diff --git a/.DS_Store b/.DS_Store
new file mode 100644
index 0000000..00af6e8
Binary files /dev/null and b/.DS_Store differ
diff --git a/Leetcode Workshops/.DS_Store b/Leetcode Workshops/.DS_Store
new file mode 100644
index 0000000..5d46a08
Binary files /dev/null and b/Leetcode Workshops/.DS_Store differ
diff --git a/Leetcode Workshops/Week 1/.DS_Store b/Leetcode Workshops/Week 1/.DS_Store
new file mode 100644
index 0000000..e620889
Binary files /dev/null and b/Leetcode Workshops/Week 1/.DS_Store differ
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/.DS_Store b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/.DS_Store
new file mode 100644
index 0000000..0df5240
Binary files /dev/null and b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/.DS_Store differ
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/1.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/1.md
new file mode 100644
index 0000000..281fbd8
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/1.md
@@ -0,0 +1,54 @@
+
+
+**Type:** _Text + image_
+
+**Title:** Time complexity
+
+**Note: **Code and graph on the right of the screen and text on the left
+
+**Content:**
+
+**Time complexity** allows us to describe **how the time taken to run a function grows as the size of the input of the function grows.**
+
+In our function, `valueSum()`. The amount of time this function takes to run (execution time) will grow as the number of elements (n) in the array increase. If the elements in the array `value` went up to 1,000,000, the amount of the time it would take for the function to compute would be much higher than if the array only went up to 10.
+
+```
+value = [1, 2, 3, 4, 5]
+
+def valueSum(value):
+ sum = 0 #c1 runtime
+ for i in value:
+ sum = sum + i #c2 runtime
+ return sum #c3 runtime
+```
+
+Adding all the individual runtimes, we'll get `f(n) = c2*n + c1 + c3`. Look familiar? It's in the form of a linear equation `f(n) = a*n + b` where a and b are constants. We can predict that `valueSum()` grows in linear time.
+
+Here it is linear -->
+
+[//]: # "insert 'timecomplexity' image"
+
+ +
+
+
+---
+
+_Explanation of code 1_
+
+`sum = 0` runs in constant time as it is simply assigning a value to the variable `sum` and only occurs once. For this line, the runtime is **c1**.
+
+The for loop statement expresses a variable `i` iterating over each element in `value`. This creates a loop that will iterate *n* times since `value` contains *n* elements.
+
+`sum = sum + i` occurs in constant time as well. Let's say this line runs in *c2* time. Since the loop body repeats however many times the loop is iterated, we can multiply *c2* by *n*. Now we have **c2 \* n** for the runtime of the entire for loop.
+
+Lastly, `return sum` is simply returning a number and only happens once. So, this line also runs in constant time which we'll note as **c3**.
+
+Time complexity answers the question: "At what rate does the time increase for a function as the input increases". **However**, it does not answer the question, "How long does it take for a function to compute?", because the answer relies on hardware, language, etc.
+
+For time complexity, functions can grow in **constant time**, **linear time**, **quadratic time**, and so on.
+
+
+
+
+
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/10.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/10.md
new file mode 100644
index 0000000..3564b61
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/10.md
@@ -0,0 +1,29 @@
+Type: text +img
+
+**Title:** Big Omega and Big theta
+
+### Big Omega
+
+Similar to **Big (O)**, we also have **Big Omega**. **Big Omega** is just the opposite; it is the lower bound of our function.
+
+Let's look at our chocolate example again. The same conditions hold true. We can establish the lower bound of how much chocolate you have to be 3/4. Why is this a valid lower bound? Because you will eventually exceed having 3/4 of the chocolate. **Remember when looking for bounds, we want one that holds true after a certain point and not necessarily from the beginning.**
+
+In terms of Python, let's say we have a `functionC` that runs on **O(n)** time. If we have `functionC` which grows on **O(n)** time, that would function as the **Big Omega** for our function, `functionA`.
+
+[//]: # "insert 'functionC vs functionA' image"
+
+`functionA`'s runtime grows faster than `functionC` after a certain point. After that certain point, we know with absolute certainty that the runtime of `functionA` will never be faster than `functionC`.
+
+### Big Theta
+
+Lastly, we have **Big Theta**. Big Theta is simply **Big O**'s formal name. **Big Theta** is the average runtime of a function. Going back to when we were determining the **Big O** notation for a function, we would write each line in the function in **Big O notation**.
+
+For example,
+
+$$
+Time(Input) = O(1) + O(n) + O(1).
+$$
+
+
+We then dropped every term except the fastest growing term (**O(n)**), and made that term define the function. By dropping all the terms, we are estimating the runtime of the function and finding our **Big Theta**.
+
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/2.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/2.md
new file mode 100644
index 0000000..f11f904
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/2.md
@@ -0,0 +1,28 @@
+**Type:** _Text + img_
+
+**Title:** _In what time does a function grow?_
+
+Content:
+
+```python
+value = range(6)
+
+def three(value):
+ sum = 0 #c1
+ return(sum) #c2
+```
+
+`sum = 0` only repeats once, so we know this line will take a constant amount of time **c1**. `return(sum)` also only repeats once, so we can infer that this line carries out in constant time **c2**.
+
+Hence, we predict that `three()` grows in **constant time**.
+
+[
+
+
+
+---
+
+**_code 1 explained_**
+
+Our prediction is true. Since both lines take constant time, adding them up is also still constant time, and our graph looks like a straight line.
+
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/3.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/3.md
new file mode 100644
index 0000000..8ec503e
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/3.md
@@ -0,0 +1,38 @@
+**Type:** _Text+img_
+
+**Title:** _in what time does the function grow ?_
+
+```python
+keypad = [[1, 2, 3],
+ [4, 5, 6],
+ [7, 8, 9],
+ [0]]
+def listInList(keypad):
+ sum = 0
+ for row in keypad: #a*n^2 !Nested loop!
+ for i in row: #b*n
+ sum += i
+ return sum #c
+```
+
+Since our function has a line that repeats itself n^2 times, we predict that this function grows in **quadratic time**. Looking at the graph, we see our prediction is indeed correct. Quadratic runtime starts growing quite quickly in comparison to a linear runtime. Notice that the equation for a quadratic equation is **a\*n^2\*+b\*n\*+c** where a, b and c are constants.
+
+
+
+[](https://camo.githubusercontent.com/204ae4fc13b58550585a953739c400953d8d7c92/68747470733a2f2f70726f6a6563746269742e73332d75732d776573742d312e616d617a6f6e6177732e636f6d2f6461726c656e652f6c6162732f53637265656e2b53686f742b323032302d30322d32312b61742b352e33302e30372b504d2e706e67)
+
+
+
+---
+
+Again, we will be trying to predict what time this function grows in.
+
+If we divide the function into parts, we get the lines `sum = 0`, `sum += i`, and `return sum` . `sum = 0` repeats once, so the time for this line to process is constant.
+
+`sum += i` is in a *for loop* so it might be intuitive to think that this line only repeats *n* times. However, this for loop is nested within another for loop, so the total number of iterations would be *n^2*.
+
+Lastly `return sum` repeats once, so this line will be processed in constant time.
+
+If we graph this out, it will look like the graph below:
+
+Looking at the graph, we see our prediction is indeed correct. Quadratic runtime starts growing quite quickly in comparison to a linear runtime. Something else to note is that the equation for a quadratic equation is **a\*n^2\*+b\*n\*+c** where a, b and c are constants.
\ No newline at end of file
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/4.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/4.md
new file mode 100644
index 0000000..9a37c44
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/4.md
@@ -0,0 +1,29 @@
+**Type:** _code centered_
+
+**Title:** How can we tell the time complexity just from the function?
+
+**Content:**
+
+ To summarize briefly so far, the time of an algorithm or function's run time will be the sum of the time it takes for all the lines in the code of the algorithm to run. This runtime growth can be written as a function.
+
+We can use the fastest growing term to determine the behavior of the equation; in this case, it is the **c2 * n** term. If we simply look at `Time(Input) = c2*n`, we know easily that the function is linear and that the runtime of `valueSum()` is *linear*.
+
+```python
+value = [1, 2, 3, 4, 5]
+
+def valueSum(value):
+ sum = 0 #c1
+ for i in value: #n*c2
+ sum = sum + i
+ return sum #c3
+```
+
+
+
+---
+
+Remember that elementary functions such as `+, -, *, \, =` always take a constant amount of time to run. **Thus, when we see these functions, we assign them the value *c* time.**
+
+From before, we analyzed `valueSum()` line by line and got `f(n) = c2*n + c1 + c3` when we added everything. This equation is actually a function of time where *n* is the input size and *f(n)* is the runtime; we can treat *f(n)* as *Time(Input)*.
+
+
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/5.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/5.md
new file mode 100644
index 0000000..d5d4353
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/5.md
@@ -0,0 +1,34 @@
+**Type:** _code left/right_
+
+**Title:** Finding time complexity
+
+_insert slide content here_
+
+Example 2:
+
+Let's look at the function `three` again. We can treat *c1 + c2* as one constant and call it **c3**. Now we have `T(I) = c3`. This makes it very obvious that the runtime of `three()` is *constant*.
+
+```python
+value = range(6)
+def three(value):
+ sum = 0 #c1
+ return(sum) #c2
+```
+
+Example 3:
+
+Let's do the same for `listInList()`.Putting it into a function, we get `Time(Input) = n^2 + c1 + c2`. If we isolate the fastest growing term, we get `T(I) = n^2` which reveals the runtime to be *quadratic*.
+
+```python
+keypad = [[1, 2, 3],
+ [4, 5, 6],
+ [7, 8, 9],
+ [0]]
+def listInList(keypad):
+ sum = 0 #c1
+ for row in keypad:`
+ for i in row: #n^2
+ sum += i
+ return sum #c2
+```
+
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/6.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/6.md
new file mode 100644
index 0000000..d1bd2a8
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/6.md
@@ -0,0 +1,70 @@
+**Type:** _link+code_
+
+**Title:** _Space Complexity_
+
+_insert slide content here_
+
+Similar to time complexity, as functions' input grows very large, they will take up an increasing amount of memory; this is **space complexity**. In fact, these functions' memory usage also grows in a similar fashion to time complexity and we describe the growth in the same way. We describe it as *linear*, *quadratic*, etc. time.
+
+``` python
+value = [1, 2, 3, 4, 5]
+
+def valueSum(value):
+ sum = 0 #c1
+ for i in value: #c3*n
+ sum = sum + i
+ return sum #c2
+```
+
+To describe the amount of memory this function will require, we will write an expression similar to what was done for *time complexity*. We will call our expression: *Space(Input)* as space is a function of the input.
+
+Our Space(Input) equation should look like:
+
+$$
+Space(Input) = c1 + c2 + c3*n
+$$
+Our equation represented by the dominant (fastest growing) term would simply be **c3 * n**.
+
+**Lets look at another familiar function, `listInList`**
+
+```python
+keypad = [[1, 2, 3],
+ [4, 5, 6],
+ [7, 8, 9],
+ [0]]
+
+def listInList(keypad):
+ sum = 0
+ for row in keypad:
+ for i in row:
+ sum += i
+ return sum
+```
+
+We work with two numbers, `i` and `sum`. These require **c1** and **c2** amount of memory.
+
+Each element in `keypad` will require **c3** amount of memory. We can conclude that the array `keypad` requires **c1 * n^2** amount of memory.
+
+The Space(Input) equation for `keypad` looks something like this.
+
+$$
+Space(Input) = c1 + c2 + c3*n^2
+$$
+Our equation represented by the dominant term would be **c3 * n^2**
+
+**Note:**Prioritize optimizing function run time over optimize memory
+
+---
+
+Let's try and find the Space(Input) equation for this function. To start, let's break down the function line by line. We are working with integers `sum` and `i`, with space values **c1** and **c2** respectively. We have a complex data structure, `value = [1, 2, 3, 4, 5]`, so we know that the amount of memory is **c3 * n** where *n* is the length of the range, `valueSum`.
+
+Similar to time complexity, the amount of memory `keypad` will need is **c1 * n * n**. In other words, **c1 * n^2** Primitive values such as integers, floats, strings, etc. will always take up a constant amount of memory. Complex data structures such as `arrays` take up `k * c` amount of memory where *c* is an amount of memory and *k* is the number of elements in the array. Going back to our `valueSum` function...
+
+## Optimize Time or Optimize Memory?
+
+The greater the input of a function, the greater amount of time and memory that the function will require to operate. A common question is **"Is it better to have our function run faster, but require more space; or should we have our function require less space, but run slower?"**
+
+We can either have our function run faster, but require more memory or our function run slower, but require less memory.
+
+The general answer is to have our function run faster. It is always possible to buy more space/memory. It's impossible to buy extra time. Hence, the general rule is to **prioritize** having our function/algorithm run faster.
+
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/7.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/7.md
new file mode 100644
index 0000000..5e33c95
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/7.md
@@ -0,0 +1,52 @@
+**Type:** slide text
+
+**Title:** Big - O notation
+
+
+
+Now that we have an understanding of *time complexity* and *space complexity* and how to express them as functions of time, we can elaborate on the way we express these functions. **Big-O Notation** is a common way to express these functions.
+
+Instead of using terms like *Linear Time*, *Quadratic Time*, *Logarithmic Time*, etc., we can write these terms in **Big-O Notation**. Depending on what time the function increases by, we assign it a **Big-O** value. **Big-O** notation is incredibly important because it allows us to take a more mathematical and calculated approach to understanding the way functions and algorithms grow.
+
+**Big-O notation** is also useful because it simplifies how we describe a function's time complexity and space complexity. So far, we have defined a function of time as a number of terms. With Big-O notation, we are able to use only the dominant, or fastest growing, term!
+
+## How to Write in Big-O Notation
+
+To write in **Big-O Notation** we use a capital O followed with parentheses : **O()**.
+
+Depending on what is inside of the parentheses will tell us what time the function grows in. Let's look at an example.
+
+```python
+value = [1, 2, 3, 4, 5]
+
+def valueSum(value):
+ sum = 0
+ for i in value:
+ sum = sum + i
+ return sum
+```
+
+Going back to our `valueSum` function, we had previously expressed the runtime of this function as input increase. We had written the expression *Time(Input)* and the components its made of.
+
+**Time(Input) = c1 + c2*n + c3**
+
+`c1` comes from the line `sum = 0` . We know `sum = 0` will always take the same amount of time to run because we are assigning a value to a variable. We call this *constant time* because no matter what function this line is in, it will take the same amount of time to run.
+
+Since **c1** runs in constant time, we would write it as **O(1)** in **Big-O Notation**. Notice that the line repeats only once.
+
+`sum = sum + i` is responsible for **c2** in our equation. We multiply **c2** by *n* however because **c2** is repeated multiple times. The runtime of this function increase linearly depending on the amount of elements that are added to `sum`.
+
+In **Big-O Notation**, this line would be rewritten as **O(n)** and would inform us that this line runs in *linear time*. We use the dominant term which is **c2 * n**. Since **c2 * n** and **n** behave the same (linearly), we can drop the coefficient of *c2*.
+
+Lastly, `return sum` is written as **O(1)** because it operates under constant time.
+
+Rewriting our `valueSum` function but in **Big-O notation**, we would have:
+
+```
+Time(Input) = O(1) + O(n) + O(1).
+```
+
+We've written the lines of the function in **Big-O Notation**, but now we need to write the function itself in **Big-O Notation**. The way we do that is to choose the term that is growing the fastest in the function (the dominant term) as *n* gets very large. We then disregard any coefficients of that term. Then assign that term for the function.
+
+For `valueSum`, the fastest growing term is **c2 * n** . If we ignore **c2** , we are left with just `n`. We now know that the time complexity of `valueSum` is **O(n)** and the runtime of `valueSum` grows in a linear fashion.
+
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/8.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/8.md
new file mode 100644
index 0000000..2841e49
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/8.md
@@ -0,0 +1,72 @@
+**Type:** bold text + img
+
+**Title:** _Big-O continued _
+
+Let's look at another example.
+
+`listInList` expressed as a function of time looks like this:
+$$
+Time(Input) = c1 + c2 * n^2 + c3
+$$
+We know that **c1** corresponds to **O(1)** .
+**c2 * n^2** is written as **O(n^2)**.
+**c3** is written as **O(1)** since it operates under constant time.
+
+As for our last example, let's make a quick edit to our function `listInList` and call it `listInList2`.
+
+```python
+keypad = [[1, 2, 3],
+ [4, 5, 6],
+ [7, 8, 9],
+ [0]]
+def listInList2(keypad):
+ sum = 0
+ for row in keypad:
+ for i in row:
+ sum += i
+ for row in keypad:
+ for i in row:
+ sum += i
+ while sum <= 100:
+ sum += 1
+ return sum
+```
+
+
+
+$$
+T(I) = c1 + (c2 * n^2) + (c2 * n^2) + (c3 * n) + c4
+$$
+
+
+The fastest growing term is **n^2 * c2** but we have two of them. Since **n^2 * c2** corresponds to **O(n^2)**, we are left with:
+
+**Time(Input) = O(n^2) + O(n^2)**
+
+This can simply be rewritten as:
+
+**Time(Input) = 2 * O(n^2)**
+
+
+
+### Time expressed in Big-O Notation
+
+| Time | Big O Notation |
+| ---------------- | -------------- |
+| Constant Time | O(1) |
+| Linear Time | O(n) |
+| Quadratic Time | O(n^2) |
+| Logarithmic Time | O(log n) |
+| Factorial Time | O(n!) |
+
+In the table, there are some other times you should know of. The graph lists the growth of functions from slowest to fastest. A function in **O(1)**'s runtime grows the slowest, and a function in **O(n!)** grows the fastest. Needless to say, we want our functions to be **constant or linear time.**
+
+------
+
+The fastest growing term is **c2 * n^2** so we know that this term defines how our function is written in **Big-O Notation**. Dropping the coefficient, **c2**, our function is expressed as **O(n^2)**. in **Big-O Notation**. This tells us that `listInList` grows in quadratic time.
+
+Notice that we doubled the amount of *for loops* in our function. We have to account for that when writing `listInList2` as a function of time. Since we have extra lines in our code, we need to add a term to our **Time(Input)** expression. To account for a double for loop, we can simply add another **n^2 * c2** to our **Time(Input) expression**.
+
+It might be intuitive to think that our function written in **Big-O notation** would be **2 * O(n^2)** or even **O(2n^2)**, but we have to remember that **Big-O notation only tells us what time a function grows in**. **O(n^2)** and **O(2n^2)** both grow in the same fashion, quadratic, so we can simply write the function as **O(n^2)**.
+
+It is very important to remember that Big-O notation is determined by the fastest growing term as `n` gets very large. When n is small, c3 * n will grow faster than c2 * n^2. **Big-O notation is determined when n is very large** because time and space complexities focus on when inputs are very large; not small.
\ No newline at end of file
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/9.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/9.md
new file mode 100644
index 0000000..ee01774
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/9.md
@@ -0,0 +1,26 @@
+Type: Left img + text
+
+**Title:**Big O
+
+ The **Big O** we have been talking about this entire time is formally known as **Big Theta**. In the work and the industry, **Big Theta** is referred to as simply **Big O**. To avoid confusion, from now on, **Big Theta** will refer to the workplace Big-O and **Big (O)** will be the formal definition.
+
+#### What are they?
+
+**Big (O)** is the upper bound of a function. It describes a function whose curve on a graph, at least after a certain point on the x-axis (input size), will always be higher on the y-axis (time) than the curve of the runtime.
+
+To explain in simpler terms, let's say I have a chocolate bar. I give you half of the chocolate bar, then half of the chocolate I have leftover, then half of the new leftover, and so on. Theoretically, this could go on forever and eventually how much chocolate you have will converge to some amount. We can set an *upper bound* for how much chocolate you have to be 1; we have just applied the **Big (O)** concept. No matter how long this exchange goes on for, I will always be holding onto some tiny bit of the chocolate. The amount of chocolate that you have won't actually reach an entire bar, but you may be very close!
+
+We could have chosen our upper bound to be as high as we want. Let it be 1 million and we can say for 100% certainty that we won't be wrong. However, this isn't very useful because we are allowing such a wide range which is why it is best if we try to establish the smallest range possible.
+
+Let's apply this concept to Computer Science terms.
+
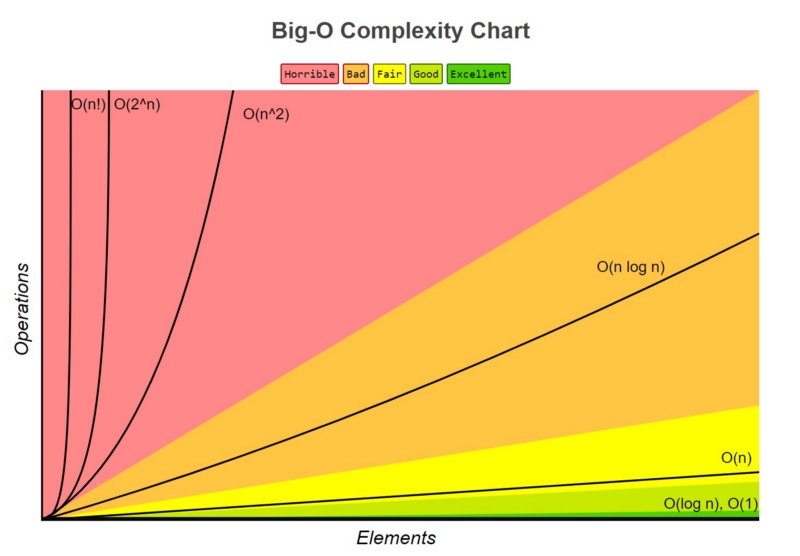
+Let's say that `functionA` runs in **O(n^2) time**. If we compare it to `functionB` , which runs in **O(n!)** time, we know that `functionA`'s runtime will never exceed `functionB`'s runtime.
+
+
+
+You can see the runtime of **O(n)** never exceeds the runtime of **O(n!)**
+
+##### Why is this useful?
+
+In the absolute worst case scenario, we know the ceiling of `functionA`'s runtime. We are then able to prepare for it and ensure that our computer or hardware will be able to handle running the function.
+
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/1.md b/Leetcode Workshops/Week 1/Act2_HashTables/1.md
new file mode 100644
index 0000000..9943b79
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/1.md
@@ -0,0 +1,15 @@
+**Type:** _text + image _
+
+**Title:** Hash Tables, Hash functions
+
+_insert slide content here_
+
+
+
+**Hash tables** are a type of data structure in which the address or the index value of the data element is generated from a hash function. A **hash function** is any function that can be used to map data of arbitrary size to fixed-size values. The values returned by a hash function are called **hash values**. The values are used to index a fixed-size table which is the Hash table. Use of a hash function to index a hash table is called **hashing**.
+
+
+
+That makes accessing the data faster than can be done with many other data structures. For example, accessing data in Linked Lists could potentially take much longer, as one would have to loop through the list until the desired data is aquired. If you wished to find the last element in the list, you would have to go through the *entire* list! In Hash Tables, on the other hand, the index value behaves as a key for the data value. In other words, a Hash table stores key-value pairs but the key is generated through a hashing function and this key can be used to access the element.
+
+Thus, the search and insertion functions of a data element (which rely on accessing data) become much faster as the key values themselves become the index of the array, which stores the data.
\ No newline at end of file
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/10.md b/Leetcode Workshops/Week 1/Act2_HashTables/10.md
new file mode 100644
index 0000000..b6d0bee
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/10.md
@@ -0,0 +1,15 @@
+**Type:** centered text
+
+**Title:** Hash Tables in Python
+
+As you now know, Hash tables are a type of data structure in which the address or the index value of the data element is generated from a hash function. That makes accessing the data faster as the index value behaves as a key for the data value. In other words Hash table stores key-value pairs but the key is generated through a hashing function.
+
+So the search and insertion function of a data element becomes much faster as the key values themselves become the index of the array which stores the data.
+
+However, when we talk about **hash tables**, we're actually talking about a **dictionary**. In Python, the Dictionary data types represent the implementation of hash tables. The Keys in the dictionary satisfy the following requirements.
+
+- The keys of the dictionary are hashable i.e. the are generated by hashing function which generates unique result for each unique value supplied to the hash function.
+- The order of data elements in a dictionary is not fixed.
+
+Dictionaries in python are implemented through Hashtables. Dictionaries won't be covered extensively in this activity, but this an interesting piece of information to take note of.
+
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/2.md b/Leetcode Workshops/Week 1/Act2_HashTables/2.md
new file mode 100644
index 0000000..a2fdcd1
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/2.md
@@ -0,0 +1,56 @@
+**Type:** img + text
+
+**Title:** Hash Tables: Hashing and Hash Functions
+
+_insert slide content here_
+
+
+
+**Hashing** is a technique that is used to uniquely identify a specific object from a group of similar objects. Some examples of how hashing is used in our lives include:
+
+- In universities, each student is assigned a unique roll number that can be used to retrieve information about them.
+- In libraries, each book is assigned a unique number that can be used to determine information about the book, such as its exact position in the library or the users it has been issued to etc.
+
+In both these examples the students and books were hashed to a unique number.
+
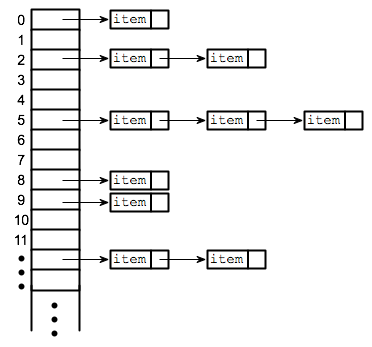
+In hashing, large keys are converted into small keys by using **hash functions**. The values are then stored in a data structure called a **hash table**. The idea of hashing is to distribute entries (key/value pairs) uniformly across an array. Each element is assigned a key (converted key). By using that key you can access the element in **O(1)** time. **O(1)** in this context means that data can be accessed in constant time, regardless of how large our Hash Table is! Using the key, the algorithm (hash function) computes an index that suggests where an entry can be found or inserted.
+
+The image below will show you an example about how hasing itself works.
+
+
+
+
+Hashing is implemented in two steps:
+
+1. An element is given an integer by using a hash function. This integer can be used as an index to store and access the original element, which falls into the hash table.
+
+2. The element is stored in the hash table where it can be quickly retrieved using hashed key.
+
+ hash = hashfunc(key)
+ index = hash % array_size
+
+After performing these two steps, the hash is independent of the array size and it is then reduced to an index (a number between 0 and array_size − 1) by using the modulo operator (%). Now you're probably wondering about how you can map data sets to each other no matter the size. That's where the hash function comes in.
+
+> Reminder, the modulo operator (%) has two arguments and returns the remainder after division between the two numbers.
+
+**Hash function**
+A hash function is any function that can be used to map a data set of an arbitrary size to a data set of a fixed size, which falls into the hash table. The values returned by a hash function are called hash values, hash codes, hash sums, or simply hashes.
+
+To achieve a good hashing mechanism, It is important to have a good hash function with the following basic requirements:
+
+1. Easy to compute: It should be easy to compute and must not become an algorithm in itself.
+
+2. Uniform distribution: It should provide a uniform distribution across the hash table and should not result in clustering.
+
+3. Less collisions: Collisions occur when pairs of elements are mapped to the same hash value. These should be avoided.
+
+ **Note**: Irrespective of how good a hash function is, collisions are bound to occur. Therefore, to maintain the performance of a hash table, it is important to manage collisions through various collision resolution techniques.
+
+ ------
+
+ Assume that you have an object and you want to assign a key to it to make searching easy. To store the key/value pair, you can use a simple array like a data structure where keys (integers) can be used directly as an index to store values. So you're wondering about what happens when your keys get very large to the point where you can't even use them as an index. This is where the actual hashing comes in.
+
+
+ To truly appreciate hashing, one must have a basic understanding of Big-O notation and time complexity of algorithms. Time complexity refers to how an algorithm performs as input size becomes infinitely large. Big-O notation is used to define an upper bound on this performance. Understanding Big-O notation allows one to know the general worst-case time performance of certain algorithms or operations on a data structure, which can be important for a programmer in deciding which data structure to use.
+
+ While time complexity is a massive topic in Computer Science, for our purposes, we will focus on **O(1)** time, which is Big-O notation for constant time. This means that the time that an algorithm takes to perform a certain procedure is **independent** of the size of the input.
\ No newline at end of file
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/3.md b/Leetcode Workshops/Week 1/Act2_HashTables/3.md
new file mode 100644
index 0000000..b96303e
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/3.md
@@ -0,0 +1,60 @@
+**Type:** comparison left/right
+
+**Title:** Need for a good hash function
+
+_insert slide content here_
+
+
+
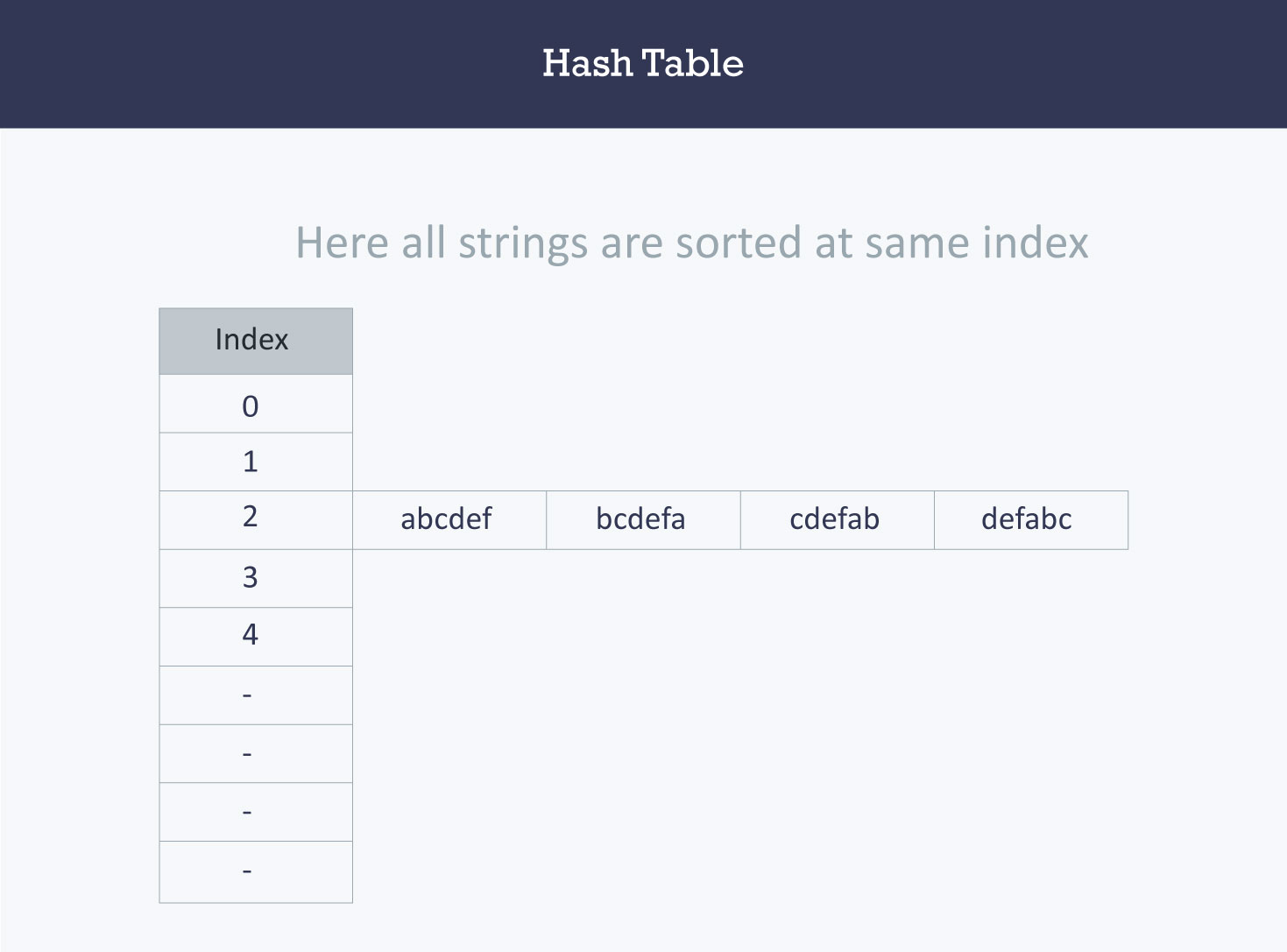
+Let us understand the need for a good hash function. Assume that you have to store strings in the hash table by using the hashing technique {“abcdef”, “bcdefa”, “cdefab” , “defabc” }.
+
+The hash function will compute the same index for all the strings and the strings will be stored in the hash table in the following format. As the index of all the strings is the same, you can create a list on that index and insert all the strings in that list.
+
+
+
+> Note: here, it will take **O(n)** time (where n is the number of strings) to access a specific string. This shows that the hash function is not a good hash function.
+
+* *
+
+| ASCII Value | Letter |
+| ----------- | ------ |
+| 97 | a |
+| 98 | b |
+| 99 | c |
+| 100 | d |
+| 101 | e |
+| 102 | f |
+
+> Chart for Ascii Values
+
+Here, it will take **O(n)** time (where n is the number of strings) to access a specific string. This shows that the hash function is not a good hash function.
+
+
+
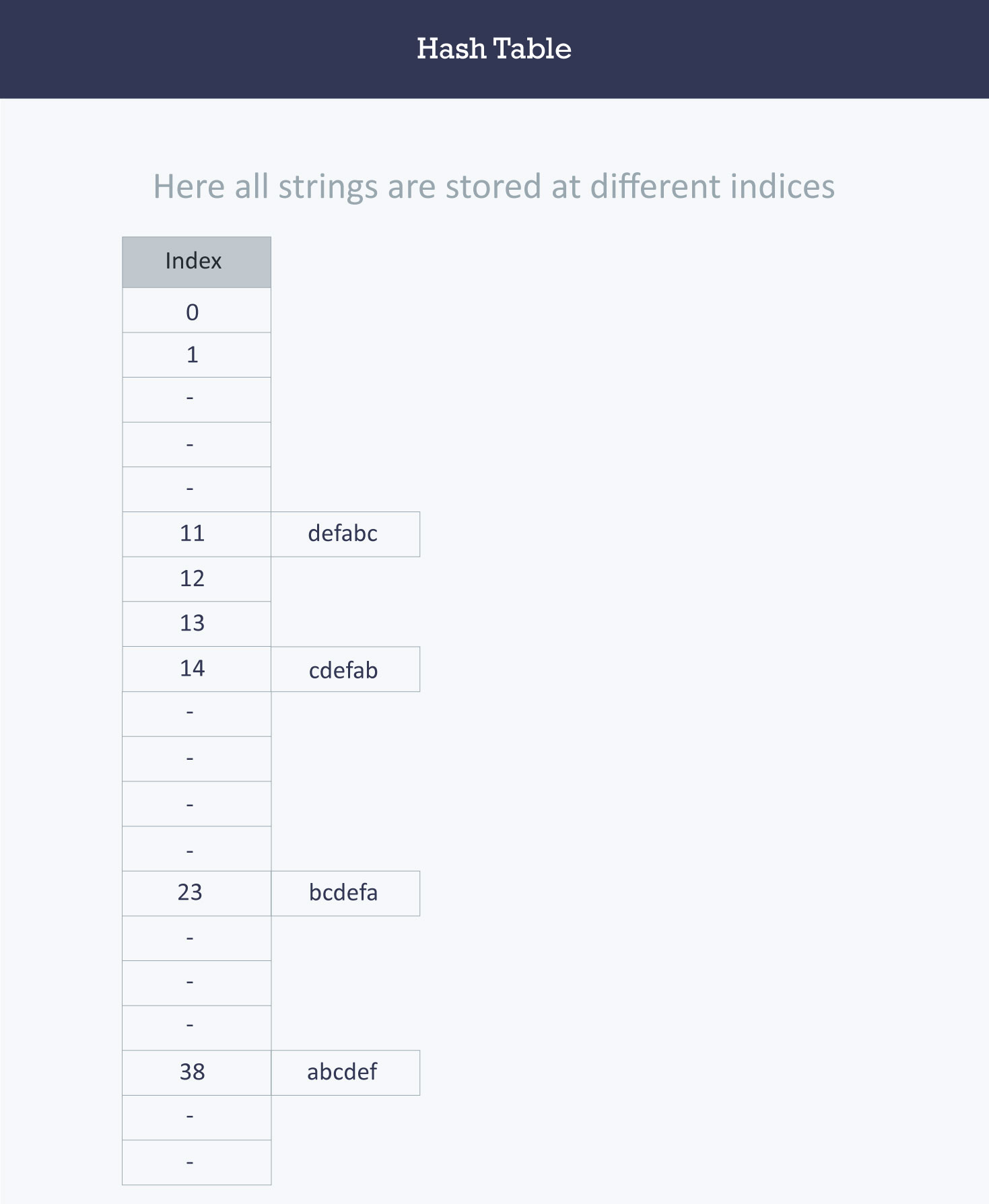
+Let’s try a different hash function. The index for a specific string will be equal to sum of ASCII values of characters multiplied by their respective order in the string after which it is modulo with 2069 (prime number).
+
+String Hash function Index
+abcdef (97*1 + 98*2 + 99*3 + 100*4 + 101*5 + 102*6)%2069 38
+bcdefa (98*1 + 99*2 + 100*3 + 101*4 + 102*5 + 97*6)%2069 23
+cdefab (99*1 + 100*2 + 101*3 + 102*4 + 97*5 + 98*6)%2069 14
+defabc (100*1 + 101*2 + 102*3 + 97*4 + 98*5 + 99*6)%2069 11
+
+
+
+>Calculating the value for 'abcdef'.
+>a = 97 * 1 // It is in the first position
+>b = 98*2 // it is in the second position
+>c = 99*3 // It is in the third position
+>d = 100*4 // It is in the fourth position
+>e = 101*5 // it is in the fifth position
+>f = 102*6 // It is in the sixth position
+
+**Note :**So overall, when you're implementing the hash table depending on the size of your list, you want to create the best hash table thatcan hash the values in your list in the most efficient time.
+
+------
+
+To compute the index for storing the strings, use a hash function that states the following:
+
+The index for a specific string will be equal to the sum of the ASCII values of the characters modulo 599.
+
+As 599 is a prime number, it will reduce the possibility of indexing different strings (collisions). It is recommended that you use prime numbers in case of modulo. The ASCII values of a, b, c, d, e, and f are 97, 98, 99, 100, 101, and 102 respectively. Since all the strings contain the same characters with different permutations, the sum will 599.
\ No newline at end of file
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/4.md b/Leetcode Workshops/Week 1/Act2_HashTables/4.md
new file mode 100644
index 0000000..bfddf67
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/4.md
@@ -0,0 +1,32 @@
+**Type:** bold text + img
+
+**Title:** Collision Resolution Techniques
+
+_insert slide content here_
+
+The pupose of a hash table is to assign each key to a unique slot, but sometimes it is possible that two keys will generate an identical hash causing both keys to point to the same slots. They are known as **hash collisions**.
+
+> A bucket is simply a fast-access location (like an array index) that is the the result of the hash function.
+
+
+
+The figure shows incidences of **collisions** in different table locations. We'll assign strings as our input data: `[John, Janet, Mary, Martha, Claire, Jacob, and Philip]`.
+
+Our hash table size is 6. As the strings are evaluated at input through the hash functions, they are assigned index keys `(0, 1, 2, 3, 4, or 5)`. We store the first string `John`, then `Janet` and `Mary`. All is fine, but when we try to store `Martha`, the hash function assigns `Martha` the same index key as `Janet`.
+
+Now, because a second value is attempting to map to an already occupied index key, a **collision** occurs as seen in figure we've been using. Three out of the six locations are occupied, and the probability that the remaining strings yet to be loaded will cause other **collisions** is very high.
+
+
+
+So we now return to the problem of collisions. When two items hash to the same slot, we must have a systematic method for placing the second item in the hash table. This process is called **collision resolution**.
+
+
+
+### How to handle Collisions?
+
+There are mainly two methods to handle collision:
+
+- 1) Separate Chaining
+- 2) Open Addressing
+
+We will elaborate further on these concepts in the following cards.
\ No newline at end of file
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/5.md b/Leetcode Workshops/Week 1/Act2_HashTables/5.md
new file mode 100644
index 0000000..ccc5be7
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/5.md
@@ -0,0 +1,17 @@
+**Type:** _text + img_
+
+**Title:** Seprate Chaining
+
+_insert slide content here_
+
+
+
+In this card, we will exploring a methodk nown as **separate chaining** which is an essential part of Data Structures.
+In the method known as **separate chaining**, each bucket is independent, and has some sort of **list** of entries with the same index. In other words, it's defined as a method by which lists of values are built in association with each location within the hash table when a collision occurs.
+
+As each index key is built with a linked list, this means that the table's cells have linked lists governed by the same hash function. So, in place of the collision error which occurred in the figure we used in the last section, the cell now contains a linked list containing the string 'Janet' and 'Martha' as seen in this new figure. We can see in this figure how the subsequent strings are loaded using the separate chaining technique.
+
+
+
+
+
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/6.md b/Leetcode Workshops/Week 1/Act2_HashTables/6.md
new file mode 100644
index 0000000..5c597ce
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/6.md
@@ -0,0 +1,22 @@
+**Type:** comparison left/right
+
+**Title:** Advantages and disadvantages of seprate chaining
+
+_insert slide content here_
+
+### Advantages:
+
+1) Simple to implement.
+2) Hash table never fills up, we can always add more elements to the chain.
+3) Less sensitive to the hash function or load factors.
+4) It is mostly used when it is unknown how many and how frequently keys may be inserted or deleted.
+
+> A load factor is simply the ratio of entires in hash table to size of the array
+
+### Disadvantages:
+
+1) Cache performance of chaining is not good as keys are stored using a linked list. Open addressing provides better cache performance as everything is stored in the same table.
+2) Wastage of Space (Some Parts of hash table are never used)
+3) If the chain becomes long, then search time can become O(n) in the worst case.
+4) Uses extra space for links.
+
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/7.md b/Leetcode Workshops/Week 1/Act2_HashTables/7.md
new file mode 100644
index 0000000..1ca9425
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/7.md
@@ -0,0 +1,36 @@
+**Type:** centered text
+
+**Title:** Open Addressing
+
+
+### Open Addressing
+
+The **open addressing** method has all the hash keys stored in a fixed length table. With this method a hash collision is resolved by **probing**, or searching through alternate locations in the array (the *probe sequence*) until either the target record is found, or an unused array slot is found, which indicates that there is no such key in the table.
+
+We use a hash function to determine the base address of a key and then use a specific rule to handle a collision. Each location in the table is either empty, occupied or deleted.
+
+- **Empty** is the default state of all spaces in the table before any data is ever stored.
+- **Occupied** means that there is currently a key-value pair stored in the location.
+- **Deleted** means there was once a value stored in the space, but it has been marked deleted. Although deleted positions are treated the same as empty positions for the insert operations, those deleted positions are treated as occupied when doing data retrieval.
+
+
+Below are the basic process of inserting a new key (*k*) using open addressing:
+
+1. Compute the position in the table where *k* should be stored.
+
+2. If the position is empty or deleted, store *k* in that position.
+
+3. If the position is occupied, compute an alternative position based on some defined hash function.
+
+The alternative position can be calculated using:
+
+- **linear probing:** distance between probes is constant (i.e. 1, when probe examines consequent slots);
+- **quadratic probing:** distance between probes increases by certain constant at each step (in this case distance to the first slot depends on step number quadratically);
+- **double hashing:** distance between probes is calculated using another hash function.
+
+> A probe is simply the distance from your the current position that is being search to the previous position.
+
+
+
+
+
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/8.md b/Leetcode Workshops/Week 1/Act2_HashTables/8.md
new file mode 100644
index 0000000..fa4b008
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/8.md
@@ -0,0 +1,17 @@
+**Type:img +text**
+
+**Title:**Quadratic Probing
+
+A variation of the linear probing idea is called **quadratic probing**. Instead of using a constant “skip” value, we use a rehash function that increments the hash value by 1, 3, 5, 7, 9, and so on. This means that if the first hash value is *h*, the successive values are ℎ+1, ℎ+4, ℎ+9, ℎ+16, and so on. In other words, quadratic probing uses a skip consisting of successive perfect squares.
+
+Let us assume that the hashed index for an entry is **index** and at **index** there is an occupied slot. The probe sequence will be as follows:
+
+index = index % hashTableSize
+index = (index + 12) % hashTableSize
+index = (index + 22) % hashTableSize
+index = (index + 32) % hashTableSize
+
+and so on...
+
+
+
+
+
+---
+
+_Explanation of code 1_
+
+`sum = 0` runs in constant time as it is simply assigning a value to the variable `sum` and only occurs once. For this line, the runtime is **c1**.
+
+The for loop statement expresses a variable `i` iterating over each element in `value`. This creates a loop that will iterate *n* times since `value` contains *n* elements.
+
+`sum = sum + i` occurs in constant time as well. Let's say this line runs in *c2* time. Since the loop body repeats however many times the loop is iterated, we can multiply *c2* by *n*. Now we have **c2 \* n** for the runtime of the entire for loop.
+
+Lastly, `return sum` is simply returning a number and only happens once. So, this line also runs in constant time which we'll note as **c3**.
+
+Time complexity answers the question: "At what rate does the time increase for a function as the input increases". **However**, it does not answer the question, "How long does it take for a function to compute?", because the answer relies on hardware, language, etc.
+
+For time complexity, functions can grow in **constant time**, **linear time**, **quadratic time**, and so on.
+
+
+
+
+
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/10.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/10.md
new file mode 100644
index 0000000..3564b61
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/10.md
@@ -0,0 +1,29 @@
+Type: text +img
+
+**Title:** Big Omega and Big theta
+
+### Big Omega
+
+Similar to **Big (O)**, we also have **Big Omega**. **Big Omega** is just the opposite; it is the lower bound of our function.
+
+Let's look at our chocolate example again. The same conditions hold true. We can establish the lower bound of how much chocolate you have to be 3/4. Why is this a valid lower bound? Because you will eventually exceed having 3/4 of the chocolate. **Remember when looking for bounds, we want one that holds true after a certain point and not necessarily from the beginning.**
+
+In terms of Python, let's say we have a `functionC` that runs on **O(n)** time. If we have `functionC` which grows on **O(n)** time, that would function as the **Big Omega** for our function, `functionA`.
+
+[//]: # "insert 'functionC vs functionA' image"
+
+`functionA`'s runtime grows faster than `functionC` after a certain point. After that certain point, we know with absolute certainty that the runtime of `functionA` will never be faster than `functionC`.
+
+### Big Theta
+
+Lastly, we have **Big Theta**. Big Theta is simply **Big O**'s formal name. **Big Theta** is the average runtime of a function. Going back to when we were determining the **Big O** notation for a function, we would write each line in the function in **Big O notation**.
+
+For example,
+
+$$
+Time(Input) = O(1) + O(n) + O(1).
+$$
+
+
+We then dropped every term except the fastest growing term (**O(n)**), and made that term define the function. By dropping all the terms, we are estimating the runtime of the function and finding our **Big Theta**.
+
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/2.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/2.md
new file mode 100644
index 0000000..f11f904
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/2.md
@@ -0,0 +1,28 @@
+**Type:** _Text + img_
+
+**Title:** _In what time does a function grow?_
+
+Content:
+
+```python
+value = range(6)
+
+def three(value):
+ sum = 0 #c1
+ return(sum) #c2
+```
+
+`sum = 0` only repeats once, so we know this line will take a constant amount of time **c1**. `return(sum)` also only repeats once, so we can infer that this line carries out in constant time **c2**.
+
+Hence, we predict that `three()` grows in **constant time**.
+
+[
+
+
+
+---
+
+**_code 1 explained_**
+
+Our prediction is true. Since both lines take constant time, adding them up is also still constant time, and our graph looks like a straight line.
+
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/3.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/3.md
new file mode 100644
index 0000000..8ec503e
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/3.md
@@ -0,0 +1,38 @@
+**Type:** _Text+img_
+
+**Title:** _in what time does the function grow ?_
+
+```python
+keypad = [[1, 2, 3],
+ [4, 5, 6],
+ [7, 8, 9],
+ [0]]
+def listInList(keypad):
+ sum = 0
+ for row in keypad: #a*n^2 !Nested loop!
+ for i in row: #b*n
+ sum += i
+ return sum #c
+```
+
+Since our function has a line that repeats itself n^2 times, we predict that this function grows in **quadratic time**. Looking at the graph, we see our prediction is indeed correct. Quadratic runtime starts growing quite quickly in comparison to a linear runtime. Notice that the equation for a quadratic equation is **a\*n^2\*+b\*n\*+c** where a, b and c are constants.
+
+
+
+[](https://camo.githubusercontent.com/204ae4fc13b58550585a953739c400953d8d7c92/68747470733a2f2f70726f6a6563746269742e73332d75732d776573742d312e616d617a6f6e6177732e636f6d2f6461726c656e652f6c6162732f53637265656e2b53686f742b323032302d30322d32312b61742b352e33302e30372b504d2e706e67)
+
+
+
+---
+
+Again, we will be trying to predict what time this function grows in.
+
+If we divide the function into parts, we get the lines `sum = 0`, `sum += i`, and `return sum` . `sum = 0` repeats once, so the time for this line to process is constant.
+
+`sum += i` is in a *for loop* so it might be intuitive to think that this line only repeats *n* times. However, this for loop is nested within another for loop, so the total number of iterations would be *n^2*.
+
+Lastly `return sum` repeats once, so this line will be processed in constant time.
+
+If we graph this out, it will look like the graph below:
+
+Looking at the graph, we see our prediction is indeed correct. Quadratic runtime starts growing quite quickly in comparison to a linear runtime. Something else to note is that the equation for a quadratic equation is **a\*n^2\*+b\*n\*+c** where a, b and c are constants.
\ No newline at end of file
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/4.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/4.md
new file mode 100644
index 0000000..9a37c44
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/4.md
@@ -0,0 +1,29 @@
+**Type:** _code centered_
+
+**Title:** How can we tell the time complexity just from the function?
+
+**Content:**
+
+ To summarize briefly so far, the time of an algorithm or function's run time will be the sum of the time it takes for all the lines in the code of the algorithm to run. This runtime growth can be written as a function.
+
+We can use the fastest growing term to determine the behavior of the equation; in this case, it is the **c2 * n** term. If we simply look at `Time(Input) = c2*n`, we know easily that the function is linear and that the runtime of `valueSum()` is *linear*.
+
+```python
+value = [1, 2, 3, 4, 5]
+
+def valueSum(value):
+ sum = 0 #c1
+ for i in value: #n*c2
+ sum = sum + i
+ return sum #c3
+```
+
+
+
+---
+
+Remember that elementary functions such as `+, -, *, \, =` always take a constant amount of time to run. **Thus, when we see these functions, we assign them the value *c* time.**
+
+From before, we analyzed `valueSum()` line by line and got `f(n) = c2*n + c1 + c3` when we added everything. This equation is actually a function of time where *n* is the input size and *f(n)* is the runtime; we can treat *f(n)* as *Time(Input)*.
+
+
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/5.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/5.md
new file mode 100644
index 0000000..d5d4353
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/5.md
@@ -0,0 +1,34 @@
+**Type:** _code left/right_
+
+**Title:** Finding time complexity
+
+_insert slide content here_
+
+Example 2:
+
+Let's look at the function `three` again. We can treat *c1 + c2* as one constant and call it **c3**. Now we have `T(I) = c3`. This makes it very obvious that the runtime of `three()` is *constant*.
+
+```python
+value = range(6)
+def three(value):
+ sum = 0 #c1
+ return(sum) #c2
+```
+
+Example 3:
+
+Let's do the same for `listInList()`.Putting it into a function, we get `Time(Input) = n^2 + c1 + c2`. If we isolate the fastest growing term, we get `T(I) = n^2` which reveals the runtime to be *quadratic*.
+
+```python
+keypad = [[1, 2, 3],
+ [4, 5, 6],
+ [7, 8, 9],
+ [0]]
+def listInList(keypad):
+ sum = 0 #c1
+ for row in keypad:`
+ for i in row: #n^2
+ sum += i
+ return sum #c2
+```
+
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/6.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/6.md
new file mode 100644
index 0000000..d1bd2a8
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/6.md
@@ -0,0 +1,70 @@
+**Type:** _link+code_
+
+**Title:** _Space Complexity_
+
+_insert slide content here_
+
+Similar to time complexity, as functions' input grows very large, they will take up an increasing amount of memory; this is **space complexity**. In fact, these functions' memory usage also grows in a similar fashion to time complexity and we describe the growth in the same way. We describe it as *linear*, *quadratic*, etc. time.
+
+``` python
+value = [1, 2, 3, 4, 5]
+
+def valueSum(value):
+ sum = 0 #c1
+ for i in value: #c3*n
+ sum = sum + i
+ return sum #c2
+```
+
+To describe the amount of memory this function will require, we will write an expression similar to what was done for *time complexity*. We will call our expression: *Space(Input)* as space is a function of the input.
+
+Our Space(Input) equation should look like:
+
+$$
+Space(Input) = c1 + c2 + c3*n
+$$
+Our equation represented by the dominant (fastest growing) term would simply be **c3 * n**.
+
+**Lets look at another familiar function, `listInList`**
+
+```python
+keypad = [[1, 2, 3],
+ [4, 5, 6],
+ [7, 8, 9],
+ [0]]
+
+def listInList(keypad):
+ sum = 0
+ for row in keypad:
+ for i in row:
+ sum += i
+ return sum
+```
+
+We work with two numbers, `i` and `sum`. These require **c1** and **c2** amount of memory.
+
+Each element in `keypad` will require **c3** amount of memory. We can conclude that the array `keypad` requires **c1 * n^2** amount of memory.
+
+The Space(Input) equation for `keypad` looks something like this.
+
+$$
+Space(Input) = c1 + c2 + c3*n^2
+$$
+Our equation represented by the dominant term would be **c3 * n^2**
+
+**Note:**Prioritize optimizing function run time over optimize memory
+
+---
+
+Let's try and find the Space(Input) equation for this function. To start, let's break down the function line by line. We are working with integers `sum` and `i`, with space values **c1** and **c2** respectively. We have a complex data structure, `value = [1, 2, 3, 4, 5]`, so we know that the amount of memory is **c3 * n** where *n* is the length of the range, `valueSum`.
+
+Similar to time complexity, the amount of memory `keypad` will need is **c1 * n * n**. In other words, **c1 * n^2** Primitive values such as integers, floats, strings, etc. will always take up a constant amount of memory. Complex data structures such as `arrays` take up `k * c` amount of memory where *c* is an amount of memory and *k* is the number of elements in the array. Going back to our `valueSum` function...
+
+## Optimize Time or Optimize Memory?
+
+The greater the input of a function, the greater amount of time and memory that the function will require to operate. A common question is **"Is it better to have our function run faster, but require more space; or should we have our function require less space, but run slower?"**
+
+We can either have our function run faster, but require more memory or our function run slower, but require less memory.
+
+The general answer is to have our function run faster. It is always possible to buy more space/memory. It's impossible to buy extra time. Hence, the general rule is to **prioritize** having our function/algorithm run faster.
+
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/7.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/7.md
new file mode 100644
index 0000000..5e33c95
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/7.md
@@ -0,0 +1,52 @@
+**Type:** slide text
+
+**Title:** Big - O notation
+
+
+
+Now that we have an understanding of *time complexity* and *space complexity* and how to express them as functions of time, we can elaborate on the way we express these functions. **Big-O Notation** is a common way to express these functions.
+
+Instead of using terms like *Linear Time*, *Quadratic Time*, *Logarithmic Time*, etc., we can write these terms in **Big-O Notation**. Depending on what time the function increases by, we assign it a **Big-O** value. **Big-O** notation is incredibly important because it allows us to take a more mathematical and calculated approach to understanding the way functions and algorithms grow.
+
+**Big-O notation** is also useful because it simplifies how we describe a function's time complexity and space complexity. So far, we have defined a function of time as a number of terms. With Big-O notation, we are able to use only the dominant, or fastest growing, term!
+
+## How to Write in Big-O Notation
+
+To write in **Big-O Notation** we use a capital O followed with parentheses : **O()**.
+
+Depending on what is inside of the parentheses will tell us what time the function grows in. Let's look at an example.
+
+```python
+value = [1, 2, 3, 4, 5]
+
+def valueSum(value):
+ sum = 0
+ for i in value:
+ sum = sum + i
+ return sum
+```
+
+Going back to our `valueSum` function, we had previously expressed the runtime of this function as input increase. We had written the expression *Time(Input)* and the components its made of.
+
+**Time(Input) = c1 + c2*n + c3**
+
+`c1` comes from the line `sum = 0` . We know `sum = 0` will always take the same amount of time to run because we are assigning a value to a variable. We call this *constant time* because no matter what function this line is in, it will take the same amount of time to run.
+
+Since **c1** runs in constant time, we would write it as **O(1)** in **Big-O Notation**. Notice that the line repeats only once.
+
+`sum = sum + i` is responsible for **c2** in our equation. We multiply **c2** by *n* however because **c2** is repeated multiple times. The runtime of this function increase linearly depending on the amount of elements that are added to `sum`.
+
+In **Big-O Notation**, this line would be rewritten as **O(n)** and would inform us that this line runs in *linear time*. We use the dominant term which is **c2 * n**. Since **c2 * n** and **n** behave the same (linearly), we can drop the coefficient of *c2*.
+
+Lastly, `return sum` is written as **O(1)** because it operates under constant time.
+
+Rewriting our `valueSum` function but in **Big-O notation**, we would have:
+
+```
+Time(Input) = O(1) + O(n) + O(1).
+```
+
+We've written the lines of the function in **Big-O Notation**, but now we need to write the function itself in **Big-O Notation**. The way we do that is to choose the term that is growing the fastest in the function (the dominant term) as *n* gets very large. We then disregard any coefficients of that term. Then assign that term for the function.
+
+For `valueSum`, the fastest growing term is **c2 * n** . If we ignore **c2** , we are left with just `n`. We now know that the time complexity of `valueSum` is **O(n)** and the runtime of `valueSum` grows in a linear fashion.
+
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/8.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/8.md
new file mode 100644
index 0000000..2841e49
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/8.md
@@ -0,0 +1,72 @@
+**Type:** bold text + img
+
+**Title:** _Big-O continued _
+
+Let's look at another example.
+
+`listInList` expressed as a function of time looks like this:
+$$
+Time(Input) = c1 + c2 * n^2 + c3
+$$
+We know that **c1** corresponds to **O(1)** .
+**c2 * n^2** is written as **O(n^2)**.
+**c3** is written as **O(1)** since it operates under constant time.
+
+As for our last example, let's make a quick edit to our function `listInList` and call it `listInList2`.
+
+```python
+keypad = [[1, 2, 3],
+ [4, 5, 6],
+ [7, 8, 9],
+ [0]]
+def listInList2(keypad):
+ sum = 0
+ for row in keypad:
+ for i in row:
+ sum += i
+ for row in keypad:
+ for i in row:
+ sum += i
+ while sum <= 100:
+ sum += 1
+ return sum
+```
+
+
+
+$$
+T(I) = c1 + (c2 * n^2) + (c2 * n^2) + (c3 * n) + c4
+$$
+
+
+The fastest growing term is **n^2 * c2** but we have two of them. Since **n^2 * c2** corresponds to **O(n^2)**, we are left with:
+
+**Time(Input) = O(n^2) + O(n^2)**
+
+This can simply be rewritten as:
+
+**Time(Input) = 2 * O(n^2)**
+
+
+
+### Time expressed in Big-O Notation
+
+| Time | Big O Notation |
+| ---------------- | -------------- |
+| Constant Time | O(1) |
+| Linear Time | O(n) |
+| Quadratic Time | O(n^2) |
+| Logarithmic Time | O(log n) |
+| Factorial Time | O(n!) |
+
+In the table, there are some other times you should know of. The graph lists the growth of functions from slowest to fastest. A function in **O(1)**'s runtime grows the slowest, and a function in **O(n!)** grows the fastest. Needless to say, we want our functions to be **constant or linear time.**
+
+------
+
+The fastest growing term is **c2 * n^2** so we know that this term defines how our function is written in **Big-O Notation**. Dropping the coefficient, **c2**, our function is expressed as **O(n^2)**. in **Big-O Notation**. This tells us that `listInList` grows in quadratic time.
+
+Notice that we doubled the amount of *for loops* in our function. We have to account for that when writing `listInList2` as a function of time. Since we have extra lines in our code, we need to add a term to our **Time(Input)** expression. To account for a double for loop, we can simply add another **n^2 * c2** to our **Time(Input) expression**.
+
+It might be intuitive to think that our function written in **Big-O notation** would be **2 * O(n^2)** or even **O(2n^2)**, but we have to remember that **Big-O notation only tells us what time a function grows in**. **O(n^2)** and **O(2n^2)** both grow in the same fashion, quadratic, so we can simply write the function as **O(n^2)**.
+
+It is very important to remember that Big-O notation is determined by the fastest growing term as `n` gets very large. When n is small, c3 * n will grow faster than c2 * n^2. **Big-O notation is determined when n is very large** because time and space complexities focus on when inputs are very large; not small.
\ No newline at end of file
diff --git a/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/9.md b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/9.md
new file mode 100644
index 0000000..ee01774
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act1_TimeAndSpaceComplexity/9.md
@@ -0,0 +1,26 @@
+Type: Left img + text
+
+**Title:**Big O
+
+ The **Big O** we have been talking about this entire time is formally known as **Big Theta**. In the work and the industry, **Big Theta** is referred to as simply **Big O**. To avoid confusion, from now on, **Big Theta** will refer to the workplace Big-O and **Big (O)** will be the formal definition.
+
+#### What are they?
+
+**Big (O)** is the upper bound of a function. It describes a function whose curve on a graph, at least after a certain point on the x-axis (input size), will always be higher on the y-axis (time) than the curve of the runtime.
+
+To explain in simpler terms, let's say I have a chocolate bar. I give you half of the chocolate bar, then half of the chocolate I have leftover, then half of the new leftover, and so on. Theoretically, this could go on forever and eventually how much chocolate you have will converge to some amount. We can set an *upper bound* for how much chocolate you have to be 1; we have just applied the **Big (O)** concept. No matter how long this exchange goes on for, I will always be holding onto some tiny bit of the chocolate. The amount of chocolate that you have won't actually reach an entire bar, but you may be very close!
+
+We could have chosen our upper bound to be as high as we want. Let it be 1 million and we can say for 100% certainty that we won't be wrong. However, this isn't very useful because we are allowing such a wide range which is why it is best if we try to establish the smallest range possible.
+
+Let's apply this concept to Computer Science terms.
+
+Let's say that `functionA` runs in **O(n^2) time**. If we compare it to `functionB` , which runs in **O(n!)** time, we know that `functionA`'s runtime will never exceed `functionB`'s runtime.
+
+
+
+You can see the runtime of **O(n)** never exceeds the runtime of **O(n!)**
+
+##### Why is this useful?
+
+In the absolute worst case scenario, we know the ceiling of `functionA`'s runtime. We are then able to prepare for it and ensure that our computer or hardware will be able to handle running the function.
+
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/1.md b/Leetcode Workshops/Week 1/Act2_HashTables/1.md
new file mode 100644
index 0000000..9943b79
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/1.md
@@ -0,0 +1,15 @@
+**Type:** _text + image _
+
+**Title:** Hash Tables, Hash functions
+
+_insert slide content here_
+
+
+
+**Hash tables** are a type of data structure in which the address or the index value of the data element is generated from a hash function. A **hash function** is any function that can be used to map data of arbitrary size to fixed-size values. The values returned by a hash function are called **hash values**. The values are used to index a fixed-size table which is the Hash table. Use of a hash function to index a hash table is called **hashing**.
+
+
+
+That makes accessing the data faster than can be done with many other data structures. For example, accessing data in Linked Lists could potentially take much longer, as one would have to loop through the list until the desired data is aquired. If you wished to find the last element in the list, you would have to go through the *entire* list! In Hash Tables, on the other hand, the index value behaves as a key for the data value. In other words, a Hash table stores key-value pairs but the key is generated through a hashing function and this key can be used to access the element.
+
+Thus, the search and insertion functions of a data element (which rely on accessing data) become much faster as the key values themselves become the index of the array, which stores the data.
\ No newline at end of file
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/10.md b/Leetcode Workshops/Week 1/Act2_HashTables/10.md
new file mode 100644
index 0000000..b6d0bee
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/10.md
@@ -0,0 +1,15 @@
+**Type:** centered text
+
+**Title:** Hash Tables in Python
+
+As you now know, Hash tables are a type of data structure in which the address or the index value of the data element is generated from a hash function. That makes accessing the data faster as the index value behaves as a key for the data value. In other words Hash table stores key-value pairs but the key is generated through a hashing function.
+
+So the search and insertion function of a data element becomes much faster as the key values themselves become the index of the array which stores the data.
+
+However, when we talk about **hash tables**, we're actually talking about a **dictionary**. In Python, the Dictionary data types represent the implementation of hash tables. The Keys in the dictionary satisfy the following requirements.
+
+- The keys of the dictionary are hashable i.e. the are generated by hashing function which generates unique result for each unique value supplied to the hash function.
+- The order of data elements in a dictionary is not fixed.
+
+Dictionaries in python are implemented through Hashtables. Dictionaries won't be covered extensively in this activity, but this an interesting piece of information to take note of.
+
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/2.md b/Leetcode Workshops/Week 1/Act2_HashTables/2.md
new file mode 100644
index 0000000..a2fdcd1
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/2.md
@@ -0,0 +1,56 @@
+**Type:** img + text
+
+**Title:** Hash Tables: Hashing and Hash Functions
+
+_insert slide content here_
+
+
+
+**Hashing** is a technique that is used to uniquely identify a specific object from a group of similar objects. Some examples of how hashing is used in our lives include:
+
+- In universities, each student is assigned a unique roll number that can be used to retrieve information about them.
+- In libraries, each book is assigned a unique number that can be used to determine information about the book, such as its exact position in the library or the users it has been issued to etc.
+
+In both these examples the students and books were hashed to a unique number.
+
+In hashing, large keys are converted into small keys by using **hash functions**. The values are then stored in a data structure called a **hash table**. The idea of hashing is to distribute entries (key/value pairs) uniformly across an array. Each element is assigned a key (converted key). By using that key you can access the element in **O(1)** time. **O(1)** in this context means that data can be accessed in constant time, regardless of how large our Hash Table is! Using the key, the algorithm (hash function) computes an index that suggests where an entry can be found or inserted.
+
+The image below will show you an example about how hasing itself works.
+
+
+
+
+Hashing is implemented in two steps:
+
+1. An element is given an integer by using a hash function. This integer can be used as an index to store and access the original element, which falls into the hash table.
+
+2. The element is stored in the hash table where it can be quickly retrieved using hashed key.
+
+ hash = hashfunc(key)
+ index = hash % array_size
+
+After performing these two steps, the hash is independent of the array size and it is then reduced to an index (a number between 0 and array_size − 1) by using the modulo operator (%). Now you're probably wondering about how you can map data sets to each other no matter the size. That's where the hash function comes in.
+
+> Reminder, the modulo operator (%) has two arguments and returns the remainder after division between the two numbers.
+
+**Hash function**
+A hash function is any function that can be used to map a data set of an arbitrary size to a data set of a fixed size, which falls into the hash table. The values returned by a hash function are called hash values, hash codes, hash sums, or simply hashes.
+
+To achieve a good hashing mechanism, It is important to have a good hash function with the following basic requirements:
+
+1. Easy to compute: It should be easy to compute and must not become an algorithm in itself.
+
+2. Uniform distribution: It should provide a uniform distribution across the hash table and should not result in clustering.
+
+3. Less collisions: Collisions occur when pairs of elements are mapped to the same hash value. These should be avoided.
+
+ **Note**: Irrespective of how good a hash function is, collisions are bound to occur. Therefore, to maintain the performance of a hash table, it is important to manage collisions through various collision resolution techniques.
+
+ ------
+
+ Assume that you have an object and you want to assign a key to it to make searching easy. To store the key/value pair, you can use a simple array like a data structure where keys (integers) can be used directly as an index to store values. So you're wondering about what happens when your keys get very large to the point where you can't even use them as an index. This is where the actual hashing comes in.
+
+
+ To truly appreciate hashing, one must have a basic understanding of Big-O notation and time complexity of algorithms. Time complexity refers to how an algorithm performs as input size becomes infinitely large. Big-O notation is used to define an upper bound on this performance. Understanding Big-O notation allows one to know the general worst-case time performance of certain algorithms or operations on a data structure, which can be important for a programmer in deciding which data structure to use.
+
+ While time complexity is a massive topic in Computer Science, for our purposes, we will focus on **O(1)** time, which is Big-O notation for constant time. This means that the time that an algorithm takes to perform a certain procedure is **independent** of the size of the input.
\ No newline at end of file
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/3.md b/Leetcode Workshops/Week 1/Act2_HashTables/3.md
new file mode 100644
index 0000000..b96303e
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/3.md
@@ -0,0 +1,60 @@
+**Type:** comparison left/right
+
+**Title:** Need for a good hash function
+
+_insert slide content here_
+
+
+
+Let us understand the need for a good hash function. Assume that you have to store strings in the hash table by using the hashing technique {“abcdef”, “bcdefa”, “cdefab” , “defabc” }.
+
+The hash function will compute the same index for all the strings and the strings will be stored in the hash table in the following format. As the index of all the strings is the same, you can create a list on that index and insert all the strings in that list.
+
+
+
+> Note: here, it will take **O(n)** time (where n is the number of strings) to access a specific string. This shows that the hash function is not a good hash function.
+
+* *
+
+| ASCII Value | Letter |
+| ----------- | ------ |
+| 97 | a |
+| 98 | b |
+| 99 | c |
+| 100 | d |
+| 101 | e |
+| 102 | f |
+
+> Chart for Ascii Values
+
+Here, it will take **O(n)** time (where n is the number of strings) to access a specific string. This shows that the hash function is not a good hash function.
+
+
+
+Let’s try a different hash function. The index for a specific string will be equal to sum of ASCII values of characters multiplied by their respective order in the string after which it is modulo with 2069 (prime number).
+
+String Hash function Index
+abcdef (97*1 + 98*2 + 99*3 + 100*4 + 101*5 + 102*6)%2069 38
+bcdefa (98*1 + 99*2 + 100*3 + 101*4 + 102*5 + 97*6)%2069 23
+cdefab (99*1 + 100*2 + 101*3 + 102*4 + 97*5 + 98*6)%2069 14
+defabc (100*1 + 101*2 + 102*3 + 97*4 + 98*5 + 99*6)%2069 11
+
+
+
+>Calculating the value for 'abcdef'.
+>a = 97 * 1 // It is in the first position
+>b = 98*2 // it is in the second position
+>c = 99*3 // It is in the third position
+>d = 100*4 // It is in the fourth position
+>e = 101*5 // it is in the fifth position
+>f = 102*6 // It is in the sixth position
+
+**Note :**So overall, when you're implementing the hash table depending on the size of your list, you want to create the best hash table thatcan hash the values in your list in the most efficient time.
+
+------
+
+To compute the index for storing the strings, use a hash function that states the following:
+
+The index for a specific string will be equal to the sum of the ASCII values of the characters modulo 599.
+
+As 599 is a prime number, it will reduce the possibility of indexing different strings (collisions). It is recommended that you use prime numbers in case of modulo. The ASCII values of a, b, c, d, e, and f are 97, 98, 99, 100, 101, and 102 respectively. Since all the strings contain the same characters with different permutations, the sum will 599.
\ No newline at end of file
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/4.md b/Leetcode Workshops/Week 1/Act2_HashTables/4.md
new file mode 100644
index 0000000..bfddf67
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/4.md
@@ -0,0 +1,32 @@
+**Type:** bold text + img
+
+**Title:** Collision Resolution Techniques
+
+_insert slide content here_
+
+The pupose of a hash table is to assign each key to a unique slot, but sometimes it is possible that two keys will generate an identical hash causing both keys to point to the same slots. They are known as **hash collisions**.
+
+> A bucket is simply a fast-access location (like an array index) that is the the result of the hash function.
+
+
+
+The figure shows incidences of **collisions** in different table locations. We'll assign strings as our input data: `[John, Janet, Mary, Martha, Claire, Jacob, and Philip]`.
+
+Our hash table size is 6. As the strings are evaluated at input through the hash functions, they are assigned index keys `(0, 1, 2, 3, 4, or 5)`. We store the first string `John`, then `Janet` and `Mary`. All is fine, but when we try to store `Martha`, the hash function assigns `Martha` the same index key as `Janet`.
+
+Now, because a second value is attempting to map to an already occupied index key, a **collision** occurs as seen in figure we've been using. Three out of the six locations are occupied, and the probability that the remaining strings yet to be loaded will cause other **collisions** is very high.
+
+
+
+So we now return to the problem of collisions. When two items hash to the same slot, we must have a systematic method for placing the second item in the hash table. This process is called **collision resolution**.
+
+
+
+### How to handle Collisions?
+
+There are mainly two methods to handle collision:
+
+- 1) Separate Chaining
+- 2) Open Addressing
+
+We will elaborate further on these concepts in the following cards.
\ No newline at end of file
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/5.md b/Leetcode Workshops/Week 1/Act2_HashTables/5.md
new file mode 100644
index 0000000..ccc5be7
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/5.md
@@ -0,0 +1,17 @@
+**Type:** _text + img_
+
+**Title:** Seprate Chaining
+
+_insert slide content here_
+
+
+
+In this card, we will exploring a methodk nown as **separate chaining** which is an essential part of Data Structures.
+In the method known as **separate chaining**, each bucket is independent, and has some sort of **list** of entries with the same index. In other words, it's defined as a method by which lists of values are built in association with each location within the hash table when a collision occurs.
+
+As each index key is built with a linked list, this means that the table's cells have linked lists governed by the same hash function. So, in place of the collision error which occurred in the figure we used in the last section, the cell now contains a linked list containing the string 'Janet' and 'Martha' as seen in this new figure. We can see in this figure how the subsequent strings are loaded using the separate chaining technique.
+
+
+
+
+
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/6.md b/Leetcode Workshops/Week 1/Act2_HashTables/6.md
new file mode 100644
index 0000000..5c597ce
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/6.md
@@ -0,0 +1,22 @@
+**Type:** comparison left/right
+
+**Title:** Advantages and disadvantages of seprate chaining
+
+_insert slide content here_
+
+### Advantages:
+
+1) Simple to implement.
+2) Hash table never fills up, we can always add more elements to the chain.
+3) Less sensitive to the hash function or load factors.
+4) It is mostly used when it is unknown how many and how frequently keys may be inserted or deleted.
+
+> A load factor is simply the ratio of entires in hash table to size of the array
+
+### Disadvantages:
+
+1) Cache performance of chaining is not good as keys are stored using a linked list. Open addressing provides better cache performance as everything is stored in the same table.
+2) Wastage of Space (Some Parts of hash table are never used)
+3) If the chain becomes long, then search time can become O(n) in the worst case.
+4) Uses extra space for links.
+
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/7.md b/Leetcode Workshops/Week 1/Act2_HashTables/7.md
new file mode 100644
index 0000000..1ca9425
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/7.md
@@ -0,0 +1,36 @@
+**Type:** centered text
+
+**Title:** Open Addressing
+
+
+### Open Addressing
+
+The **open addressing** method has all the hash keys stored in a fixed length table. With this method a hash collision is resolved by **probing**, or searching through alternate locations in the array (the *probe sequence*) until either the target record is found, or an unused array slot is found, which indicates that there is no such key in the table.
+
+We use a hash function to determine the base address of a key and then use a specific rule to handle a collision. Each location in the table is either empty, occupied or deleted.
+
+- **Empty** is the default state of all spaces in the table before any data is ever stored.
+- **Occupied** means that there is currently a key-value pair stored in the location.
+- **Deleted** means there was once a value stored in the space, but it has been marked deleted. Although deleted positions are treated the same as empty positions for the insert operations, those deleted positions are treated as occupied when doing data retrieval.
+
+
+Below are the basic process of inserting a new key (*k*) using open addressing:
+
+1. Compute the position in the table where *k* should be stored.
+
+2. If the position is empty or deleted, store *k* in that position.
+
+3. If the position is occupied, compute an alternative position based on some defined hash function.
+
+The alternative position can be calculated using:
+
+- **linear probing:** distance between probes is constant (i.e. 1, when probe examines consequent slots);
+- **quadratic probing:** distance between probes increases by certain constant at each step (in this case distance to the first slot depends on step number quadratically);
+- **double hashing:** distance between probes is calculated using another hash function.
+
+> A probe is simply the distance from your the current position that is being search to the previous position.
+
+
+
+
+
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/8.md b/Leetcode Workshops/Week 1/Act2_HashTables/8.md
new file mode 100644
index 0000000..fa4b008
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/8.md
@@ -0,0 +1,17 @@
+**Type:img +text**
+
+**Title:**Quadratic Probing
+
+A variation of the linear probing idea is called **quadratic probing**. Instead of using a constant “skip” value, we use a rehash function that increments the hash value by 1, 3, 5, 7, 9, and so on. This means that if the first hash value is *h*, the successive values are ℎ+1, ℎ+4, ℎ+9, ℎ+16, and so on. In other words, quadratic probing uses a skip consisting of successive perfect squares.
+
+Let us assume that the hashed index for an entry is **index** and at **index** there is an occupied slot. The probe sequence will be as follows:
+
+index = index % hashTableSize
+index = (index + 12) % hashTableSize
+index = (index + 22) % hashTableSize
+index = (index + 32) % hashTableSize
+
+and so on...
+
+ +
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/9.md b/Leetcode Workshops/Week 1/Act2_HashTables/9.md
new file mode 100644
index 0000000..0213e96
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/9.md
@@ -0,0 +1,16 @@
+**Type:** text img
+
+**Title**: Double Hashing
+
+Double hashing is similar to linear probing and the only difference is the interval between successive probes. Here, the interval between probes is computed by using two hash functions.
+
+Let us say that the hashed index for an entry record is an index that is computed by one hashing function and the slot at that index is already occupied. You must start traversing in a specific probing sequence to look for an unoccupied slot. The probing sequence will be:
+
+index = (index + 1 * indexH) % hashTableSize;
+index = (index + 2 * indexH) % hashTableSize;
+
+and so on…
+
+It uses one hash value as an index into the table and then repeatedly steps forward an interval until the desired value is located, an empty location is reached, or the entire table has been searched; but this interval is set by a second, independent hash function. Unlike the alternative collision-resolution methods of linear probing and quadratic probing, the interval depends on the data, so that values mapping to the same location have different bucket sequences; this minimizes repeated collisions.
+
+
\ No newline at end of file
diff --git a/Linear Probing.md b/Linear Probing.md
new file mode 100644
index 0000000..6d565ec
--- /dev/null
+++ b/Linear Probing.md
@@ -0,0 +1,19 @@
+Type: text+img
+
+**Title:** Linear probing
+
+By systematically visiting each slot one at a time, we are performing an open addressing technique called **linear probing**. When the hash function causes a collision by mapping a new key to a cell of the hash table that is already occupied by another key, linear probing searches the table for the closest following free location and inserts the new key there. Lookups are performed in the same way, by searching the table sequentially starting at the position given by the hash function, until finding a cell with a matching key or an empty cell.
+
+Considering the interval between successive probes is fixed (usually to 1), let’s assume that the hashed index for a particular entry is **index**. The probing sequence for linear probing will be:
+
+index = index % hashTableSize
+index = (index + 1) % hashTableSize
+index = (index + 2) % hashTableSize
+index = (index + 3) % hashTableSize
+
+and so on...
+
+
+
+> The collision between John Smith and Sandra Dee (both hashing to cell 873) is resolved by placing Sandra Dee at the next free location, cell 874.
+
+
diff --git a/Leetcode Workshops/Week 1/Act2_HashTables/9.md b/Leetcode Workshops/Week 1/Act2_HashTables/9.md
new file mode 100644
index 0000000..0213e96
--- /dev/null
+++ b/Leetcode Workshops/Week 1/Act2_HashTables/9.md
@@ -0,0 +1,16 @@
+**Type:** text img
+
+**Title**: Double Hashing
+
+Double hashing is similar to linear probing and the only difference is the interval between successive probes. Here, the interval between probes is computed by using two hash functions.
+
+Let us say that the hashed index for an entry record is an index that is computed by one hashing function and the slot at that index is already occupied. You must start traversing in a specific probing sequence to look for an unoccupied slot. The probing sequence will be:
+
+index = (index + 1 * indexH) % hashTableSize;
+index = (index + 2 * indexH) % hashTableSize;
+
+and so on…
+
+It uses one hash value as an index into the table and then repeatedly steps forward an interval until the desired value is located, an empty location is reached, or the entire table has been searched; but this interval is set by a second, independent hash function. Unlike the alternative collision-resolution methods of linear probing and quadratic probing, the interval depends on the data, so that values mapping to the same location have different bucket sequences; this minimizes repeated collisions.
+
+
\ No newline at end of file
diff --git a/Linear Probing.md b/Linear Probing.md
new file mode 100644
index 0000000..6d565ec
--- /dev/null
+++ b/Linear Probing.md
@@ -0,0 +1,19 @@
+Type: text+img
+
+**Title:** Linear probing
+
+By systematically visiting each slot one at a time, we are performing an open addressing technique called **linear probing**. When the hash function causes a collision by mapping a new key to a cell of the hash table that is already occupied by another key, linear probing searches the table for the closest following free location and inserts the new key there. Lookups are performed in the same way, by searching the table sequentially starting at the position given by the hash function, until finding a cell with a matching key or an empty cell.
+
+Considering the interval between successive probes is fixed (usually to 1), let’s assume that the hashed index for a particular entry is **index**. The probing sequence for linear probing will be:
+
+index = index % hashTableSize
+index = (index + 1) % hashTableSize
+index = (index + 2) % hashTableSize
+index = (index + 3) % hashTableSize
+
+and so on...
+
+
+
+> The collision between John Smith and Sandra Dee (both hashing to cell 873) is resolved by placing Sandra Dee at the next free location, cell 874.
+