持つ LLM ノードまたは専用の画像処理ツールノードに送信できます。
+
- CSV や JSON などの構造化データファイルは、コードノードを使用して解析および変換できます。
- ユーザーが混在タイプの複数のファイル(画像とドキュメントなど)をアップロードする場合、リスト演算子ノードを使用してファイルタイプ別に分離してから、適切な処理ブランチにルーティングできます。
+ ユーザーが混在タイプの複数のファイル(画像とドキュメントなど)をアップロードする場合、リスト演算子ノードを使用してファイルタイプ別に分離してから、異なる処理ブランチにルーティングできます。
## 次のステップ
@@ -110,5 +119,7 @@ icon: "input-text"
ユーザー入力ノードを設定したら、収集したデータを処理する他のノードに接続できます。一般的なパターンには次のものがあります:
- 入力を LLM ノードに送信して処理する。
-- ナレッジ検索ノードを使用して、入力に基づいて関連情報を検索する。
-- 入力に基づいて条件ロジックを使用して実行パスを異なるブランチにルーティングする。
+
+- ナレッジ検索ノードを使用して、入力に関連する情報を検索する。
+
+- If/Else ノードを使用して、入力に基づいて条件分岐を作成する。
\ No newline at end of file
diff --git a/ja/use-dify/nodes/variable-aggregator.mdx b/ja/use-dify/nodes/variable-aggregator.mdx
index 0c7db92c0..7efce6a75 100644
--- a/ja/use-dify/nodes/variable-aggregator.mdx
+++ b/ja/use-dify/nodes/variable-aggregator.mdx
@@ -6,7 +6,6 @@ icon: "merge"
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/variable-aggregator)を参照してください。
-
変数アグリゲーターノードは、異なる実行パスからの変数を単一の統一された出力に結合します。複数のブランチが類似の出力を生成する場合、このノードは一つの一貫した変数参照を作成することで、下流での重複処理の必要性を排除します。
## 分岐の問題
@@ -52,9 +51,10 @@ icon: "merge"
**同一型ルール** - すべての集約された変数は同じデータ型である必要があります。最初の変数(例:文字列)を接続すると、ノードは他のブランチから同じ型の変数のみを受け入れます。
**サポートされる型:**
-- **文字列** - 異なる処理力
+- **文字列** - 異なる処理ブランチからのテキスト出力
- **数値** - 数値計算、スコア、または測定値
- **オブジェクト** - 類似のスキーマを持つ構造化データオブジェクト
+- **ブール値** - True/false値
- **配列** - リスト、コレクション、または複数の結果
### 出力動作
@@ -67,24 +67,4 @@ icon: "merge"
高度なワークフロー(v0.6.10+)では、複数の変数グループを同時に集約できます。各グループは独自の型制約を維持し、同一ノード内で異なるデータ型を並行して集約することができます。
-これは、ブランチが複数の関連する出力を生成し、それらを個別に結合する必要がある場合に便利です - たとえば、異なる処理パスからのテキスト要約と数値スコアの両方を集約する場合です。
-
-## 一般的な使用例
-
-**マルチカテゴリ処理** - 異なるコンテンツタイプには専用の処理が必要ですが、共通の下流ロジックに供給される類似の出力を生成します。
-
-**条件付きデータソース** - 異なる条件が異なる知識検索やAPI呼び出しをトリガーしますが、すべての結果には同じ最終処理が必要です。
-
-**ブランチ結果の統合** - 複雑な分岐ロジックがさまざまな出力を生成しますが、最終的には統一された処理が必要です。
-
-**エラー処理** - メイン処理とフォールバックブランチが異なるが互換性のある結果を生成し、下流ノードが一貫して処理できます。
-
-## ベストプラクティス
-
-**データ型の計画** - 変数アグリゲーターに接続する前に、すべてのブランチが互換性のあるデータ型を生成することを確認します。
-
-**一貫した出力構造** - オブジェクトや配列を集約する際は、予測可能な下流処理のためにすべてのブランチで一貫した構造を維持します。
-
-**説明的な名前を使用** - 集約された変数には、複数の可能なソースからの結果を含むことを明確に示す名前を付けます。
-
-**すべてのブランチをテスト** - 各可能な実行パスが、集約時に正しく動作する有効な出力を生成することを確認します。
+これは、ブランチが複数の関連する出力を生成し、それらを個別に結合する必要がある場合に便利です - たとえば、異なる処理パスからのテキスト要約と数値スコアの両方を集約する場合です。
\ No newline at end of file
diff --git a/ja/use-dify/nodes/variable-assigner.mdx b/ja/use-dify/nodes/variable-assigner.mdx
index 8f8e58e4f..c05106c60 100644
--- a/ja/use-dify/nodes/variable-assigner.mdx
+++ b/ja/use-dify/nodes/variable-assigner.mdx
@@ -6,8 +6,7 @@ icon: "pen-to-square"
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/variable-assigner)を参照してください。
-
-変数アサイナーノードは、会話変数への書き込み(さまざまなタイプの変数については[こちら](jp/use-dify/getting-started/key-concepts#variables)を参照)によってチャットフローアプリケーションの永続的なデータを管理します。各実行でリセットされる通常のワークフロー変数とは異なり、会話変数はチャットセッション全体を通じて持続します。
+変数アサイナーノードは、会話変数への書き込み(さまざまなタイプの変数については[こちら](/ja/use-dify/getting-started/key-concepts#変数)を参照)によってチャットフローアプリケーションの永続的なデータを管理します。各実行でリセットされる通常のワークフロー変数とは異なり、会話変数はチャットセッション全体を通じて持続します。
 @@ -40,52 +39,64 @@ icon: "pen-to-square"
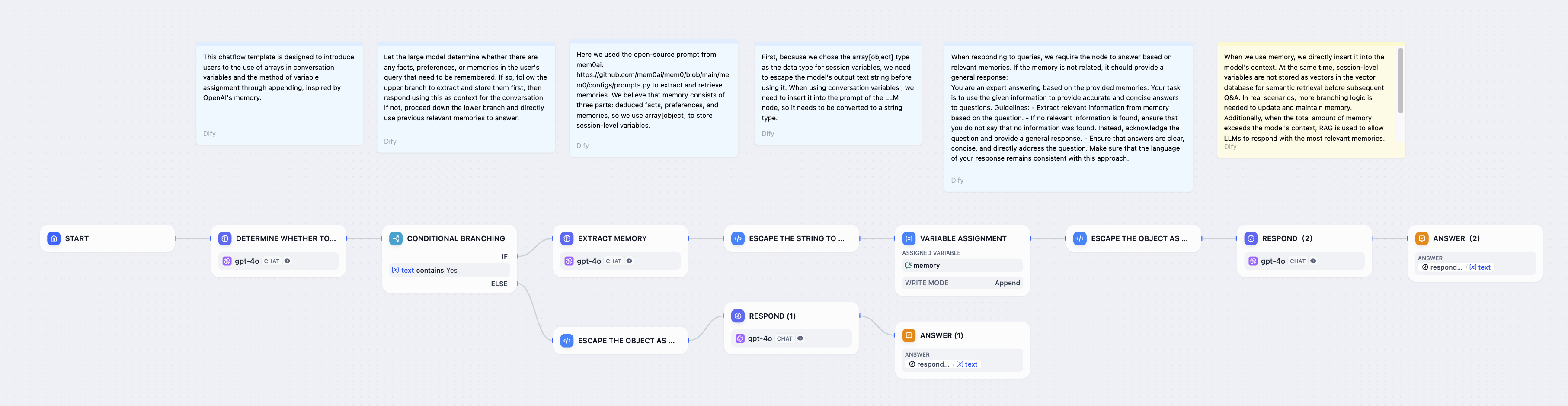
異なる変数タイプは、そのデータ構造に基づいて異なる操作をサポートします:
-
- **上書き** - 文字列値全体を新しいコンテンツで置き換える
+
+ - **上書き** - 別の文字列変数で置き換える
- **クリア** - 変数を空にし、nullまたは空白に設定する
+ - **クリア** - 現在の値を削除する
- **設定** - 固定値を手動で入力する
+ - **設定** - 固定値を手動で割り当てる
-
- **上書き** - 数値を完全に置き換える
+
+ - **上書き** - 別の数値変数で置き換える
- **クリア** - nullまたは空の状態に設定する
+ - **クリア** - 現在の値を削除する
- **設定** - 特定の数値を手動で入力する
+ - **設定** - 固定値を手動で割り当てる
- **算術演算** - 現在の値に対して加算、減算、乗算、除算を行う
+ - **算術演算** - 現在の値に対して別の数値で加算、減算、乗算、除算を行う
+
+
+
+ - **上書き** - 別のブール変数で置き換える
+
+ - **クリア** - 現在の値を削除する
+
+ - **設定** - 固定値を手動で割り当てる
-
- **上書き** - オブジェクト全体を新しいデータで置き換える
+
+ - **上書き** - 別のオブジェクト変数で置き換える
- **クリア** - オブジェクトを空にし、すべてのプロパティを削除する
+ - **クリア** - 現在の値を削除する
- **設定** - オブジェクトの構造と値を手動で定義する
+ - **設定** - オブジェクトの構造と値を手動で定義する
-
- **上書き** - 配列全体を新しいデータで置き換える
+
+ - **上書き** - 同じタイプの別の配列変数で置き換える
- **クリア** - 配列を空にし、すべての要素を削除する
+ - **クリア** - 配列からすべての要素を削除する
- **追加** - 配列の最後に1つの項目を追加する
+ - **追加** - 配列の最後に1つの要素を追加する
- **拡張** - 他の配列から複数の項目を追加する
+ - **拡張** - 同じタイプの別の配列からすべての要素を追加する
- **削除** - 最初または最後の位置から項目を削除する
+ - **最初/最後を削除** - 配列から最初または最後の要素を削除する
+
+
+ 配列操作は、時間の経過とともに成長するメモリシステム、チェックリスト、会話履歴の構築において特に強力です。
+
+
-配列操作は、時間の経過とともに成長するメモリシステム、チェックリスト、会話履歴の構築において特に強力です。
## 一般的な実装パターン
### スマートメモリシステム
-会話から重要な情報を自動的に検出・
+会話から重要な情報を自動的に検出・保存するチャットボットを構築:
@@ -40,52 +39,64 @@ icon: "pen-to-square"
異なる変数タイプは、そのデータ構造に基づいて異なる操作をサポートします:
-
- **上書き** - 文字列値全体を新しいコンテンツで置き換える
+
+ - **上書き** - 別の文字列変数で置き換える
- **クリア** - 変数を空にし、nullまたは空白に設定する
+ - **クリア** - 現在の値を削除する
- **設定** - 固定値を手動で入力する
+ - **設定** - 固定値を手動で割り当てる
-
- **上書き** - 数値を完全に置き換える
+
+ - **上書き** - 別の数値変数で置き換える
- **クリア** - nullまたは空の状態に設定する
+ - **クリア** - 現在の値を削除する
- **設定** - 特定の数値を手動で入力する
+ - **設定** - 固定値を手動で割り当てる
- **算術演算** - 現在の値に対して加算、減算、乗算、除算を行う
+ - **算術演算** - 現在の値に対して別の数値で加算、減算、乗算、除算を行う
+
+
+
+ - **上書き** - 別のブール変数で置き換える
+
+ - **クリア** - 現在の値を削除する
+
+ - **設定** - 固定値を手動で割り当てる
-
- **上書き** - オブジェクト全体を新しいデータで置き換える
+
+ - **上書き** - 別のオブジェクト変数で置き換える
- **クリア** - オブジェクトを空にし、すべてのプロパティを削除する
+ - **クリア** - 現在の値を削除する
- **設定** - オブジェクトの構造と値を手動で定義する
+ - **設定** - オブジェクトの構造と値を手動で定義する
-
- **上書き** - 配列全体を新しいデータで置き換える
+
+ - **上書き** - 同じタイプの別の配列変数で置き換える
- **クリア** - 配列を空にし、すべての要素を削除する
+ - **クリア** - 配列からすべての要素を削除する
- **追加** - 配列の最後に1つの項目を追加する
+ - **追加** - 配列の最後に1つの要素を追加する
- **拡張** - 他の配列から複数の項目を追加する
+ - **拡張** - 同じタイプの別の配列からすべての要素を追加する
- **削除** - 最初または最後の位置から項目を削除する
+ - **最初/最後を削除** - 配列から最初または最後の要素を削除する
+
+
+ 配列操作は、時間の経過とともに成長するメモリシステム、チェックリスト、会話履歴の構築において特に強力です。
+
+
-配列操作は、時間の経過とともに成長するメモリシステム、チェックリスト、会話履歴の構築において特に強力です。
## 一般的な実装パターン
### スマートメモリシステム
-会話から重要な情報を自動的に検出・
+会話から重要な情報を自動的に検出・保存するチャットボットを構築:
 @@ -101,7 +112,7 @@ icon: "pen-to-square"
@@ -101,7 +112,7 @@ icon: "pen-to-square"
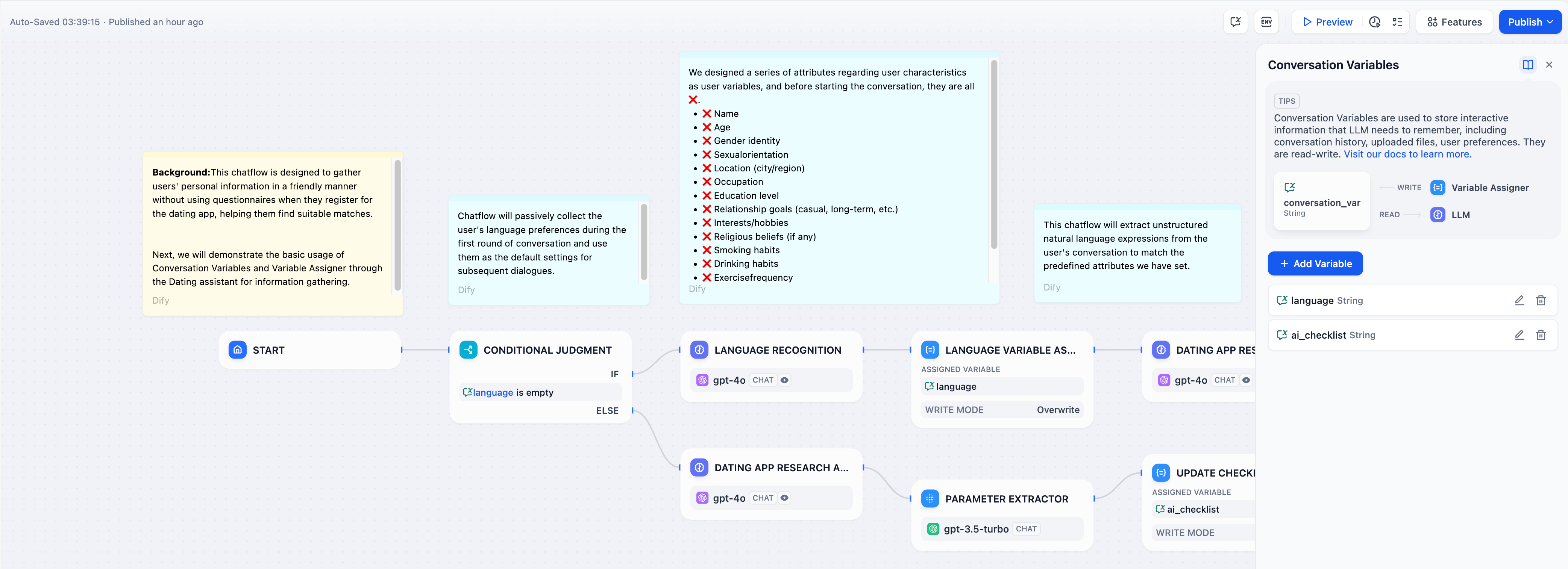 -**上書き**モードを使用してユーザー入力から初期設定をキャプチャし、パーソナライズされたインタラクションのために後続のすべての大規模言語モデルレスポンスでそれらを参照します。
+**上書き**モードを使用してユーザー入力から初期設定をキャプチャし、パーソナライズされたインタラクションのために後続のすべてのLLMレスポンスでそれらを参照します。
### 段階的チェックリスト
@@ -111,16 +122,4 @@ icon: "pen-to-square"
-**上書き**モードを使用してユーザー入力から初期設定をキャプチャし、パーソナライズされたインタラクションのために後続のすべての大規模言語モデルレスポンスでそれらを参照します。
+**上書き**モードを使用してユーザー入力から初期設定をキャプチャし、パーソナライズされたインタラクションのために後続のすべてのLLMレスポンスでそれらを参照します。
### 段階的チェックリスト
@@ -111,16 +122,4 @@ icon: "pen-to-square"
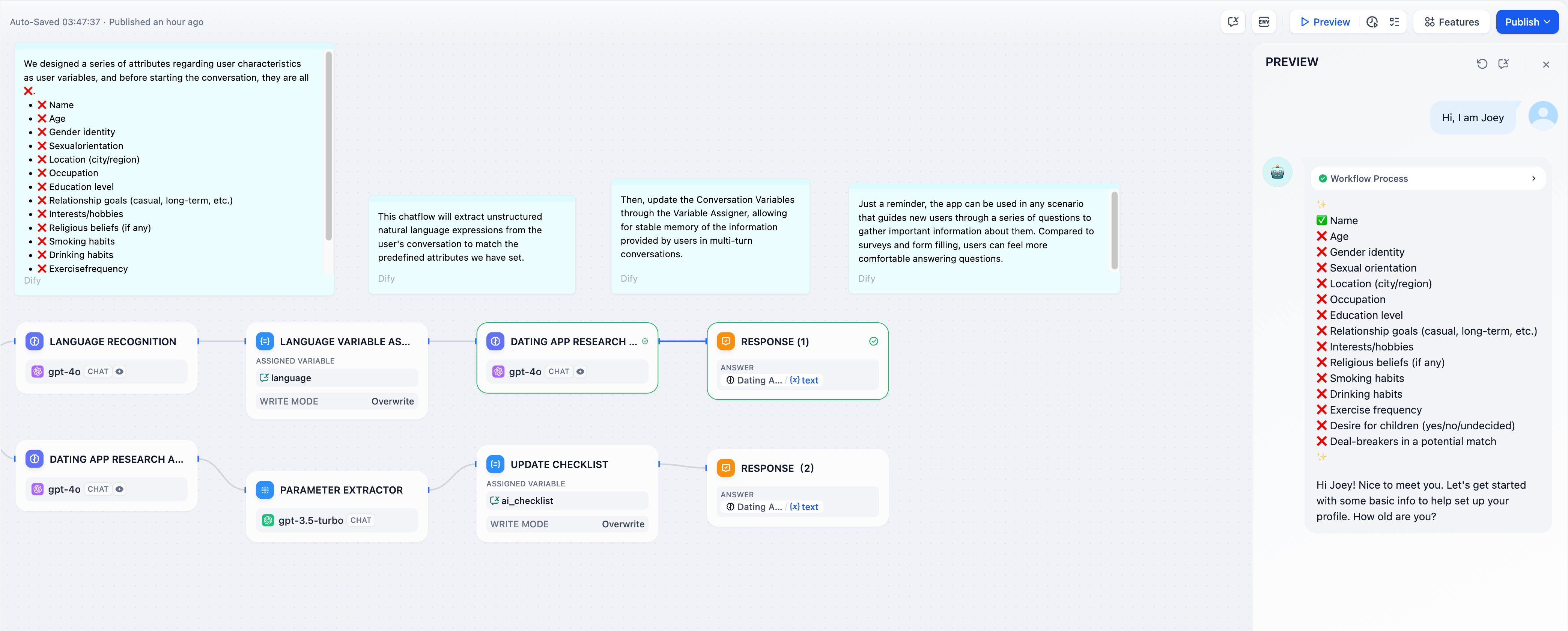 -配列会話変数を使用して完了した項目を追跡します。変数アサイナーは各ターンでチェックリストを更新し、大規模言語モデルはそれを参照してユーザーを残りのタスクを通じてガイドします。
-
-## ベストプラクティス
-
-**適切なデータタイプを選択** - 成長するコレクションには配列を、構造化データにはオブジェクトを、単一値には単純型を使用する。
-
-**説明的な変数名を使用** - 会話変数の目的と内容を示すように明確に命名する。
-
-**データの成長を処理** - 長い会話での過度なメモリ使用を防ぐため、配列とオブジェクトのサイズを監視する。
-
-**変数を初期化** - 未定義の動作を防ぐため、会話変数に初期値を設定する。
-
-**適切な場合にクリア** - 新しいプロセスやセッションを開始する際に変数をリセットするためにクリア操作を使用する。
+配列会話変数を使用して完了した項目を追跡します。変数アサイナーは各ターンでチェックリストを更新し、LLMはそれを参照してユーザーを残りのタスクを通じてガイドします。
diff --git a/zh/use-dify/nodes/ifelse.mdx b/zh/use-dify/nodes/ifelse.mdx
index fdce7609f..6f01e635b 100644
--- a/zh/use-dify/nodes/ifelse.mdx
+++ b/zh/use-dify/nodes/ifelse.mdx
@@ -1,11 +1,11 @@
---
title: "If-Else"
+description: "为工作流添加条件逻辑和分支"
icon: "code-branch"
---
⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/nodes/ifelse)。
-
If-Else 节点通过根据你定义的条件将执行路由到不同路径,为你的工作流添加决策逻辑。它评估变量并确定你的工作流应该遵循哪个分支。
@@ -28,11 +28,11 @@ If-Else 节点通过根据你定义的条件将执行路由到不同路径,为
- **包含** / **不包含** - 检查文本是否包含特定词语或短语
+ **包含** / **不包含** - 检查值是否包含特定词语或短语
**开头为** / **结尾为** - 测试文本开头或结尾的模式匹配
- **是** / **不是** - 用于精确文本比较的确切值匹配
+ **是** / **不是** - 精确值匹配
@@ -60,16 +60,4 @@ If-Else 节点通过根据你定义的条件将执行路由到不同路径,为
在你的条件中引用来自先前工作流节点的任何变量。变量可以来自用户输入、大型语言模型响应、API 调用或任何其他工作流节点输出。
-使用变量选择器从可用变量中选择,或使用 `{{variable_name}}` 语法直接键入变量名称。
-
-## 常见模式
-
-**内容路由** - 根据类别、语言或复杂性将不同类型的内容导向专门的处理节点。
-
-**用户角色管理** - 根据用户权限、订阅级别或账户类型实现不同的工作流行为。
-
-**错误处理** - 检查响应状态代码、数据有效性或处理结果以适当地路由工作流。
-
-**动态处理** - 根据输入特征、处理结果或外部条件调整工作流行为。
-
-**多路径工作流** - 创建复杂的分支逻辑,处理应用程序中的各种场景和边界情况。
+使用变量选择器从可用变量中选择,或使用 `{{variable_name}}` 语法直接键入变量名称。
\ No newline at end of file
diff --git a/zh/use-dify/nodes/list-operator.mdx b/zh/use-dify/nodes/list-operator.mdx
index bcf7a3238..3d22707ee 100644
--- a/zh/use-dify/nodes/list-operator.mdx
+++ b/zh/use-dify/nodes/list-operator.mdx
@@ -1,13 +1,15 @@
---
title: "列表操作符"
+description: "筛选、排序和选择数组中的元素"
icon: "filter"
---
⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/nodes/list-operator)。
-
列表操作符节点通过筛选、排序和选择特定元素来处理数组。当你需要处理混合文件上传、大型数据集或任何需要在下游处理之前进行分离或组织的数组数据时,请使用它。
+支持的输入数据类型包括 `array[string]`、`array[number]`、`array[file]` 和 `array[boolean]`。
+
@@ -22,16 +24,6 @@ icon: "filter"
-## 支持的数据类型
-
-该节点处理不同的数组类型,并提供相应的筛选选项:
-
-**Array[string]** - 文本列表、类别、名称或任何字符串集合
-
-**Array[number]** - 数值数据、分数、测量值或计算结果
-
-**Array[file]** - 具有丰富元数据筛选功能的混合文件上传
-
## 操作
### 筛选
@@ -99,26 +91,4 @@ icon: "filter"
3. **适当处理** - 图像被直接分析,文档进行文本提取
4. **合并结果** - 将处理后的输出合并为统一响应
-这种模式自动将不同文,创建无缝的多模态用户体验。
-
-## 常见用例
-
-**文件类型路由** - 根据内容类型将混合上传分离到专门的处理管道中。
-
-**数据筛选** - 根据特定条件从大型数据集中提取相关子集。
-
-**内容优先级排序** - 从集合中排序并选择最重要或最近的项目。
-
-**质量控制** - 在处理前筛选出无效、超大或不支持的内容。
-
-**批处理准备** - 将数据组织成可管理的块,用于下游迭代或并行处理。
-
-## 最佳实践
-
-**规划筛选条件** - 根据下游处理要求定义清晰的筛选规则。
-
-**使用适当的输出类型** - 根据下游节点如何使用数据,选择完整数组、第一条记录或最后一条记录。
-
-**处理空结果** - 考虑筛选器返回无匹配时会发生什么,并规划适当的后备逻辑。
-
-**使用真实数据测试** - 使用实际用户上传验证筛选行为,确保在生产环境中可靠运行。
+这种模式自动将不同文件类型路由到适当的处理器,创建无缝的多模态用户体验。
\ No newline at end of file
diff --git a/zh/use-dify/nodes/user-input.mdx b/zh/use-dify/nodes/user-input.mdx
index 0e3def687..2c167542c 100644
--- a/zh/use-dify/nodes/user-input.mdx
+++ b/zh/use-dify/nodes/user-input.mdx
@@ -1,6 +1,6 @@
---
title: "用户输入"
-description: "工作流和对话流应用程序的入口点"
+description: "收集用户输入以启动工作流和对话流应用程序"
icon: "input-text"
---
@@ -8,9 +8,11 @@ icon: "input-text"
## 简介
-用户输入节点是一种开始节点,你可以在其中定义应用程序运行时从最终用户收集的信息。
+用户输入节点允许你定义从最终用户收集哪些内容作为应用程序的输入。
-使用此节点启动的应用程序按需运行,通过直接用户交互或 API 调用启动。你还可以将这些应用程序发布为独立的 Web 应用程序或 MCP 服务器,通过后端服务 API 公开它们,或在其他 Dify 应用程序中作为工具使用。
+使用此节点启动的应用程序*按需*运行,可以通过直接用户交互或 API 调用启动。
+
+你还可以将这些应用程序发布为独立的 Web 应用程序或 MCP 服务器,通过后端服务 API 公开它们,或在其他 Dify 应用程序中作为工具使用。
每个应用程序画布只能包含一个用户输入节点。
@@ -34,16 +36,16 @@ icon: "input-text"
### 自定义
-你可以在用户输入节点中配置自定义输入字段,以从最终用户收集信息。每个字段都会成为下游节点可以引用的变量。例如,如果你添加一个变量名为 `user_name` 的输入字段,你可以在整个工作流中将其引用为 `{{user_name}}`。
-
-你可以选择七种类型的输入字段来处理不同类型的用户输入。
+你可以在用户输入节点中配置自定义输入字段,以收集不同类型的用户输入。每个字段都会成为下游节点可以引用的变量。
**标签名称**会显示给你的最终用户。
- 在对话流应用程序中,你可以**隐藏**任何输入变量,使其对最终用户不可见,同时保持在对话流中可引用。
+ 在对话流应用程序中,你可以**隐藏**任何用户输入字段,使其对最终用户不可见,同时保持在对话流中可引用。
+
+ 请注意,**必填**字段无法隐藏。
#### 文本输入
@@ -51,11 +53,11 @@ icon: "input-text"
- 短文本字段接受最多 256 个字符。用于姓名、电子邮件地址、标题或任何单行的简短文本输入。
+ 接受最多 256 个字符。用于姓名、电子邮件地址、标题或任何单行的简短文本输入。
- 段落字段允许无长度限制的长文本。它为用户提供多行文本区域,用于详细响应或描述。
+ 允许无长度限制的长文本。它为用户提供多行文本区域,用于详细响应或描述。
@@ -64,15 +66,21 @@ icon: "input-text"
- 选择字段显示带有预定义选项的下拉菜单。用户只能从列出的选项中选择,确保数据一致性并防止无效输入。
+ 显示带有预定义选项的下拉菜单。用户只能从列出的选项中选择,确保数据一致性并防止无效输入。
- 数字字段仅限数值输入——适用于数量、评分、ID 或任何需要数学处理的数据。
+ 仅限数值输入——适用于数量、评分、ID 或任何需要数学处理的数据。
- 复选框字段提供简单的是/否选项。当用户选中该框时,输出为 `true`;否则为 `false`。用于确认或任何需要二元选择的情况。
+ 提供简单的是/否选项。当用户选中该框时,输出为 `true`;否则为 `false`。用于确认或任何需要二元选择的情况。
+
+
+
+ 接受 JSON 对象格式的数据,适用于将复杂的嵌套数据结构传递到你的应用程序。
+
+ 你可以选择定义 JSON schema 来验证输入并指导用户了解预期的结构。这也允许你在其他节点中引用对象的各个属性。
@@ -80,29 +88,30 @@ icon: "input-text"
- 单文件字段允许用户上传任何支持类型的一个文件,可以从设备上传或通过文件 URL。上传的文件作为包含文件元数据(名称、大小、类型等)的变量可用。
+ 允许用户上传任何支持类型的一个文件,可以从设备上传或通过文件 URL。上传的文件作为包含文件元数据(名称、大小、类型等)的变量可用。
- 文件列表字段的工作方式类似于单文件,但支持一次上传多个文件。它适用于批量处理文档、图像或其他文件。
+ 支持一次上传多个文件。它适用于批量处理文档、图像或其他文件。
+
- 你可以使用列表操作符节点来过滤、排序或提取上传文件列表中的特定文件以进行进一步处理。
+ 使用列表操作符节点来过滤、排序或提取上传文件列表中的特定文件以进行进一步处理。
**文件处理**
-通过用户输入节点上传的文件必须由后续节点适当处理。用户输入节点仅收集文件;它不读取或解析其内容。
-
-因此,你需要连接特定节点来提取和处理文件内容。例如:
+由于用户输入节点仅收集文件——它不读取或解析其内容——上传的文件必须由后续节点适当处理。例如:
- 文档文件可以路由到文档提取器节点以进行文本提取,以便 LLM 能够理解其内容。
+
- 图像可以发送到具有视觉能力的 LLM 节点或专门的图像处理工具节点。
+
- CSV 或 JSON 等结构化数据文件可以使用代码节点进行解析和转换。
- 当用户上传混合类型的多个文件(例如,图像和文档)时,你可以使用列表操作符节点按文件类型分离它们,然后将它们路由到适当的处理分支。
+ 当用户上传混合类型的多个文件(例如,图像和文档)时,你可以使用列表操作符节点按文件类型分离它们,然后将它们路由到不同的处理分支。
## 下一步
@@ -110,5 +119,7 @@ icon: "input-text"
设置用户输入节点后,你可以将其连接到其他节点以处理收集的数据。常见模式包括:
- 将输入发送到 LLM 节点进行处理。
-- 使用知识检索节点根据输入查找相关信息。
-- 根据输入使用条件逻辑将执行路径路由到不同的分支。
+
+- 使用知识检索节点查找与输入相关的信息。
+
+- 使用 If/Else 节点根据输入创建条件分支。
\ No newline at end of file
diff --git a/zh/use-dify/nodes/variable-aggregator.mdx b/zh/use-dify/nodes/variable-aggregator.mdx
index 365179d97..deb9c432e 100644
--- a/zh/use-dify/nodes/variable-aggregator.mdx
+++ b/zh/use-dify/nodes/variable-aggregator.mdx
@@ -1,11 +1,11 @@
---
title: "变量聚合器"
+description: "将来自不同工作流分支的变量组合成统一输出"
icon: "merge"
---
⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/nodes/variable-aggregator)。
-
变量聚合器节点将来自不同执行路径的变量组合成单一的统一输出。当多个分支产生相似输出时,该节点通过创建一个一致的变量引用,消除了对重复下游处理的需求。
## 分支问题
@@ -54,6 +54,7 @@ icon: "merge"
- **String** - 来自不同处理分支的文本输出
- **Number** - 数值计算、分数或测量值
- **Object** - 具有相似架构的结构化数据对象
+- **Boolean** - 真/假值
- **Array** - 列表、集合或多个结果
### 输出行为
@@ -66,24 +67,4 @@ icon: "merge"
高级工作流(v0.6.10+)可以同时聚合多组变量。每组都保持自己的类型约束,允许你在同一节点内并行聚合不同的数据类型。
-这在分支产生需要单独组合的多个相关输出时很有用 - 例如,从不同处理路径聚合文本摘要和数值分数。
-
-## 常见使用案例
-
-**多类别处理** - 不同内容类型需要专门处理,但产生类似的输出,这些输出馈入通用下游逻辑。
-
-**条件数据源** - 不同条件触发不同的知识检索或API调用,但所有结果都需要相同的最终处理。
-
-**分支结果整合** - 复杂的分支逻辑产生各种输出,最终需要统一处理。
-
-**错误处理** - 主处游节点可以一致地处理。
-
-## 最佳实践
-
-**规划数据类型** - 在连接到变量聚合器之前,确保所有分支都产生兼容的数据类型。
-
-**一致的输出结构** - 聚合对象或数组时,在所有分支中保持一致的结构,以实现可预测的下游处理。
-
-**使用描述性名称** - 清楚地命名聚合变量,以表明它们包含来自多个可能来源的结果。
-
-**测试所有分支** - 验证每个可能的执行路径都产生有效的输出,在聚合时能够正确工作。
+这在分支产生需要单独组合的多个相关输出时很有用 - 例如,从不同处理路径聚合文本摘要和数值分数。
\ No newline at end of file
diff --git a/zh/use-dify/nodes/variable-assigner.mdx b/zh/use-dify/nodes/variable-assigner.mdx
index ce9a688b3..bc5d8954d 100644
--- a/zh/use-dify/nodes/variable-assigner.mdx
+++ b/zh/use-dify/nodes/variable-assigner.mdx
@@ -1,12 +1,12 @@
---
title: "变量赋值器"
+description: "在对话流应用中管理持久化会话变量"
icon: "pen-to-square"
---
⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/nodes/variable-assigner)。
-
-变量赋值器节点通过写入会话变量(在[这里](cn/use-dify/getting-started/key-concepts#variables)了解不同类型的变量)来管理对话流应用中的持久化数据。与每次执行都会重置的常规工作流变量不同,会话变量在整个聊天会话期间持续存在。
+变量赋值器节点通过写入会话变量(在[这里](/zh/use-dify/getting-started/key-concepts#变量)了解不同类型的变量)来管理对话流应用中的持久化数据。与每次执行都会重置的常规工作流变量不同,会话变量在整个聊天会话期间持续存在。
@@ -39,46 +39,58 @@ icon: "pen-to-square"
不同变量类型根据其数据结构支持不同的操作:
-
- **覆写** - 用新内容替换整个字符串值
+
+ - **覆写** - 用另一个字符串变量替换
- **清除** - 清空变量,将其设置为null或空白
+ - **清除** - 移除当前值
- **设置** - 手动输入固定值
+ - **设置** - 手动分配一个固定值
-
- **覆写** - 完全替换数字值
+
+ - **覆写** - 用另一个数字变量替换
- **清除** - 设置为null或空状态
+ - **清除** - 移除当前值
- **设置** - 手动输入特定数字值
+ - **设置** - 手动分配一个固定值
- **算术运算** - 对当前值进行加、减、乘、除操作
+ - **算术运算** - 对当前值进行加、减、乘、除操作
+
+
+
+ - **覆写** - 用另一个布尔变量替换
+
+ - **清除** - 移除当前值
+
+ - **设置** - 手动分配一个固定值
-
- **覆写** - 用新数据替换整个对象
+
+ - **覆写** - 用另一个对象变量替换
- **清除** - 清空对象,移除所有属性
+ - **清除** - 移除当前值
- **设置** - 手动定义对象结构和值
+ - **设置** - 手动定义对象结构和值
-
- **覆写** - 用新数据替换整个数组
+
+ - **覆写** - 用同类型的另一个数组变量替换
- **清除** - 清空数组,移除所有元素
+ - **清除** - 移除数组中的所有元素
- **追加** - 在数组末尾添加一个项目
+ - **追加** - 在数组末尾添加单个元素
- **扩展** - 从另一个数组添加多个项目
+ - **扩展** - 添加同类型另一个数组中的所有元素
- **移除** - 从第一个或最后一个位置删除项目
+ - **移除第一个/最后一个** - 移除数组中的第一个或最后一个元素
+
+
+ 数组操作在构建记忆系统、清单和随时间增长的对话历史记录方面特别强大。
+
+
-数组操作在构建记忆系统、清单和随时间增长的对话历史记录方面特别强大。
## 常见实现模式
@@ -100,7 +112,7 @@ icon: "pen-to-square"
-从用户输入中捕获初始偏好,然后在所有后续大型语言模型响应中引用它们,实现个性化交互。
+使用**覆写**模式从用户输入中捕获初始偏好,然后在所有后续大型语言模型响应中引用它们,实现个性化交互。
### 渐进式清单
@@ -111,15 +123,3 @@ icon: "pen-to-square"
使用数组会话变量跟踪已完成的项目。变量赋值器在每轮更新清单,而大型语言模型引用它来指导用户完成剩余任务。
-
-## 最佳实践
-
-**选择适当的数据类型** - 对于不断增长的集合使用数组,对于结构化数据使用对象,对于单个值使用简单类型。
-
-**使用描述性变量名** - 清晰地命名会话变量以表明其用途和内容。
-
-**处理数据增长** - 监控数组和对象大小,防止在长对话中过度使用内存。
-
-**初始化变量** - 为会话变量设置初始值以防止未定义行为。
-
-**适当时清除** - 在开始新流程或会话时使用清除操作来重置变量。
-配列会話変数を使用して完了した項目を追跡します。変数アサイナーは各ターンでチェックリストを更新し、大規模言語モデルはそれを参照してユーザーを残りのタスクを通じてガイドします。
-
-## ベストプラクティス
-
-**適切なデータタイプを選択** - 成長するコレクションには配列を、構造化データにはオブジェクトを、単一値には単純型を使用する。
-
-**説明的な変数名を使用** - 会話変数の目的と内容を示すように明確に命名する。
-
-**データの成長を処理** - 長い会話での過度なメモリ使用を防ぐため、配列とオブジェクトのサイズを監視する。
-
-**変数を初期化** - 未定義の動作を防ぐため、会話変数に初期値を設定する。
-
-**適切な場合にクリア** - 新しいプロセスやセッションを開始する際に変数をリセットするためにクリア操作を使用する。
+配列会話変数を使用して完了した項目を追跡します。変数アサイナーは各ターンでチェックリストを更新し、LLMはそれを参照してユーザーを残りのタスクを通じてガイドします。
diff --git a/zh/use-dify/nodes/ifelse.mdx b/zh/use-dify/nodes/ifelse.mdx
index fdce7609f..6f01e635b 100644
--- a/zh/use-dify/nodes/ifelse.mdx
+++ b/zh/use-dify/nodes/ifelse.mdx
@@ -1,11 +1,11 @@
---
title: "If-Else"
+description: "为工作流添加条件逻辑和分支"
icon: "code-branch"
---
⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/nodes/ifelse)。
-
If-Else 节点通过根据你定义的条件将执行路由到不同路径,为你的工作流添加决策逻辑。它评估变量并确定你的工作流应该遵循哪个分支。
@@ -28,11 +28,11 @@ If-Else 节点通过根据你定义的条件将执行路由到不同路径,为
- **包含** / **不包含** - 检查文本是否包含特定词语或短语
+ **包含** / **不包含** - 检查值是否包含特定词语或短语
**开头为** / **结尾为** - 测试文本开头或结尾的模式匹配
- **是** / **不是** - 用于精确文本比较的确切值匹配
+ **是** / **不是** - 精确值匹配
@@ -60,16 +60,4 @@ If-Else 节点通过根据你定义的条件将执行路由到不同路径,为
在你的条件中引用来自先前工作流节点的任何变量。变量可以来自用户输入、大型语言模型响应、API 调用或任何其他工作流节点输出。
-使用变量选择器从可用变量中选择,或使用 `{{variable_name}}` 语法直接键入变量名称。
-
-## 常见模式
-
-**内容路由** - 根据类别、语言或复杂性将不同类型的内容导向专门的处理节点。
-
-**用户角色管理** - 根据用户权限、订阅级别或账户类型实现不同的工作流行为。
-
-**错误处理** - 检查响应状态代码、数据有效性或处理结果以适当地路由工作流。
-
-**动态处理** - 根据输入特征、处理结果或外部条件调整工作流行为。
-
-**多路径工作流** - 创建复杂的分支逻辑,处理应用程序中的各种场景和边界情况。
+使用变量选择器从可用变量中选择,或使用 `{{variable_name}}` 语法直接键入变量名称。
\ No newline at end of file
diff --git a/zh/use-dify/nodes/list-operator.mdx b/zh/use-dify/nodes/list-operator.mdx
index bcf7a3238..3d22707ee 100644
--- a/zh/use-dify/nodes/list-operator.mdx
+++ b/zh/use-dify/nodes/list-operator.mdx
@@ -1,13 +1,15 @@
---
title: "列表操作符"
+description: "筛选、排序和选择数组中的元素"
icon: "filter"
---
⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/nodes/list-operator)。
-
列表操作符节点通过筛选、排序和选择特定元素来处理数组。当你需要处理混合文件上传、大型数据集或任何需要在下游处理之前进行分离或组织的数组数据时,请使用它。
+支持的输入数据类型包括 `array[string]`、`array[number]`、`array[file]` 和 `array[boolean]`。
+
@@ -22,16 +24,6 @@ icon: "filter"
-## 支持的数据类型
-
-该节点处理不同的数组类型,并提供相应的筛选选项:
-
-**Array[string]** - 文本列表、类别、名称或任何字符串集合
-
-**Array[number]** - 数值数据、分数、测量值或计算结果
-
-**Array[file]** - 具有丰富元数据筛选功能的混合文件上传
-
## 操作
### 筛选
@@ -99,26 +91,4 @@ icon: "filter"
3. **适当处理** - 图像被直接分析,文档进行文本提取
4. **合并结果** - 将处理后的输出合并为统一响应
-这种模式自动将不同文,创建无缝的多模态用户体验。
-
-## 常见用例
-
-**文件类型路由** - 根据内容类型将混合上传分离到专门的处理管道中。
-
-**数据筛选** - 根据特定条件从大型数据集中提取相关子集。
-
-**内容优先级排序** - 从集合中排序并选择最重要或最近的项目。
-
-**质量控制** - 在处理前筛选出无效、超大或不支持的内容。
-
-**批处理准备** - 将数据组织成可管理的块,用于下游迭代或并行处理。
-
-## 最佳实践
-
-**规划筛选条件** - 根据下游处理要求定义清晰的筛选规则。
-
-**使用适当的输出类型** - 根据下游节点如何使用数据,选择完整数组、第一条记录或最后一条记录。
-
-**处理空结果** - 考虑筛选器返回无匹配时会发生什么,并规划适当的后备逻辑。
-
-**使用真实数据测试** - 使用实际用户上传验证筛选行为,确保在生产环境中可靠运行。
+这种模式自动将不同文件类型路由到适当的处理器,创建无缝的多模态用户体验。
\ No newline at end of file
diff --git a/zh/use-dify/nodes/user-input.mdx b/zh/use-dify/nodes/user-input.mdx
index 0e3def687..2c167542c 100644
--- a/zh/use-dify/nodes/user-input.mdx
+++ b/zh/use-dify/nodes/user-input.mdx
@@ -1,6 +1,6 @@
---
title: "用户输入"
-description: "工作流和对话流应用程序的入口点"
+description: "收集用户输入以启动工作流和对话流应用程序"
icon: "input-text"
---
@@ -8,9 +8,11 @@ icon: "input-text"
## 简介
-用户输入节点是一种开始节点,你可以在其中定义应用程序运行时从最终用户收集的信息。
+用户输入节点允许你定义从最终用户收集哪些内容作为应用程序的输入。
-使用此节点启动的应用程序按需运行,通过直接用户交互或 API 调用启动。你还可以将这些应用程序发布为独立的 Web 应用程序或 MCP 服务器,通过后端服务 API 公开它们,或在其他 Dify 应用程序中作为工具使用。
+使用此节点启动的应用程序*按需*运行,可以通过直接用户交互或 API 调用启动。
+
+你还可以将这些应用程序发布为独立的 Web 应用程序或 MCP 服务器,通过后端服务 API 公开它们,或在其他 Dify 应用程序中作为工具使用。
每个应用程序画布只能包含一个用户输入节点。
@@ -34,16 +36,16 @@ icon: "input-text"
### 自定义
-你可以在用户输入节点中配置自定义输入字段,以从最终用户收集信息。每个字段都会成为下游节点可以引用的变量。例如,如果你添加一个变量名为 `user_name` 的输入字段,你可以在整个工作流中将其引用为 `{{user_name}}`。
-
-你可以选择七种类型的输入字段来处理不同类型的用户输入。
+你可以在用户输入节点中配置自定义输入字段,以收集不同类型的用户输入。每个字段都会成为下游节点可以引用的变量。
**标签名称**会显示给你的最终用户。
- 在对话流应用程序中,你可以**隐藏**任何输入变量,使其对最终用户不可见,同时保持在对话流中可引用。
+ 在对话流应用程序中,你可以**隐藏**任何用户输入字段,使其对最终用户不可见,同时保持在对话流中可引用。
+
+ 请注意,**必填**字段无法隐藏。
#### 文本输入
@@ -51,11 +53,11 @@ icon: "input-text"
- 短文本字段接受最多 256 个字符。用于姓名、电子邮件地址、标题或任何单行的简短文本输入。
+ 接受最多 256 个字符。用于姓名、电子邮件地址、标题或任何单行的简短文本输入。
- 段落字段允许无长度限制的长文本。它为用户提供多行文本区域,用于详细响应或描述。
+ 允许无长度限制的长文本。它为用户提供多行文本区域,用于详细响应或描述。
@@ -64,15 +66,21 @@ icon: "input-text"
- 选择字段显示带有预定义选项的下拉菜单。用户只能从列出的选项中选择,确保数据一致性并防止无效输入。
+ 显示带有预定义选项的下拉菜单。用户只能从列出的选项中选择,确保数据一致性并防止无效输入。
- 数字字段仅限数值输入——适用于数量、评分、ID 或任何需要数学处理的数据。
+ 仅限数值输入——适用于数量、评分、ID 或任何需要数学处理的数据。
- 复选框字段提供简单的是/否选项。当用户选中该框时,输出为 `true`;否则为 `false`。用于确认或任何需要二元选择的情况。
+ 提供简单的是/否选项。当用户选中该框时,输出为 `true`;否则为 `false`。用于确认或任何需要二元选择的情况。
+
+
+
+ 接受 JSON 对象格式的数据,适用于将复杂的嵌套数据结构传递到你的应用程序。
+
+ 你可以选择定义 JSON schema 来验证输入并指导用户了解预期的结构。这也允许你在其他节点中引用对象的各个属性。
@@ -80,29 +88,30 @@ icon: "input-text"
- 单文件字段允许用户上传任何支持类型的一个文件,可以从设备上传或通过文件 URL。上传的文件作为包含文件元数据(名称、大小、类型等)的变量可用。
+ 允许用户上传任何支持类型的一个文件,可以从设备上传或通过文件 URL。上传的文件作为包含文件元数据(名称、大小、类型等)的变量可用。
- 文件列表字段的工作方式类似于单文件,但支持一次上传多个文件。它适用于批量处理文档、图像或其他文件。
+ 支持一次上传多个文件。它适用于批量处理文档、图像或其他文件。
+
- 你可以使用列表操作符节点来过滤、排序或提取上传文件列表中的特定文件以进行进一步处理。
+ 使用列表操作符节点来过滤、排序或提取上传文件列表中的特定文件以进行进一步处理。
**文件处理**
-通过用户输入节点上传的文件必须由后续节点适当处理。用户输入节点仅收集文件;它不读取或解析其内容。
-
-因此,你需要连接特定节点来提取和处理文件内容。例如:
+由于用户输入节点仅收集文件——它不读取或解析其内容——上传的文件必须由后续节点适当处理。例如:
- 文档文件可以路由到文档提取器节点以进行文本提取,以便 LLM 能够理解其内容。
+
- 图像可以发送到具有视觉能力的 LLM 节点或专门的图像处理工具节点。
+
- CSV 或 JSON 等结构化数据文件可以使用代码节点进行解析和转换。
- 当用户上传混合类型的多个文件(例如,图像和文档)时,你可以使用列表操作符节点按文件类型分离它们,然后将它们路由到适当的处理分支。
+ 当用户上传混合类型的多个文件(例如,图像和文档)时,你可以使用列表操作符节点按文件类型分离它们,然后将它们路由到不同的处理分支。
## 下一步
@@ -110,5 +119,7 @@ icon: "input-text"
设置用户输入节点后,你可以将其连接到其他节点以处理收集的数据。常见模式包括:
- 将输入发送到 LLM 节点进行处理。
-- 使用知识检索节点根据输入查找相关信息。
-- 根据输入使用条件逻辑将执行路径路由到不同的分支。
+
+- 使用知识检索节点查找与输入相关的信息。
+
+- 使用 If/Else 节点根据输入创建条件分支。
\ No newline at end of file
diff --git a/zh/use-dify/nodes/variable-aggregator.mdx b/zh/use-dify/nodes/variable-aggregator.mdx
index 365179d97..deb9c432e 100644
--- a/zh/use-dify/nodes/variable-aggregator.mdx
+++ b/zh/use-dify/nodes/variable-aggregator.mdx
@@ -1,11 +1,11 @@
---
title: "变量聚合器"
+description: "将来自不同工作流分支的变量组合成统一输出"
icon: "merge"
---
⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/nodes/variable-aggregator)。
-
变量聚合器节点将来自不同执行路径的变量组合成单一的统一输出。当多个分支产生相似输出时,该节点通过创建一个一致的变量引用,消除了对重复下游处理的需求。
## 分支问题
@@ -54,6 +54,7 @@ icon: "merge"
- **String** - 来自不同处理分支的文本输出
- **Number** - 数值计算、分数或测量值
- **Object** - 具有相似架构的结构化数据对象
+- **Boolean** - 真/假值
- **Array** - 列表、集合或多个结果
### 输出行为
@@ -66,24 +67,4 @@ icon: "merge"
高级工作流(v0.6.10+)可以同时聚合多组变量。每组都保持自己的类型约束,允许你在同一节点内并行聚合不同的数据类型。
-这在分支产生需要单独组合的多个相关输出时很有用 - 例如,从不同处理路径聚合文本摘要和数值分数。
-
-## 常见使用案例
-
-**多类别处理** - 不同内容类型需要专门处理,但产生类似的输出,这些输出馈入通用下游逻辑。
-
-**条件数据源** - 不同条件触发不同的知识检索或API调用,但所有结果都需要相同的最终处理。
-
-**分支结果整合** - 复杂的分支逻辑产生各种输出,最终需要统一处理。
-
-**错误处理** - 主处游节点可以一致地处理。
-
-## 最佳实践
-
-**规划数据类型** - 在连接到变量聚合器之前,确保所有分支都产生兼容的数据类型。
-
-**一致的输出结构** - 聚合对象或数组时,在所有分支中保持一致的结构,以实现可预测的下游处理。
-
-**使用描述性名称** - 清楚地命名聚合变量,以表明它们包含来自多个可能来源的结果。
-
-**测试所有分支** - 验证每个可能的执行路径都产生有效的输出,在聚合时能够正确工作。
+这在分支产生需要单独组合的多个相关输出时很有用 - 例如,从不同处理路径聚合文本摘要和数值分数。
\ No newline at end of file
diff --git a/zh/use-dify/nodes/variable-assigner.mdx b/zh/use-dify/nodes/variable-assigner.mdx
index ce9a688b3..bc5d8954d 100644
--- a/zh/use-dify/nodes/variable-assigner.mdx
+++ b/zh/use-dify/nodes/variable-assigner.mdx
@@ -1,12 +1,12 @@
---
title: "变量赋值器"
+description: "在对话流应用中管理持久化会话变量"
icon: "pen-to-square"
---
⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/nodes/variable-assigner)。
-
-变量赋值器节点通过写入会话变量(在[这里](cn/use-dify/getting-started/key-concepts#variables)了解不同类型的变量)来管理对话流应用中的持久化数据。与每次执行都会重置的常规工作流变量不同,会话变量在整个聊天会话期间持续存在。
+变量赋值器节点通过写入会话变量(在[这里](/zh/use-dify/getting-started/key-concepts#变量)了解不同类型的变量)来管理对话流应用中的持久化数据。与每次执行都会重置的常规工作流变量不同,会话变量在整个聊天会话期间持续存在。
@@ -39,46 +39,58 @@ icon: "pen-to-square"
不同变量类型根据其数据结构支持不同的操作:
-
- **覆写** - 用新内容替换整个字符串值
+
+ - **覆写** - 用另一个字符串变量替换
- **清除** - 清空变量,将其设置为null或空白
+ - **清除** - 移除当前值
- **设置** - 手动输入固定值
+ - **设置** - 手动分配一个固定值
-
- **覆写** - 完全替换数字值
+
+ - **覆写** - 用另一个数字变量替换
- **清除** - 设置为null或空状态
+ - **清除** - 移除当前值
- **设置** - 手动输入特定数字值
+ - **设置** - 手动分配一个固定值
- **算术运算** - 对当前值进行加、减、乘、除操作
+ - **算术运算** - 对当前值进行加、减、乘、除操作
+
+
+
+ - **覆写** - 用另一个布尔变量替换
+
+ - **清除** - 移除当前值
+
+ - **设置** - 手动分配一个固定值
-
- **覆写** - 用新数据替换整个对象
+
+ - **覆写** - 用另一个对象变量替换
- **清除** - 清空对象,移除所有属性
+ - **清除** - 移除当前值
- **设置** - 手动定义对象结构和值
+ - **设置** - 手动定义对象结构和值
-
- **覆写** - 用新数据替换整个数组
+
+ - **覆写** - 用同类型的另一个数组变量替换
- **清除** - 清空数组,移除所有元素
+ - **清除** - 移除数组中的所有元素
- **追加** - 在数组末尾添加一个项目
+ - **追加** - 在数组末尾添加单个元素
- **扩展** - 从另一个数组添加多个项目
+ - **扩展** - 添加同类型另一个数组中的所有元素
- **移除** - 从第一个或最后一个位置删除项目
+ - **移除第一个/最后一个** - 移除数组中的第一个或最后一个元素
+
+
+ 数组操作在构建记忆系统、清单和随时间增长的对话历史记录方面特别强大。
+
+
-数组操作在构建记忆系统、清单和随时间增长的对话历史记录方面特别强大。
## 常见实现模式
@@ -100,7 +112,7 @@ icon: "pen-to-square"
-从用户输入中捕获初始偏好,然后在所有后续大型语言模型响应中引用它们,实现个性化交互。
+使用**覆写**模式从用户输入中捕获初始偏好,然后在所有后续大型语言模型响应中引用它们,实现个性化交互。
### 渐进式清单
@@ -111,15 +123,3 @@ icon: "pen-to-square"
使用数组会话变量跟踪已完成的项目。变量赋值器在每轮更新清单,而大型语言模型引用它来指导用户完成剩余任务。
-
-## 最佳实践
-
-**选择适当的数据类型** - 对于不断增长的集合使用数组,对于结构化数据使用对象,对于单个值使用简单类型。
-
-**使用描述性变量名** - 清晰地命名会话变量以表明其用途和内容。
-
-**处理数据增长** - 监控数组和对象大小,防止在长对话中过度使用内存。
-
-**初始化变量** - 为会话变量设置初始值以防止未定义行为。
-
-**适当时清除** - 在开始新流程或会话时使用清除操作来重置变量。