Hi,
Since @breznak mentioned about TM performance in #680 - I was benchmarking HTM.core's TM implementation vs mine and got really weird results.
Methodology
I adopted the tmbench.cpp code from here. The idea is to:
- Set both TM's parameter to run in the same condition
- Generate an array of 1000 random SDR with 10% density (using a scalar encoder)
- Send the SDRs to the TM one-by-one, until we passed all the SDRs
- Measure how long 3 takes
- Repeat for different SDR sizes
Source code (modified so I can generate plot from them):
For HTM.core
For Etaler
Result
The result is weird. I think I'm doing something horribly wrong. But I have no idea without deep knowledge about HTM.core's internal.
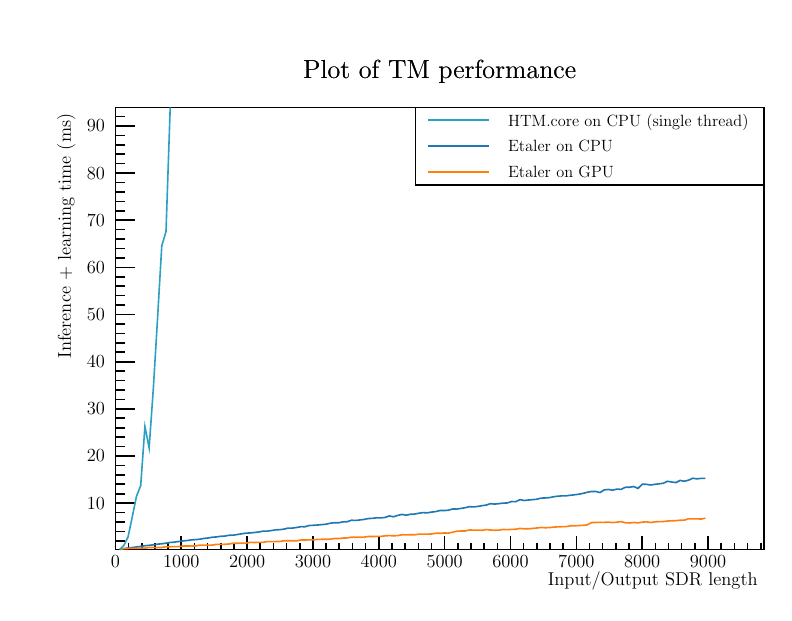
Edit: I believe the problem might be related to some old forum posts
TemporalMemory running very slow after long training
Hi,
Since @breznak mentioned about TM performance in #680 - I was benchmarking HTM.core's TM implementation vs mine and got really weird results.
Methodology
I adopted the
tmbench.cppcode from here. The idea is to:Source code (modified so I can generate plot from them):
For HTM.core
For Etaler
Result
The result is weird. I think I'm doing something horribly wrong. But I have no idea without deep knowledge about HTM.core's internal.

Edit: I believe the problem might be related to some old forum posts
TemporalMemory running very slow after long training