[TOC]
-
재귀호출을 이용하는 N팩토리얼 구하기
-
그래프에서최적 경로를 구하는 다익스트라 알고리즘
-
정적분의 값을 구하는 사다리꼴 알고리즘
-
연립 방정식의 해를 구하는 가우스 소거법
-
구글같은 포털에 사용하는 검색 알고리즘
- 웹 검색 / 페이지 링크
-
DB의 일관성을 위한 알고리즘
- 데이터의 유일성과 정확성을 위한 알고리즘
-
데이터 전송에 따른 오류 정정 알고리즘
- 네트워크나 디스크 처리에서 발생하는 오류를 자동 정정해 주는 알고리즘
-
암호의 혁명, 개인키 / 공개키 알고리즘
-
데이터 압축 알고리즘
- ZIP파일로 유명한 데이터 압축 알고리즘
-
매칭 : 검색에 부합되는 페이지를 찾는 작업
- 매칭을 수행하는 기법 : 인덱스 / 구문쿼리 / 적합성 / 메타워드
-
랭킹 : 찾은 페이지를 대상으로 순서를 정하는 작업
- 랭킹을 수행하는 기법 : 하이퍼링크 알고리즘 / 권위 알고리즘 / 무작위 서퍼 알고리즘
-
최초 도입
-
인덱스 알고리즘 :
- 각 단어가 있는 페이지의 번호를 정리
-
한계 : 특정 단어가 포함된 페이지 검색에는 유용. 그러나 특정 문장을 포함하는 문서 검색에 사용할 수 없음
-> 구문 쿼리 기법
- 여러 개의 단어가 나오는 경우를 찾는 것
- 구문쿼리 알고리즘 :
- 해당 단어가 있는 페이지의 번호와 위치 저장
- 특정 단어가 붙어있는 경우를 찾아 해당 페이지를 보여줌
- 한계
- 어느 것이 사용자 요구에 더 적합한지 판단할 수 없음 - > 적합성
- 검색에 사용된 단어가 서로 가까이 있는 것이 멀리 있는 것보다 사용자의 요구에 적합하다는 이론
- 적합성 알고리즘
- 해당 단어가 있는 페이지의 번호와 위치 저장
- 해당 단어들이 더 가까이에 있는 페이지 보여줌
- 한계
- 사용자가 원하는 페이지 정확하게 선택하지 못함 -> 메타워드 기법
-
웹 페이지 내용을 특정 메타워드로 마크하여 활용하는 방법 ex) 제목에 truck이 있는 문서
-
메타워드
<titlestart> my car <titleend> <bodystart> the car ran on the road <bodyEnd><titlestart> my truck <titleend> <bodystart> the truck stood on the road <bodyEnd><titlestart> my vehicle <titleend> <bodystart> the vehicle stood on the road while a truck ran<bodyEnd>truck in TITLE 이라는 쿼리 처리
- truck에서 2-3, 2-7, 3-11 찾는다 (문서 번호와 위치)
- IN TITLE 에서 1-1, 2-1, 3-1 , 1-4, 2-4, 3-4
- In TITLE에서 찾은 위치 사이에 truck이 들어가 있는 페이지를 찾는다.
- 2페이지의 truck은 2-3에 있고, 이것은 2-1, 2-4 사이에 있으므로 제목에 있다
- 결론은 2번 문서
- 특정 페이지에 링크가 많이 걸려 있다면 고객의 요구에 부합할 가능성이 높음
- 부정적 의미로 링크된 것에대한 고려가 없음
- 링크에 가중치를 부여
- 사이클이 형성되는 경우에는 특정 페이지의 점수가 계속 올라가는 문제가 있음
-
구글 검색의 근간
-
하이퍼링크와 권위 트릭 알고리즘의 장점 포함
-
현재 구성된 페이지 사이 링크를 따라 서핑을 수행하고, 이것을 기반으로 방문 빈도에 따른 중요성을 평가
-
컴퓨터가 수행하는 동작
- 계산 수행 : 데이터 조작
- 데이터 저장 : 입력된 데이터를 저장
- 데이터 전송 : 데이터를 필요한 곳으로 전송. 정확하게 전송하는 것이 중요.
-
데이터 전송 에러를 고치는 방법
-
오류 검출 + 정정
- 반복알고리즘
- 리던던시 알고리즘 : 패리티 검사 코드 사용
-
오류 점출 + (에러시)재전송
- 체크섬(CheckSum), 계단 체크섬 알고리즘
- 핀 포인트(Pin Point) 알고리즘
-
-
컴퓨터에 사용하는 오류 정정 알고리즘의 종류
- CD, DVD, 하드 디스크 : 계산 체크섬 + 핀 포인트 트릭 결합
- 인터넷 : 체크섬 트릭
- 동일한 데이터를 반복해서 보내주고, 수신측에서는 받은 데이터에서 항목별로 가장 빈도수가 많은 것을 선택
- 신뢰할 근거가 있지만, 요즘처럼 큰 소프트웨어와 자료를 다루는 시기에는 적합치 않다.
- 보내는 데이터에 정보 (잉여정보, Redundancy)를 추가해서 보내는 방법
- 해밍코드 알고리즘
-
통신 오류 검출에 집중 / 대부분의 인터넷 접속
-
체크섬 알고리즘 : 데이터 합의 마지막 자리를 취하는 것은 대부분의 경우 유용하지만, 데이터에 2개의 오류가 있는 경우에 체크섬이 같을 수 있다.
- 보내는 데이터가 4,5,7,5,6 이라고 가정한다.
- 데이터를 모두 합한다 = 28
- 합한 수의 마지막을 취한다. (체크섬 ) : 8
- 체크섬을 포함하여 보내야 할 자료를 구성한다. : 4,5,7,5,6,8
- 자료를 보낸다.
- 수신한 자료의 앞의 5자리를 더하고, 결과의 마지막 수가 8인지 확인한다.
- 8이면 데이터 정확한 것, 아니면 재전송 요청
-
계단 체크섬 알고리즘 : 체크섬이 2개의 에러를 가지면 체크섬이 같을 수도 있으므로 이를 보완.
-
보내는 데이터가 4,6,7,5,6 이라고 가정한다.
-
데이터를 그냥 합치지 않고, 아래와 같이 한다.
: (1 * 4) + (2 * 6) + ( 3 * 7 ) + (4 * 5) + (5 * 6) = 87 : 체크섬은 7이다.
-
합한 수의 마지막을 취한다. 체크섬 : 7
-
체크섬을 포함하여 보내야 할 자료를 구성한다. 4,6,7,5,6,7
-
자료를 보낸다.
-
수신자 자료의 앞의 다섯자리를 대상으로 두 번쨰 과정 수행하여 결과가 7인지 확인
-
7이면 정확, 아니면 재전송 요청
-
-
체크섬 + 계단 체크섬 : 1개나 2개의 에러가 있는 경우 이를 이용해 확인이 가능하다.
- 원본 4,6,7,5,6 8,7( 체크섬, 계단체크섬 )
- 1개 오류 1,6,7,5,6 5,4
- 2개 오류 1,5,7,5,6 4,2
- 2개 오류 2,8,7,5,6 8,7
- 2개 오류 6,5,7,5,7 9,7
-
체크섬은 큰자료의 전송에는 사용하기 어렵다. 데이터를 보낼 ㄸ 수행하는 연산이 전체 시스템의 속도에 크 영향을 주기 때문이다. 하지만, 시스템에 적용할만한 명확한 논리와 근거를 갖춘 방법이다.
-
핀 포인트 알고리즘은 2차원 패리티. 비효율적.
-
행과 열을 대상으로 체크섬을 마늘고 이것을 전체적으로 풀어서 전송.
-
수신된 데이터를 재조립 후 체크섬 계산
-
행과 열을 이용해 문제 발생 위치를 정확하게 찾을 수 있다.
-
무손실 압축 (Loseless Compression): 압축한 후 다시 압축을 풀면 원래의 상태로 돌아옴
-
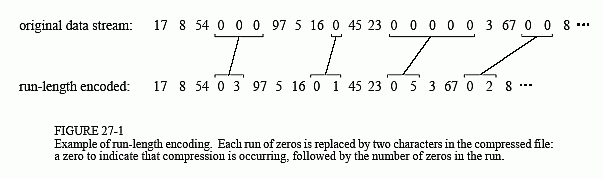
Run-Length Encoding
-
LZ77 : 한 번 이상 사용한 문자열은 기존 문자열의 상대적 위치와 일치한 길이만 저장
-
섀넌-파노 코딩, 허프만 코딩 : JPEG, MPEG 등 화상 정보 압축 표준 규격에 주소 사용
-
압축의 효율이 높다.
-
압측 시간이 많이 소요되기 때문에 정보통신 분야에서는 잘 쓰이지 않는다.
-
-
-
손실 압축 (Lossy Compression) : 무손실보다 높은 압축률을 가지는 방식, 주로 오디오 데이터. 일부 데이터가 손실되어도 사람의 감각기관이 큰 차이를 느끼지 못함.
- 예측 부호
- 변환 부호화
- 계층 부호화
- 벡터 양자화
-
혼합 압축 (Hybrid Compression) : 손실 + 무손실
-
JPEG : 이미지를 8 x 8의 크기로 분리하고, 분리된 단위별로 압축 수행. 압축 방법은 다양
-
8 x 8이 모두 같은 색이라면, 하나의 수로 치환
-
거의 동일하다면, 하나의 수로 치환
-
하나의 색에서 다른 색으로 점차 변하면 두개의 수로 치환
-
-
MPEG : 동영상 압축 표준
-
JPEG의 원리에 기반을 두어 개발.
-
동영상 첫 장면은 JPEG로 압축해서 전송하고, 두번째 장면부터는 단순히 이동하는 모션 벡터 정보만 전송하여 총 데이터 양 감소시킴
-
두가지 핵심기술
이전 프레임과 현재의 차이를 이용하여 움직임을 추정하고 이를 보상
유효 데이터의 최소화를 위한 변환 기법
-
MPEG의 종류
MPEG1 : CD, HDD등의 저장 매체용 압축 규격
MPEG2 : 방송을 위한 압축 규격
MPEG4 : 통신을 대상으로 하는 압축 규격
MPEG7 : 웹에서 오디오, 비디오 데이터를 검색할 수 있도록 멀티미디어 정보가 포함된 압축 규격
-
-
H.261
-
-
컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발.
-
분류와 군집화를 통하여 기능을 수행하며, 컴퓨턱 다음과 같이 학습할 수 있도록 합니다.
( 참고 : https://marobiana.tistory.com/155 )
- 지도 학습 (Supervised Learning) : 정답을 알려주며 학습
- 분류
- 회귀 - 특징(feature)을 토대로 값을 예측(결과는 실수 값을 가질 수 있음 => 연속성)
- 비지도(자율) 학습 (Unsupervised Learning) : 사람 없이 컴퓨터가 스스로 데이터 학습
- 정확한 정답(label)을 알려주지 않고, 비슷한 데이터를 군집화
- 실무에서는 지도학습에서의 적정한 feature를 찾기 위한 전처리 방법으로 비지도 학습을 쓰기도 한다.
- 강화 학습 : 상과 벌이라는 보상(reward)을 주며 상을 최대화하고 벌을 최소화하도록 학습하는 방식 (ex.알파고)
- 주로 게임에서 최적의 동작을 찾는데 쓰는 학습 방식
- 정확한 답은 없지만 반복적인 행동을 통해 칭찬과 벌을 받아가며 가중치를 최대화(최적화?) 하는 것이 목표.
- 지도 학습 (Supervised Learning) : 정답을 알려주며 학습
- 시냅스의 결합으로 네트워크를 형성한 인공 뉴런이 학습을 통해 시냅스의 결합 세기를 변화지켜 문제 해결능력을 가지는 알고리즘
- 다양한 종류의 인공 신경망을 '복합적으로', '아주 깊게' 쌓는 것으로 사람의 사고방식을 컴퓨터에게 가르치는 기계학습의 한 분야.
- 암호의 개념(by 섀넌) : 평문 -> 암호화 -> 전달 -> 복호화 -> 평문
- 현대 암호학이 섀넌의 개념을 이행하는 두가지 방법
- 대칭키(Symmetric-Key) : 암호화하는 것과 푸는 것이 하나의 키로 이루어짐 - DES, AES
- 비대칭키 : 암호화하는 것과 푸는 키가 서로 다름 - RSA (암복호화 방식: 키가 한 쌍을 이룸)
- 1970년대 이후로 대칭키보다 비대칭키를 주로 사용
https://steemit.com/kr/@yahweh87/14-2-n
-
공개키로 잠궜으면 개인키로 열고, 개인키로 잠궜으면 공개키로 연다 -> 비대칭 암호 방식
- 공개키로 암호화된 메시지는 오직 개인키로만 복호화할 수 있다.
- 개인키로 암호화된 메시지는 오직 공개키로만 복호화할 수 있다.
-
A가 B의 공개키를 이용해서 메시지를 암호화하여 B에게 전달
- B는 암호화에 사용된 공개키와 짝을 이루는(?!) 개인키를 갖고 있기 때문에 복호화 가능!
- 즉, B만 볼 수 있는 정보의 기밀성이 보장
-
A가 A의 개인키를 이용해서 메시지를 암호화하며 B에게 전달
-
B는 A의 공개키를 알 수 있으므로, A의 공개키를 이용해서 복호화 가능
-
정보의 기밀성 없음, 오직 A만 만들 수 있다
-
전자서명에 이용(신원확인, 공인인증체계)
-
-
A가 A의 공개키를 이용해서 메시지를 암호화 하여 B에게 전달
-> 복호화 못함
-
A가 B의 개인키를 이용해서 메시지를 암호화하여 B에게 전달
-> A는 B의 개인키를 이용할 수 없어서 메시지 암호화 불가.
3) 인증서
-
참고 : https://rsec.kr/?p=426) <- ★★★★★★★★★★
-
현재 우리가 사용하고 있는 브라우저에는 여러 인증서들이 이미 포함되어 있다. 이 인증서는 여러 기관 CA (Certificate Authority)에서 발행한 인증서들이 포함되어 있는데 이러한 인증서 들은 SSL/TLS로 서비스되는 웹사이트에 접속하게 될 때 사용하게 될 공개키의 무결성을 검증하는데 사용됩니다.

-
인증기관 (CA, ex.동사무소)가 나의 공개키 (웹사이트 인증서 ex.인감)을 보증하기 위해서 서명을 하게 되는데 여기서 서명이란 나의 공개키가 ㅐ쉬된 값을 인증기관의 비밀키로 암호화 한 결과값을 디지털 서명이라 한다.
- 공개키에 대해서 (해쉬한 후 ) 인증 기관의 비밀키로 암호화 함
- 역으로 인증기관(CA)에서 발행한 공개키로 이 디지털 서명값을 복호화하면 인증서에 대한 해쉬값을 얻을 수 있음
- 인증서에 등록되어 있는 해쉬값과 인증기관에서 발행한 공개키로 서명값을 복호화해서 나온 해쉬값이 서로 동일하면 인증서의 내용과 공개키가 위변조 되지 않았음을 보증할 수 있음.
- 공인인증서
- 전자 서명의 검즈에 필요한 공개키에 소유자 정보를 추가하여 만든 일종의 전자 신분증
- 한국에서만 정의되는 것으로 파일에 대한 선자 서명(공개키 기반)을 파일형태(NPKI)로 관리
- 디지털 서명은 국제 표준으로 파일에 대한 인증이 목적