[toc]
Sharding-JDBC官方文档地址:https://shardingsphere.apache.org/document/current/cn/features/
其他文章:
分库分表基础:https://www.yuque.com/lexiangqizhong/java/pmbya5
数据库分库分表思路:https://www.cnblogs.com/butterfly100/p/9034281.html
-
垂直分库
由于垂直分表,还是将表放在同一个库中,表多了必然会造成CPU,内存,IO的竞争。
定义:通过按照业务将表进行分类,分布到不同的数据库上,每个库可以在不同的服务器上
优点:
- 解决业务的耦合,业务清晰
- 能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直分库一定程度的提升IO、数据库连接数、降低单机硬件资源的瓶颈
拆分原则:根据不同的业务进行拆分
-
水平分库
定义:把同一个表的数据按一定规则(比如 IDHash%库数量)拆分到不同的数据库中,每个库可以放在不同的服务器上
优点:
- 解决了单库大数据,高并发的性能瓶颈
- 减少了IO竞争,锁竞争,提高了系统稳定性,某个库出现问题,仍然有部分数据可用提高了系统的可用性
-
垂直分表
定义:将一个表按照字段分成多个表,每个表存储其中一部分字段
优点:
- 避免IO争抢,为什么大字段效率低,第一由于数据量本身大,需要更长的读取时间;第二跨页,页是数据库存储单位,很多查找及定位操作都是以页为单位,单页内的数据行越多数据库整体性能越好,而大字段占用空间大,单页内存储行数少,因此IO效率低;第三,数据库以行为单位将数据库加载到内存中,这样表中字段长度较短且访问频率较高,内存能加载更多的数据,命中率更高,减少了磁盘IO,从而提升数据库性能
- 减少锁表的几率,在通过update更新表字段的时候,会将该条记录锁定,而将字段拆分后,能减少锁表几率。如果通过冷热数据进行字段拆分,还将提供热数据的操作效率
常见拆分原则:
- 把不常用的字段单独放在一张表中
- 把text、blob等大字段拆分放入附表中
- 经常组合查询的列放入同一张表
-
水平分表
定义:在同一个库内,把同一个表的数据按一定规则拆分到多个表中
优点:
- 优化单一表数据量过大而产生的性能问题
- 避免IO争抢并减少锁表的几率
分库分表使用 like 查询是有限制的。目前 Shariding-JDBC 不支持 like 语句中包含分片键,但不包含分片键的 like 语句可以正确执行。 至于 like 性能问题,是与数据库相关的,Shariding-JDBC 仅仅是解析 SQL 以及路由至正确的数据源而已。 是否会查询所有的库和表是根据分片键决定的,如果 SQL 中不包括分片键,就会查询所有库和表,这个和是否有 like 没有关系。
从设计理念上看确实有一定的相似性。
主要流程都是 SQL 解析 -> SQL 改写 -> SQL 路由 -> SQL 执行 -> 结果归并。但架构设计上是不同的。

Mycat 是基于 Proxy,它复写了 MySQL 协议,将 Mycat Server 伪装成一个 MySQL 数据库,而 Sharding-JDBC 是基于 JDBC 接口的扩展,是以 jar 包的形式提供轻量级服务的。
SQL 解析这块,现在的 Shariding-JDBC 和 Mycat 也比较相似,都是使用 Druid 作为 SQL 解析的基础类库。但 Sharding-JDBC 正在重写 SQL 解析这块,是去掉 Duird 的完全自研版本。不可否认 Druid 是一个优秀的连接池,而且 SQL 解析这块做得也很强,但它毕竟不是一个专门为了 Sharding 而做的 SQL 解析器,它的大致解析流程是 Lexer -> Parser -> AST -> Vistor,使用者需要实现它的 Vistor 接口,将自己的业务逻辑在 Vistor 中实现,因此需要通过 Vistor 再生成 SharidingContext,而抽象语法树 AST,也需要对 SQL 完全理解。
Sharding-JDBC 自研的 SQL 解析器,对于 Sharding 不相关的关键词采用跳过的方法,整体解析流程简化为 Lexer -> Parser -> SharidingContext,在性能以及实现复杂度上都有所突破。
- 容量规划:现有的数据量有多大,每天或者每月增长量是多少。现在需要分多少个库表,分完能够支撑多长时间。
- 分库分表策略确定:数据如何分布均匀,分多少库 分多少表。按范围分还是年月分还是HASH取模啥的。
- 扩容等问题。一旦现有容量到达极限,如果进行扩容?扩容过程中数据迁移量有多少?
- 如果进行历史数据迁移。
-
事务问题:
ShardingJDBC提供本地事务、两阶段事务、柔性事务
https://shardingsphere.apache.org/document/current/cn/features/transaction/
-
跨节点join的问题:
-
换条技术栈:使用ES后者其他NOSQL数据库。
-
分两次查询实现。在第一次查询的结果集中找出关联数据的id,然后根据这些id发起第二次请求得到关联数据。
-
-
跨表或跨库的count、order by、group by以及聚合函数问题。 这些是一类问题,因为它们都需要基于全部数据集合进行计算。
解决方案:与解决跨节点join问题的类似,分别在各个节点上得到结果后在应用程序端进行合并。和join不同的是每个结点的查询可以并行执行,因此很多时候它的速度要比单一大表快很多。但如果结果集很大,对应用程序内存的消耗是一个问题。
-
非分表字段查询问题:再加一张中间表或者换条技术栈。
-
跨分片的排序分页 一般来讲,分页时需要按照指定字段进行排序。当排序字段就是分片字段的时候,我们通过分片规则可以比较容易定位到指定的分片,而当排序字段非分片字段的时候,情况就会变得比较复杂了。为了最终结果的准确性,我们需要在不同的分片节点中将数据进行排序并返回,并将不同分片返回的结果集进行汇总和再次排序,最终再返回给用户。
Sharding JDBC实现的归并引擎:https://shardingsphere.apache.org/document/current/cn/features/sharding/principle/merge
-
全局ID
-
UUID:是一种最简单的实现,但是缺点明显,由于uuid非常长,占用空间大,并且索引的创建和基于索引的查询都会有一定的性能问题。
-
使用数据库的表,专门生成id:创建一张表,专门用来获取id ,但是这种方案性能瓶颈明显,所有的插入操作都下需要访问这张表,很容易就成为系统性能瓶颈,并且存在单点问题,即使使用主从模式,也只能解决单点问题。
-
雪花算法:由毫秒级时间41位 机器ID 10位 毫秒内序列12位组成,实现简单。整体按照时间自增排序,不会产生id碰撞,效率极高。但是存在时钟回拨的id碰撞风险
-
Redis自增:这个就是依赖redis的单线程特性,使用自增integer来保证全局唯一,性能也很好。
Sharding JDBC 内置UUID和雪花算法 两种主键生成器
https://shardingsphere.apache.org/document/current/cn/features/sharding/concept/key-generator/
-
面试题
现在有一个未分库分表的系统,未来要分库分表,如何设计才可以让系统从未分库分表动态切换到分库分表上?
面试官心里分析
你看看,你现在已经明白为啥要分库分表了,你也知道常用的分库分表中间件了,你也设计好你们如何分库分表的方案了(水平拆分、垂直拆分、分表),那问题来了,你接下来该怎么把你那个单库单表的系统给迁移到分库分表上去?
所以这都是一环扣一环的,就是看你有没有全流程经历过这个过程。
友情提示:
假设,你现有有一个单库单表的系统,在线上在跑,假设单表有600万数据
3个库,每个库里分了4个表,每个表要放50万的数据量
假设你已经选择了一个分库分表的数据库中间件,sharding-jdbc,mycat,都可以
你怎么把线上系统平滑地迁移到分库分表上面去
sharding-jdbc:自己上官网,找一个官网最基本的例子,自己写一下,试一下,跑跑看,是非常简单的
mycat:自己上官网,找一个官网最基本的例子,自己写一下,试一下看看
1个小时以内就可以搞定了
面试题剖析
这个其实从low到高大上有好几种方案,我们都玩儿过,我都给你说一下
1. 停机迁移方案
我先给你说一个最low的方案,就是很简单,大家伙儿凌晨12点开始运维,网站或者app挂个公告,说0点到早上6点进行运维,无法访问。。。。。。
接着到0点,停机,系统挺掉,没有流量写入了,此时老的单库单表数据库静止了。然后你之前得写好一个导数的一次性工具,此时直接跑起来,然后将单库单表的数据哗哗哗读出来,写到分库分表里面去。
导数完了之后,就ok了,修改系统的数据库连接配置啥的,包括可能代码和SQL也许有修改,那你就用最新的代码,然后直接启动连到新的分库分表上去。
验证一下,ok了,完美,大家伸个懒腰,看看看凌晨4点钟的北京夜景,打个滴滴回家吧!
但是这个方案比较low,谁都能干,我们来看看高大上一点的方案。
2.双写迁移方案
这个是我们常用的一种迁移方案,比较靠谱一些,不用停机,不用看北京凌晨4点的风景
简单来说,就是在线上系统里面,之前所有写库的地方,增删改操作,除了对老库增删改,加上对新库的增删改,这就是所谓双写,同时写俩库,老库和新库。
然后系统部署之后,新库数据差太远,用之前说的导数工具,跑起来读老库数据写新库,写的时候要根据gmt_modified这类字段判断这条数据最后修改的时间,除非是读出来的数据在新库里没有,或者是比新库的数据新才会写。
接着导一万轮之后,有可能数据还是存在不一致,那么就程序自动做一轮校验,比对新老库每个表的每条数据,接着如果有不一样的,就针对那些不一样的,从老库读数据再次写。反复循环,直到两个库每个表的数据都完全一致为止。
接着当数据完全一致了,就ok了,基于仅仅使用分库分表的最新代码,重新部署一次,不就仅仅基于分库分表在操作了么,还没有几个小时的停机时间,很稳。所以现在基本玩儿数据迁移之类的,都是这么干了。
面试题
如何设计可以动态扩容缩容的分库分表方案?
面试官心里分析
(1)选择一个数据库中间件,调研、学习、测试; (2)设计你的分库分表的一个方案,你要分成多少个库,每个库分成多少个表,3个库每个库4个表; (3)基于选择好的数据库中间件,以及在测试环境建立好的分库分表的环境,然后测试一下能否正常进行分库分表的读写; (4)完成单库单表到分库分表的迁移,双写方案; (5)线上系统开始基于分库分表对外提供服务; (6)扩容了,扩容成6个库,每个库需要12个表,你怎么来增加更多库和表呢?
这个是你必须面对的一个事儿,就是你已经弄好分库分表方案了,然后一堆库和表都建好了,基于分库分表中间件的代码开发啥的都好了,测试都ok了,数据能均匀分布到各个库和各个表里去,而且接着你还通过双写的方案咔嚓一下上了系统,已经直接基于分库分表方案在搞了。
那么现在问题来了,你现在这些库和表又支撑不住了,要继续扩容咋办?这个可能就是说你的每个库的容量又快满了,或者是你的表数据量又太大了,也可能是你每个库的写并发太高了,你得继续扩容。
这都是玩儿分库分表线上必须经历的事儿
面试题剖析
1.停机扩容
这个方案就跟停机迁移一样,步骤几乎一致,唯一的一点就是那个导数的工具,是把现有库表的数据抽出来慢慢倒入到新的库和表里去。但是最好别这么玩儿,有点不太靠谱,因为既然分库分表就说明数据量实在是太大了,可能多达几亿条,甚至几十亿,你这么玩儿,可能会出问题。
从单库单表迁移到分库分表的时候,数据量并不是很大,单表最大也就两三千万。
写个工具,多弄几台机器并行跑,1小时数据就导完了。
3个库+12个表,跑了一段时间了,数据量都1亿~2亿了。光是导2亿数据,都要导个几个小时,6点,刚刚导完数据,还要搞后续的修改配置,重启系统,测试验证,10点才可以搞完。
2.优化后的方案
一开始上来就是32个库,每个库32个表,1024张表
我可以告诉各位同学说,这个分法,第一,基本上国内的互联网肯定都是够用了,第二,无论是并发支撑还是数据量支撑都没问题。
每个库正常承载的写入并发量是1000,那么32个库就可以承载32 * 1000 = 32000的写并发,如果每个库承载1500的写并发,32 * 1500 = 48000的写并发,接近5万/s的写入并发,前面再加一个MQ,削峰,每秒写入MQ 8万条数据,每秒消费5万条数据。
有些除非是国内排名非常靠前的这些公司,他们的最核心的系统的数据库,可能会出现几百台数据库的这么一个规模,128个库,256个库,512个库。
1024张表,假设每个表放500万数据,在MySQL里可以放50亿条数据。
每秒的5万写并发,总共50亿条数据,对于国内大部分的互联网公司来说,其实一般来说都够了。
谈分库分表的扩容,第一次分库分表,就一次性给他分个够,32个库,1024张表,可能对大部分的中小型互联网公司来说,已经可以支撑好几年了。
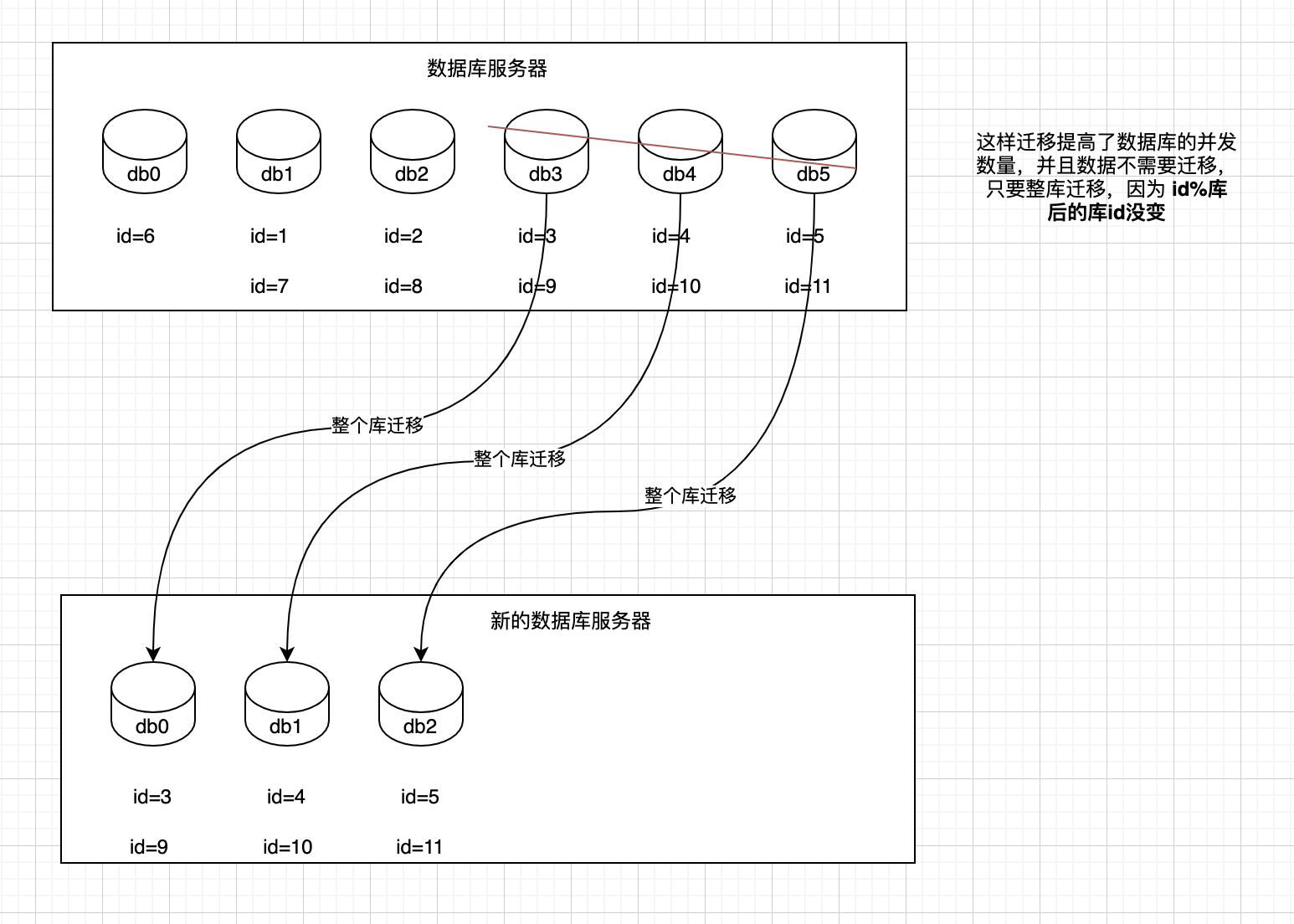
一个实践是利用32 * 32来分库分表,即分为32个库,每个库里一个表分为32张表。一共就是1024张表。根据某个id先根据32取模路由到库,再根据32取模路由到库里的表。
刚开始的时候,这个库可能就是逻辑库,建在一个数据库上的,就是一个mysql服务器可能建了n个库,比如16个库。后面如果要拆分,就是不断在库和mysql服务器之间做迁移就可以了。然后系统配合改一下配置即可。
比如说最多可以扩展到32个数据库服务器,每个数据库服务器是一个库。如果还是不够?最多可以扩展到1024个数据库服务器,每个数据库服务器上面一个库一个表。因为最多是1024个表么。
这么搞,是不用自己写代码做数据迁移的,都交给dba来搞好了,但是dba确实是需要做一些库表迁移的工作,但是总比你自己写代码,抽数据导数据来的效率高得多了。
哪怕是要减少库的数量,也很简单,其实说白了就是按倍数缩容就可以了,然后修改一下路由规则。
对2 ^ n取模
orderId 模 32 = 库 orderId / 32 模 32 = 表
orderId 库 表
259 3 8 1189 5 5 352 0 11 4593 17 15
1、设定好几台数据库服务器,每台服务器上几个库,每个库多少个表,推荐是32库 * 32表,对于大部分公司来说,可能几年都够了;
2、路由的规则,orderId 模 32 = 库,orderId / 32 模 32 = 表;
3、扩容的时候,申请增加更多的数据库服务器,装好mysql,倍数扩容,4台服务器,扩到8台服务器,16台服务器;
4、由dba负责将原先数据库服务器的库,迁移到新的数据库服务器上去,很多工具,库迁移,比较便捷;
5、我们这边就是修改一下配置,调整迁移的库所在数据库服务器的地址;
6、重新发布系统,上线,原先的路由规则变都不用变,直接可以基于2倍的数据库服务器的资源,继续进行线上系统的提供服务。