- Long Short-Term Memory
- 은닉층의 메모리 셀에 입력 게이트, 삭제 게이트, 출력 게이트를 추가하여 불필요한 기억들을 지우고, 기억해야 할 것 들을 지정
- 각 게이트에는 공통적으로 시그모이드 함수가 존재
- RNN에서 셀 상태(cell state)라는 값이 추가
- RNN과 비교해서 긴 시퀀스들을 처리하는 데 탁월한 성능을 보임
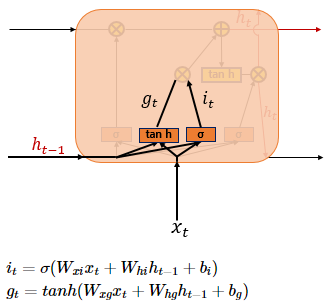
σ : sigmoid 함수
i : 현재 시점 t의 x값과 입력게이트로 이어지는 가중치 Wxi를 곱한 값과 이전 시점 t - 1의 은닉 상태가 입력 게이트로 이어지는 가중치 Whi를 곱한 값을 더해서 시그모이드 함수를 지남
g : 현재 시점 t의 x값과 입력게이트로 이어지는 가중치 Wxg를 곱한 값과 이전 시점 t - 1의 은닉 상태가 입력 게이트로 이어지는 가중치 Whg를 곱한 값을 더해서 tanh 함수를 지남
출력되는 0 ~ 1, -1 ~ 1 두 가지의 값으로 선택된 기억할 정보의 양을 정함
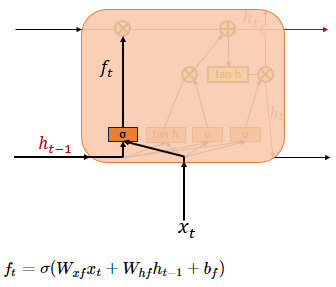
현재 시점 t의 x값과 이전 시점 t-1의 은닉 상태가 시그모이드 함수를 거쳐 0 ~ 1 값이 나오게 되고, 이 값이 곧 삭제 과정을 거친 정보의 양 (0에 가까울수록 정보가 많이 삭제된 것이고 1에 가까울수록 정보를 온전히 기억한 것)
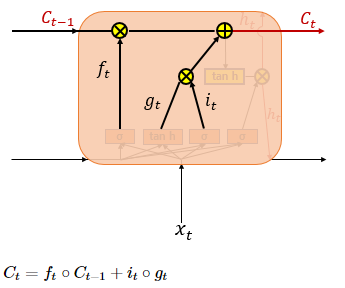
ft : 삭제 게이트에서 일부 기억을 잃은 상태
입력 게이트에서 구한 it, gt 두 값에 대해 원소별 곱을 진행 (∘ 연산)
입력 게이트에서 선택된 기억(새로운 정보)을 삭제 게이트의 결과와 더함 (Ct - 현재 시점 t의 셀 상태, 다음 t + 1 시점의 LSTM 셀로 넘겨줌)
삭제 게이트의 출력값이 ft가 0이 되면 이전 시점의 셀 상태값인 C(t-1)은 현재 시점의 셀 상태값을 결정하기 위한 영향력이 0이 되면서 오직 입력 게이트의 결과만으로 현재 시점의 셀 상태값 Ct를 결정하며 삭제 게이트가 완전히 닫히고 입력 게이트를 연 상태를 의미함
반대의 경우에는 현재 시점의 셀 상태값 Ct는 오직 이전 시점의 셀 상태값 C(t - 1)에만 의존
결과적으로 삭제 게이트는 이전 시점의 입력을 얼마나 반영할지, 입력 게이트는 현재 시점의 입력을 얼마나 반영할지 결정
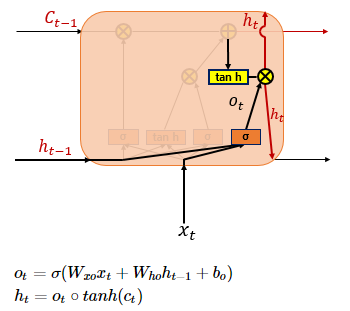
ot - 출력 게이트는 현재 시점 t의 x값과 이전 시점 t - 1의 은닉 상태가 시그모이드 함수값을 지난 값 (현재 시점 t의 은닉 상태를 결정하는데 사용)
ht - 셀 상태의 값이 tanh를 거쳐 -1 ~ 1값으로 나오고 해당 값은 출력 게이트의 값과 연관되면서, 값이 걸러지는 효과가 발생 (출력층으로 보내고자 하는 부분만 선별) 해서 은닉 상태가 됨 (이 값은 또한 출력층으로도 향함)
내용 참고 및 이미지 출처
https://dgkim5360.tistory.com/entry/understanding-long-short-term-memory-lstm-kr
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
path = "market-price.csv"
data = pd.read_csv(path, names=['ds', 'y'])
data['ds'] = data['ds'].apply(lambda x: pd.Timestamp(x[:10]))
train_data = data.loc[data['ds'] < "2018-06-15", ['ds', 'y']]
test_data = data.loc[data['ds'] >= "2018-06-15", ['ds', 'y']]
lookback = 5
X_train = []
y_train = []
for i in range(train_data.shape[0] - lookback):
X_train.append(train_data.y.iloc[i: i + lookback])
y_train.append(train_data.y.iloc[i + lookback])
X_test = []
y_test = []
for i in range(test_data.shape[0] - lookback):
X_test.append(test_data.y.iloc[i: i + lookback])
y_test.append(test_data.y.iloc[i + lookback])
X_train = np.array(X_train)
y_train = np.array(y_train)
X_train = X_train.reshape((X_train.shape[0], lookback, 1))
X_test = np.array(X_test)
y_test = np.array(y_test)
X_test = X_test.reshape((X_test.shape[0], lookback, 1))
optimizer = Adam(lr=0.005)
model = Sequential()
model.add(LSTM(32, activation="relu", input_shape=(lookback, 1), return_sequences=True))
model.add(LSTM(64, activation="relu", return_sequences=True))
model.add(LSTM(128, activation="relu"))
model.add(Dense(1024, activation="relu"))
model.add(Dense(1))
model.compile(loss="mse", optimizer=optimizer)
model.summary()
early_stop = EarlyStopping(monitor='loss', patience=10, verbose=1)
model.fit(X_train, y_train, epochs=100, batch_size=20, verbose=1, callbacks=[early_stop])
pred = model.predict(X_test)
plt.figure(figsize=(20, 10))
plt.plot(train_data['ds'], train_data['y'], label="Past price")
plt.plot(test_data['ds'], test_data['y'], label="Actual price")
plt.plot(test_data.iloc[lookback:, [0]], pred, label="Predict price")
plt.show()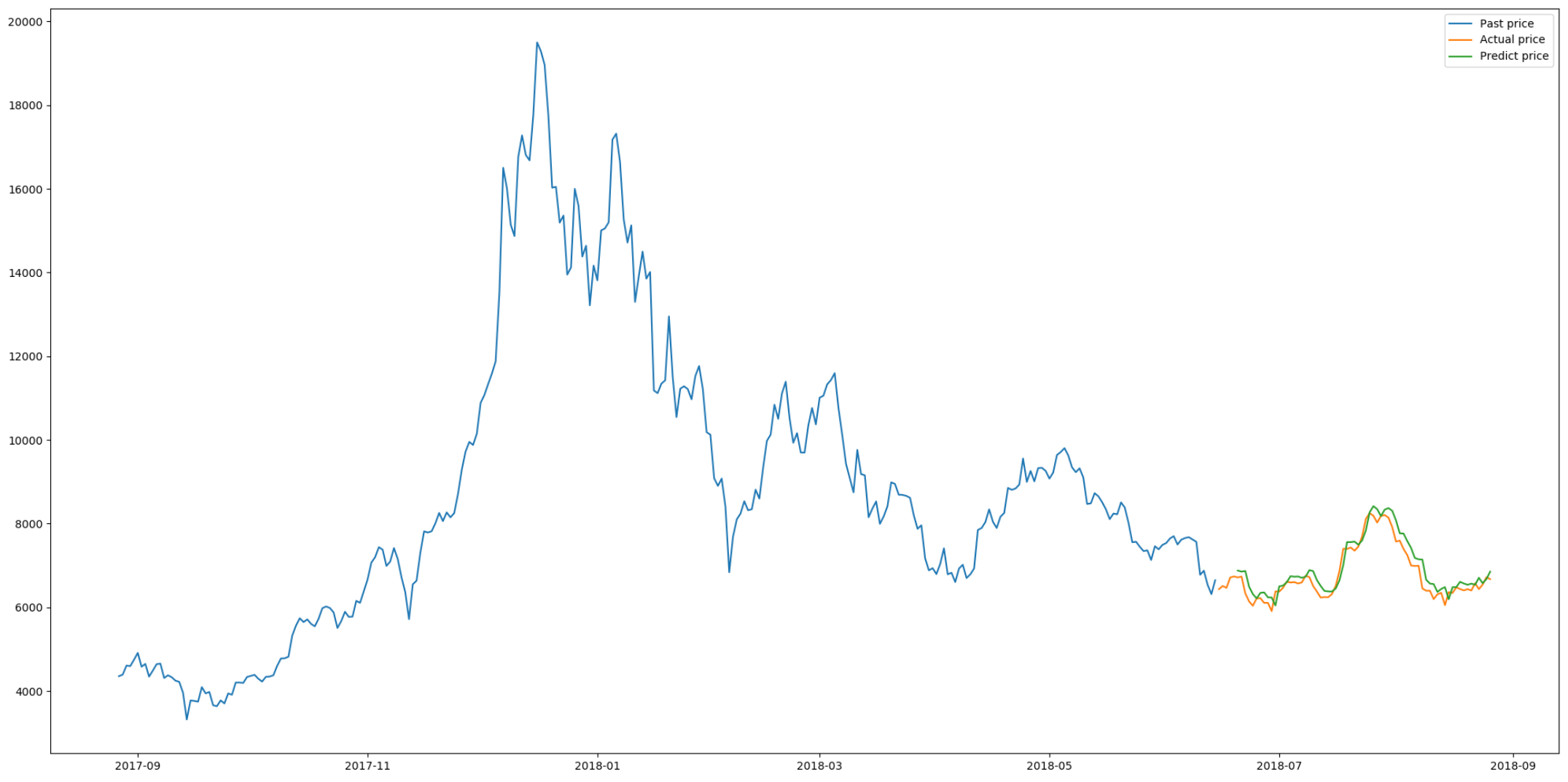
데이터의 갯수가 2 ~ 300개 정도로 많지 않았음에도 예측한 데이터와 실제 데이터가 거의 비슷한 형태로 나타남