TensorFlow에서 발생한 로그를 표시하거나 디버깅(debugging)을 하기 위한 도구로 그래프를 통해 학습과정을 시각화하는 것이 주요 기능
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
nb_classes = 10 # 0 ~ 9
# MNIST data image shape 28 x 28 = 784
X = tf.placeholder(tf.float32, [None, 784])
Y = tf.placeholder(tf.float32, [None, nb_classes])
W = tf.Variable(tf.random.normal([784, nb_classes]))
b = tf.Variable(tf.random.normal([nb_classes]))
hypothesis = tf.nn.softmax(tf.matmul(X, W) + b)
cost = tf.reduce_mean(-tf.reduce_sum(Y * tf.log(hypothesis), axis=1))
cost_scalar = tf.summary.scalar("cost", cost)
# tf.summary.histogram() - 히스토그램도 가능
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
# optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost)
is_correct = tf.equal(tf.arg_max(hypothesis, 1), tf.arg_max(Y, 1))
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
training_epochs = 1 # 한번 학습했을때를 확인
batch_size = 100
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(training_epochs):
summary = tf.summary.merge_all()
avg_cost = 0
total_batch = int(mnist.train.num_examples / batch_size)
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
s, c, _ = sess.run([summary, cost, optimizer], feed_dict={X: batch_xs, Y: batch_ys})
writer = tf.summary.FileWriter("./logs/xor2")
writer.add_graph(sess.graph)
writer.add_summary(s, global_step=i)
avg_cost += c / total_batch
print('Epoch:', '%04d' % (epoch + 1), 'cost=', '{:.9f}'.format(avg_cost))
print("Accuarcy: ", accuracy.eval(feed_dict={X: mnist.test.images, Y: mnist.test.labels}))tf.summary.scalar() - 어떠한 값을 logging 할 것 인가
(scalar - 단일 값을 가지는 텐서형만 사용가능 EX) accuarcy, loss)
(histogram - 값에 대한 분포도를 보고자 할 경우에 사용하며 다차원 텐서형 사용가능 EX) weight, bias)
tf.summary.merge_all() - summary들을 하나로 합침(일부만 합칠 경우는 tf.summary.merge()사용)
writer = tf.summary.FileWriter() - 어느 위치에 log를 저장할 것 인가
writer.add_graph(sess.graph) - 세션 그래프를 넘김
s, c, _ = sess.run([summary, cost, optimizer], feed_dict={X: batch_xs, Y: batch_ys}) - s에 summary값을 넣어줌
writer.add_summary(s, global_step=i) - s값과 step을 기록
tensorboard --logdir="경로명" - tensorboard 실행
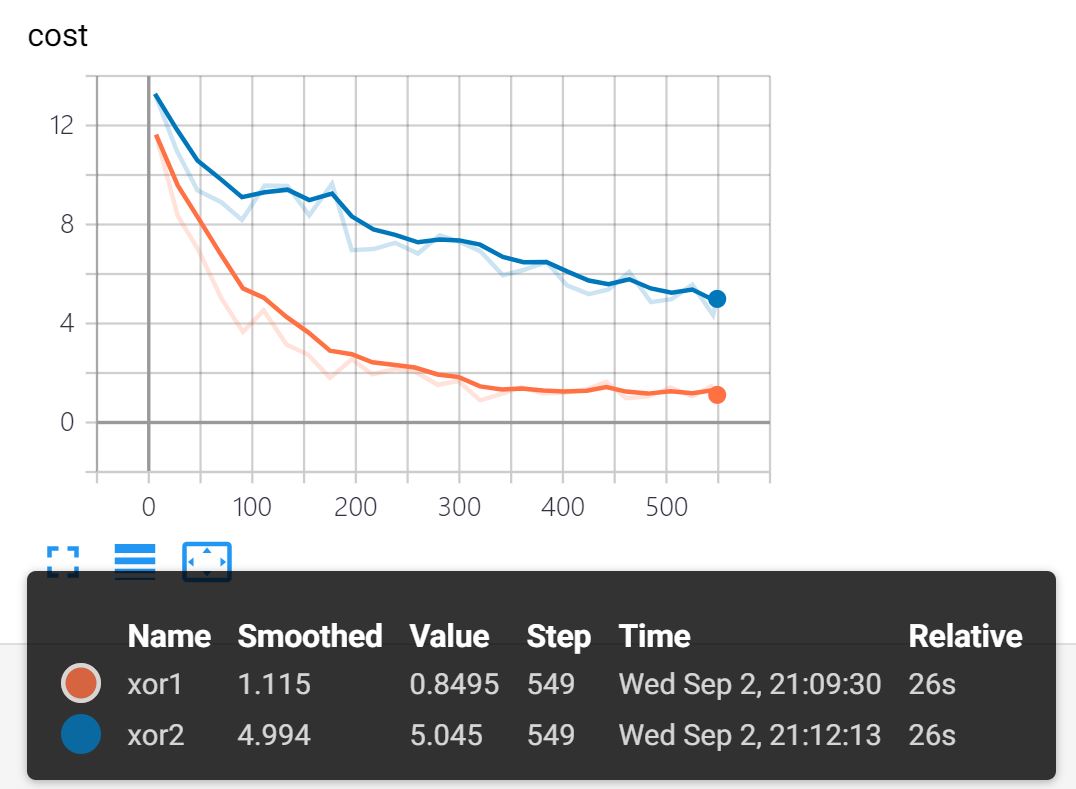
xor1 - learning rate = 0.1
xor2 - learning rate = 0.01
위의 결과로 learning rate가 0.1일 때 학습이 잘 이루어지는 반면 0.01일 때는 학습이 잘 이루어지지 않는 것을 확인할 수 있음