diff --git a/.markdownlint.json b/.markdownlint.json
index 9d78e7f46f..e08d8929bb 100644
--- a/.markdownlint.json
+++ b/.markdownlint.json
@@ -11,6 +11,8 @@
"no-multiple-blanks": {
"maximum": 2
},
+ "table-column-style": false,
+ "ul-indent": false,
"no-space-in-emphasis": false,
"link-fragments": false,
"no-duplicate-heading": {
diff --git a/sources/academy/build-and-publish/actor-ideas/what_software_an_actor_can_be.md b/sources/academy/build-and-publish/actor-ideas/what_software_an_actor_can_be.md
index 2732510c95..6810e37d10 100644
--- a/sources/academy/build-and-publish/actor-ideas/what_software_an_actor_can_be.md
+++ b/sources/academy/build-and-publish/actor-ideas/what_software_an_actor_can_be.md
@@ -150,7 +150,6 @@ Any repetitive job matching the following criteria might be suitable for turning
If you look closely, you'll start seeing opportunities for new Actors everywhere. Be creative!
-
## Use the Actor ideas page
The [Actor ideas](https://apify.com/ideas) page is where you can find inspiration for new Actors sourced from the Apify community.
@@ -166,20 +165,16 @@ Build and publish new tools on Apify and have multiple chances to win big prizes
:::
1. _Visit_ [apify.com/ideas](https://apify.com/ideas) to find ideas that interest you. Look for ideas that align with your skills.
+2. _Select an Actor idea_: Review the details and requirements. Check the status—if it's marked **Open to develop**, you can start building.
+3. _Build your Actor_: Develop your Actor based on the idea. You don't need to notify Apify during development.
+4. _Prepare for launch_: Ensure your Actor meets quality standards and has a comprehensive README with installation instructions, usage details, and examples.
+5. _Publish your Actor_: Deploy your Actor on Apify Store and make it live.
+6. _Monitor and optimize_: Track your Actor's performance and user feedback. Make improvements to keep your Actor current.
-1. _Select an Actor idea_: Review the details and requirements. Check the status—if it's marked **Open to develop**, you can start building.
-
-1. _Build your Actor_: Develop your Actor based on the idea. You don't need to notify Apify during development.
-
-1. _Prepare for launch_: Ensure your Actor meets quality standards and has a comprehensive README with installation instructions, usage details, and examples.
-
-1. _Publish your Actor_: Deploy your Actor on Apify Store and make it live.
-
-
-
-1. _Monitor and optimize_: Track your Actor's performance and user feedback. Make improvements to keep your Actor current.
+
-
+
#### Can the Actor's meta description and description be the same?
Yes, they can, as long as they have the same (shorter) length (under 150 characters). But they can also be different - there's no harm in that.
diff --git a/sources/academy/build-and-publish/apify-store-basics/how_actor_monetization_works.md b/sources/academy/build-and-publish/apify-store-basics/how_actor_monetization_works.md
index a7befdf3e7..907ede7c1d 100644
--- a/sources/academy/build-and-publish/apify-store-basics/how_actor_monetization_works.md
+++ b/sources/academy/build-and-publish/apify-store-basics/how_actor_monetization_works.md
@@ -28,26 +28,26 @@ Monetizing your Actor on the Apify platform involves several key steps:

- _How it works_: you charge users based on specific events triggered programmatically by your Actor's code. You earn 80% of the revenue minus platform usage costs.
-- - _Profit calculation_: `profit = (0.8 * revenue) - platform usage costs`
+- _Profit calculation_: `profit = (0.8 * revenue) - platform usage costs`
- _Event cost example_: you set the following events for your Actor:
- - `Actor start per 1 GB of memory` at $0.005
- - `Pages scraped` at $0.002
- - `Page opened with residential proxy` at $0.002 - this is on top of `Pages scraped`
- - `Page opened with a browser` at $0.002 - this is on top of `Pages scraped`
+ - `Actor start per 1 GB of memory` at $0.005
+ - `Pages scraped` at $0.002
+ - `Page opened with residential proxy` at $0.002 - this is on top of `Pages scraped`
+ - `Page opened with a browser` at $0.002 - this is on top of `Pages scraped`
- _Example_:
- - User A:
- - Started the Actor with 10GB of memory = $0.05
- - Scraped 1,000 pages = $2.00
- - 500 of those were scraped using residential proxy = $1.00
- - 300 of those were scraped using browser = $0.60
- - This comes up to $3.65 of total revenue
- - User B:
- - Started the Actor with 5GB of memory = $0.025
- - Scraped 500 pages = $1.00
- - 200 of those were scraped using residential proxy = $0.40
- - 100 of those were scraped using browser = $0.20
- - This comes up to $1.625 of total revenue
- - That means if platform usage costs are $0.365 for user A and $0.162 for user B your profit is $4.748
+ - User A:
+ - Started the Actor with 10GB of memory = $0.05
+ - Scraped 1,000 pages = $2.00
+ - 500 of those were scraped using residential proxy = $1.00
+ - 300 of those were scraped using browser = $0.60
+ - This comes up to $3.65 of total revenue
+ - User B:
+ - Started the Actor with 5GB of memory = $0.025
+ - Scraped 500 pages = $1.00
+ - 200 of those were scraped using residential proxy = $0.40
+ - 100 of those were scraped using browser = $0.20
+ - This comes up to $1.625 of total revenue
+ - That means if platform usage costs are $0.365 for user A and $0.162 for user B your profit is $4.748
:::info Pay-per-event details
@@ -62,11 +62,11 @@ If you want more details about PPE pricing, refer to our [PPE documentation](/pl
- _How it works_: you charge users based on the number of results your Actor generates. You earn 80% of the revenue minus platform usage costs.
- _Profit calculation_: `profit = (0.8 * revenue) - platform usage costs`
- _Cost breakdown_:
- - Compute unit: $0.3 per CU
- - Residential proxies: $13 per GB
- - SERPs proxy: $3 per 1,000 SERPs
- - Data transfer (external): $0.20 per GB
- - Dataset storage: $1 per 1,000 GB-hours
+ - Compute unit: $0.3 per CU
+ - Residential proxies: $13 per GB
+ - SERPs proxy: $3 per 1,000 SERPs
+ - Data transfer (external): $0.20 per GB
+ - Dataset storage: $1 per 1,000 GB-hours
- _Example_: you set a price of $1 per 1,000 results. Two users generate 50,000 and 20,000 results, paying $50 and $20, respectively. If the platform usage costs are $5 and $2, your profit is $49.
:::info Pay-per-result details
@@ -81,9 +81,9 @@ If you want more details about PPR pricing, refer to our [PPR documentation](/pl
- _How it works_: you offer a free trial period and set a monthly fee. Users on Apify paid plans can continue using the Actor after the trial. You earn 80% of the monthly rental fees.
- _Example_: you set a 7-day free trial and $30/month rental. If 3 users start using your Actor:
- - 1st user on a paid plan pays $30 after the trial (you earn $24).
- - 2nd user starts their trial but pays next month.
- - 3rd user on a free plan finishes the trial without upgrading to a paid plan and can’t use the Actor further.
+ - 1st user on a paid plan pays $30 after the trial (you earn $24).
+ - 2nd user starts their trial but pays next month.
+ - 3rd user on a free plan finishes the trial without upgrading to a paid plan and can’t use the Actor further.
:::info Rental pricing details
@@ -160,7 +160,7 @@ Example of useful pricing estimates from the **Analytics** tab:
:::tip Use emails!
-📫 Don't forget to set an email sequence to warn and remind your users about pricing changes. Learn more about emailing your users here: [Emails to Actor users]
+📫 Don't forget to set an email sequence to warn and remind your users about pricing changes. Learn more about emailing your users here: [Emails to Actor users]
:::
@@ -172,4 +172,3 @@ Example of useful pricing estimates from the **Analytics** tab:
- Watch our webinar on how to [build, publish and monetize Actors](https://www.youtube.com/watch?v=4nxStxC1BJM)
- Read a blog post from our CEO on the [reasoning behind monetizing Actors](https://blog.apify.com/make-regular-passive-income-developing-web-automation-actors-b0392278d085/)
- Learn about the [Creator plan](https://apify.com/pricing/creator-plan), which allows you to create and freely test your own Actors for $1
-
diff --git a/sources/academy/build-and-publish/apify-store-basics/how_to_create_actor_readme.md b/sources/academy/build-and-publish/apify-store-basics/how_to_create_actor_readme.md
index 6b0d9d2e12..3af560cbd9 100644
--- a/sources/academy/build-and-publish/apify-store-basics/how_to_create_actor_readme.md
+++ b/sources/academy/build-and-publish/apify-store-basics/how_to_create_actor_readme.md
@@ -173,7 +173,6 @@ If you want to add snippets of code anywhere in your README, you can use [Carbo
If you need quick Markdown guidance, check out [https://www.markdownguide.org/cheat-sheet/](https://www.markdownguide.org/cheat-sheet/)
-
## README and SEO
Your README is your landing page.
@@ -231,8 +230,8 @@ Learn about [How to create a great input schema](/academy/actor-marketing-playbo
- Business use cases
- Link to a success story, a business use case, or a blog post.
3. How to scrape (target site)
- - Link to "How to…" blogs, if one exists (or suggest one if it doesn't)
- - Add a video tutorial or gif from an ideal Actor run.
+ - Link to "How to…" blogs, if one exists (or suggest one if it doesn't)
+ - Add a video tutorial or gif from an ideal Actor run.
:::tip Embedding YouTube videos
@@ -246,13 +245,13 @@ For better user experience, Apify Console automatically renders every YouTube UR
- This can be used as a boilerplate text for the legal section, but you should use your own judgment and also customize it with the site name.
> Our scrapers are ethical and do not extract any private user data, such as email addresses, gender, or location. They only extract what the user has chosen to share publicly. We therefore believe that our scrapers, when used for ethical purposes by Apify users, are safe. However, you should be aware that your results could contain personal data. Personal data is protected by the GDPR in the European Union and by other regulations around the world. You should not scrape personal data unless you have a legitimate reason to do so. If you're unsure whether your reason is legitimate, consult your lawyers. You can also read our blog post on the legality of web scraping
- >
+
2. Input
- Each Actor detail page has an input tab, so you just need to refer to that. If you like, you can add a screenshot showing the user what the input fields will look like.
- This is an example of how to refer to the input tab:
> Twitter Scraper has the following input options. Click on the input tab for more information.
- >
+
3. Output
- Mention "You can download the dataset extracted by (Actor name) in various formats such as JSON, HTML, CSV, or Excel.”
- Add a simplified JSON dataset example, like here https://apify.com/compass/crawler-google-places#output-example
diff --git a/sources/academy/build-and-publish/apify-store-basics/importance_of_actor_url.md b/sources/academy/build-and-publish/apify-store-basics/importance_of_actor_url.md
index 8a7fdf692d..37a1ada246 100644
--- a/sources/academy/build-and-publish/apify-store-basics/importance_of_actor_url.md
+++ b/sources/academy/build-and-publish/apify-store-basics/importance_of_actor_url.md
@@ -84,9 +84,10 @@ In Console. Open the **Actor's page**, then click on **…** in the top right co

-
## FAQ
+
+
#### Can Actor URL be different from Actor name?
Yes. While they can be the same, they don’t have to be. For the best user experience, keeping them identical is recommended, but you can experiment with the Actor's name. Just avoid changing the Actor URL.
@@ -106,4 +107,3 @@ Yes, you can. But it will most likely lower your chances of being noticed by Goo
#### Does changing my Apify account name affect the Actor URL?
Yes. If you're changing from _justanotherdev/pentagon-scraper_ to _dev/pentagon-scraper_, it counts as a new page. Essentially, the consequences are the same as after changing the technical name of the Actor.
-
diff --git a/sources/academy/build-and-publish/apify-store-basics/name_your_actor.md b/sources/academy/build-and-publish/apify-store-basics/name_your_actor.md
index 05013561a4..8707634d04 100644
--- a/sources/academy/build-and-publish/apify-store-basics/name_your_actor.md
+++ b/sources/academy/build-and-publish/apify-store-basics/name_your_actor.md
@@ -19,10 +19,10 @@ Ideally, you should choose a name that clearly shows what your Actor does and in
Your Actor's name consists of four parts: actual name, SEO name, URL, and GitHub repository name.
- Actor name (name shown in Apify Store), e.g. _Booking Scraper_.
- - Actor SEO name (name shown on Google Search, optional), e.g. _Booking.com Hotel Data Scraper_.
- - If the SEO name is not set, the Actor name will be the default name shown on Google.
+ - Actor SEO name (name shown on Google Search, optional), e.g. _Booking.com Hotel Data Scraper_.
+ - If the SEO name is not set, the Actor name will be the default name shown on Google.
- Actor URL (technical name), e.g. _booking-scraper_.
- - More on it on [Importance of Actor URL](/academy/actor-marketing-playbook/actor-basics/importance-of-actor-url) page.
+ - More on it on [Importance of Actor URL](/academy/actor-marketing-playbook/actor-basics/importance-of-actor-url) page.
- GitHub repository name (best to keep it similar to the other ones, for convenience), e.g. _actor-booking-scraper_.
## Actor name
diff --git a/sources/academy/build-and-publish/how-to-build/how_to_create_a_great_input_schema.md b/sources/academy/build-and-publish/how-to-build/how_to_create_a_great_input_schema.md
index 892c30b49a..10e482d542 100644
--- a/sources/academy/build-and-publish/how-to-build/how_to_create_a_great_input_schema.md
+++ b/sources/academy/build-and-publish/how-to-build/how_to_create_a_great_input_schema.md
@@ -66,57 +66,56 @@ You can see the full list of elements and their technical characteristics in [Do
Unfortunately, when it comes to UX, there's only so much you can achieve armed with HTML alone. Here are the best elements to focus on, along with some best practices for using them effectively:
- **`description` at the top**
- - As the first thing users see, the description needs to provide crucial information and a sense of reassurance if things go wrong. Key points to mention: the easiest way to try the Actor, links to a guide, and any disclaimers or other similar Actors to try.
+ - As the first thing users see, the description needs to provide crucial information and a sense of reassurance if things go wrong. Key points to mention: the easiest way to try the Actor, links to a guide, and any disclaimers or other similar Actors to try.
- 
+ 
- - Descriptions can include multiple paragraphs. If you're adding a link, it’s best to use the `target_blank` property so your user doesn’t lose the original Actor page when clicking.
+ - Descriptions can include multiple paragraphs. If you're adding a link, it’s best to use the `target_blank` property so your user doesn’t lose the original Actor page when clicking.
- **`title` of the field (regular bold text)**
- - This is the default way to name a field.
- - Keep it brief. The user’s flow should be 1. title → 2. tooltip → 3. link in the tooltip. Ideally, the title alone should provide enough clarity. However, avoid overloading the title with too much information. Instead, make the title as concise as possible, expand details in the tooltip, and include a link in the tooltip for full instructions.
+ - This is the default way to name a field.
+ - Keep it brief. The user’s flow should be 1. title → 2. tooltip → 3. link in the tooltip. Ideally, the title alone should provide enough clarity. However, avoid overloading the title with too much information. Instead, make the title as concise as possible, expand details in the tooltip, and include a link in the tooltip for full instructions.
- 
+ 
- **`prefill`, the default input**
- - this is your chance to show rather than tell
- - Keep the **prefilled number** low. Set it to 0 if it's irrelevant for a default run.
- - Make the **prefilled text** example simple and easy to remember.
- - If your Actor accepts various URL formats, add a few different **prefilled URLs** to show that possibility.
- - Use the **prefilled date** format that the user is expected to follow. This way, they can learn the correct format without needing to check the tooltip.
- - There’s also a type of field that looks like a prefill but isn’t — usually a `default` field. It’s not counted as actual input but serves as a mock input to show users what to type or paste. It is gray and disappears after clicking on it. Use this to your advantage.
+ - this is your chance to show rather than tell
+ - Keep the **prefilled number** low. Set it to 0 if it's irrelevant for a default run.
+ - Make the **prefilled text** example simple and easy to remember.
+ - If your Actor accepts various URL formats, add a few different **prefilled URLs** to show that possibility.
+ - Use the **prefilled date** format that the user is expected to follow. This way, they can learn the correct format without needing to check the tooltip.
+ - There’s also a type of field that looks like a prefill but isn’t — usually a `default` field. It’s not counted as actual input but serves as a mock input to show users what to type or paste. It is gray and disappears after clicking on it. Use this to your advantage.
- **toggle**
- - The toggle is a boolean field. A boolean field represents a yes/no choice.
- - How would you word this toggle: **Skip closed places** or **Scrape open places only**? And should the toggle be enabled or disabled by default?
+ - The toggle is a boolean field. A boolean field represents a yes/no choice.
+ - How would you word this toggle: **Skip closed places** or **Scrape open places only**? And should the toggle be enabled or disabled by default?
- 
-
- - You have to consider this when you're choosing how to word the toggle button and which choice to set up as the default. If you're making this more complex than it's needed (e.g. by using negation as the ‘yes’ choice), you're increasing your user's cognitive load. You also might get them to receive way less, or way more, data than they need from a default run.
- - In our example, we assume the default user wants to scrape all places but still have the option to filter out closed ones. However, they have to make that choice consciously, so we keep the toggle disabled by default. If the toggle were enabled by default, users might not notice it, leading them to think the tool isn't working properly when it returns fewer results than expected.
+ 
+ - You have to consider this when you're choosing how to word the toggle button and which choice to set up as the default. If you're making this more complex than it's needed (e.g. by using negation as the ‘yes’ choice), you're increasing your user's cognitive load. You also might get them to receive way less, or way more, data than they need from a default run.
+ - In our example, we assume the default user wants to scrape all places but still have the option to filter out closed ones. However, they have to make that choice consciously, so we keep the toggle disabled by default. If the toggle were enabled by default, users might not notice it, leading them to think the tool isn't working properly when it returns fewer results than expected.
- **sections or `sectionCaption` (BIG bold text) and `sectionDescription`**
- - A section looks like a wrapped toggle list.
+ - A section looks like a wrapped toggle list.
- 
+ 
- - It is useful to section off non-default ways of input or extra features. If your tool is complex, don't leave all fields in the first section. Just group them by topic and section them off (see the screenshot above ⬆️)
- - You can add a description to every section. Use `sectionDescription` only if you need to provide extra information about the section (see the screenshot below ⬇️.
- - sometimes `sectionDescription` is used as a space for disclaimers so the user is informed of the risks from the outset instead of having to click on the tooltip.
+ - It is useful to section off non-default ways of input or extra features. If your tool is complex, don't leave all fields in the first section. Just group them by topic and section them off (see the screenshot above ⬆️)
+ - You can add a description to every section. Use `sectionDescription` only if you need to provide extra information about the section (see the screenshot below ⬇️.
+ - sometimes `sectionDescription` is used as a space for disclaimers so the user is informed of the risks from the outset instead of having to click on the tooltip.
- 
+ 
- tooltips or `description` to the title
- - To see the tooltip's text, the user needs to click on the `?` icon.
- - This is your space to explain the title and what's going to happen in that field: any terminology, referrals to other fields of the tool, examples that don't fit the prefill, or caveats can be detailed here. Using HTML, you can add links, line breaks, code, and other regular formatting here. Use this space to add links to relevant guides, video tutorials, screenshots, issues, or readme parts if needed.
- - Wording in titles vs. tooltips. Titles are usually nouns. They have a neutral tone and simply inform on what content this field is accepting (**Usernames**).
- - Tooltips to those titles are usually verbs in the imperative that tell the user what to do (_Add, enter, use_).
- - This division is not set in stone, but the reason why the tooltip is an imperative verb is because, if the user is clicking on the tooltip, we assume they are looking for clarifications or instructions on what to do.
+ - To see the tooltip's text, the user needs to click on the `?` icon.
+ - This is your space to explain the title and what's going to happen in that field: any terminology, referrals to other fields of the tool, examples that don't fit the prefill, or caveats can be detailed here. Using HTML, you can add links, line breaks, code, and other regular formatting here. Use this space to add links to relevant guides, video tutorials, screenshots, issues, or readme parts if needed.
+ - Wording in titles vs. tooltips. Titles are usually nouns. They have a neutral tone and simply inform on what content this field is accepting (**Usernames**).
+ - Tooltips to those titles are usually verbs in the imperative that tell the user what to do (_Add, enter, use_).
+ - This division is not set in stone, but the reason why the tooltip is an imperative verb is because, if the user is clicking on the tooltip, we assume they are looking for clarifications or instructions on what to do.
- 
+ 
- emojis (visual component)
- - Use them to attract attention or as visual shortcuts. Use emojis consistently to invoke a user's iconic memory. The visual language should match across the whole input schema (and README) so the user can understand what section or field is referred to without reading the whole title.
- - Don't overload the schema with emojis. They attract attention, so you need to use them sparingly.
+ - Use them to attract attention or as visual shortcuts. Use emojis consistently to invoke a user's iconic memory. The visual language should match across the whole input schema (and README) so the user can understand what section or field is referred to without reading the whole title.
+ - Don't overload the schema with emojis. They attract attention, so you need to use them sparingly.
:::tip
@@ -165,7 +164,7 @@ The version above was the improved input schema. Here's what this tool's input s
- _User feedback_. If they're asking obvious things, complaining, or consistently making silly mistakes with input, take notes. Feedback from users can help you understand their experience and identify areas for improvement.
- _High churn rates_. If your users are trying your tool but quickly abandon it, this is a sign they are having difficulties with your schema.
-- _Input Schema Viewer_. Write your base schema in any code editor, then copy the file and put it into [**Input Schema Viewer](https://console.apify.com/actors/UHTe5Bcb4OUEkeahZ/source).** This tool should help you visualize your Input Schema before you add it to your Actor and build it. Seeing how your edits look in Apify Console right away will make the process of editing the fields in code easier.
+- _Input Schema Viewer_. Write your base schema in any code editor, then copy the file and put it into [**Input Schema Viewer**](https://console.apify.com/actors/UHTe5Bcb4OUEkeahZ/source). This tool should help you visualize your Input Schema before you add it to your Actor and build it. Seeing how your edits look in Apify Console right away will make the process of editing the fields in code easier.
## Resources
diff --git a/sources/academy/build-and-publish/how-to-build/index.md b/sources/academy/build-and-publish/how-to-build/index.md
index 5670747a3b..222d376fb2 100644
--- a/sources/academy/build-and-publish/how-to-build/index.md
+++ b/sources/academy/build-and-publish/how-to-build/index.md
@@ -21,14 +21,14 @@ At Apify, we try to make building web scraping and automation straightforward. Y
Since scraping and automation come in various forms, we decided to build not just one, but _six_ scrapers. This way, you can always pick the right tool for the job. Let's take a look at each particular tool and its advantages and disadvantages.
-| Scraper | Technology | Advantages | Disadvantages | Best for |
-| --- | --- | --- | --- | --- |
-| 🌐 Web Scraper | Headless Chrome Browser | Simple, fully JavaScript-rendered pages | Executes only client-side JavaScript | Websites with heavy client-side JavaScript |
-| 👐 Puppeteer Scraper | Headless Chrome Browser | Powerful Puppeteer functions, executes both server-side and client-side JavaScript | More complex | Advanced scraping with client/server-side JS |
-| 🎭 Playwright Scraper | Cross-browser support with Playwright library | Cross-browser support, executes both server-side and client-side JavaScript | More complex | Cross-browser scraping with advanced features |
-| 🍩 Cheerio Scraper | HTTP requests + Cheerio parser (JQuery-like for servers) | Simple, fast, cost-effective | Pages may not be fully rendered (lacks JavaScript rendering), executes only server-side JavaScript | High-speed, cost-effective scraping |
-| ⚠️ JSDOM Scraper | JSDOM library (Browser-like DOM API) | + Handles client-side JavaScript + Faster than full-browser solutions + Ideal for light scripting | Not for heavy dynamic JavaScript, executes server-side code only, depends on pre-installed NPM modules | Speedy scraping with light client-side JS |
-| 🍲 BeautifulSoup Scraper | Python-based, HTTP requests + BeautifulSoup parser | Python-based, supports recursive crawling and URL lists | No full-featured web browser, not suitable for dynamic JavaScript-rendered pages | Python users needing simple, recursive crawling |
+| Scraper | Technology | Advantages | Disadvantages | Best for |
+| ------------------------ | -------------------------------------------------------- | --------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------ | ----------------------------------------------- |
+| 🌐 Web Scraper | Headless Chrome Browser | Simple, fully JavaScript-rendered pages | Executes only client-side JavaScript | Websites with heavy client-side JavaScript |
+| 👐 Puppeteer Scraper | Headless Chrome Browser | Powerful Puppeteer functions, executes both server-side and client-side JavaScript | More complex | Advanced scraping with client/server-side JS |
+| 🎭 Playwright Scraper | Cross-browser support with Playwright library | Cross-browser support, executes both server-side and client-side JavaScript | More complex | Cross-browser scraping with advanced features |
+| 🍩 Cheerio Scraper | HTTP requests + Cheerio parser (JQuery-like for servers) | Simple, fast, cost-effective | Pages may not be fully rendered (lacks JavaScript rendering), executes only server-side JavaScript | High-speed, cost-effective scraping |
+| ⚠️ JSDOM Scraper | JSDOM library (Browser-like DOM API) | + Handles client-side JavaScript + Faster than full-browser solutions + Ideal for light scripting | Not for heavy dynamic JavaScript, executes server-side code only, depends on pre-installed NPM modules | Speedy scraping with light client-side JS |
+| 🍲 BeautifulSoup Scraper | Python-based, HTTP requests + BeautifulSoup parser | Python-based, supports recursive crawling and URL lists | No full-featured web browser, not suitable for dynamic JavaScript-rendered pages | Python users needing simple, recursive crawling |
### How do I choose the right universal web scraper to start with?
@@ -41,7 +41,6 @@ Since scraping and automation come in various forms, we decided to build not jus
- Use ⚠️ [JSDOM Scraper](https://apify.com/apify/jsdom-scraper) for lightweight, speedy scraping with minimal client-side JavaScript requirements.
- Use 🍲 [BeautifulSoup Scraper](https://apify.com/apify/beautifulsoup-scraper) for Python-based scraping, especially with recursive crawling and processing URL lists.
-
To make it easier, here's a short questionnaire that guides you on selecting the best scraper based on your specific use case:
@@ -76,7 +75,6 @@ This should help you navigate through the options and choose the right scraper b
-
📚 Resources:
- How to use [Web Scraper](https://www.youtube.com/watch?v=5kcaHAuGxmY) to scrape any website
@@ -87,11 +85,10 @@ This should help you navigate through the options and choose the right scraper b
Similar to our universal scrapers, our [code templates](https://apify.com/templates) also provide a quick start for developing web scrapers, automation scripts, and testing tools. Built on popular libraries like BeautifulSoup for Python or Playwright for JavaScript, they save time on setup, allowing you to focus on customization. Though they require more coding than universal scrapers, they're ideal for those who want a flexible foundation while still needing room to tailor their solutions.
-| Code template | Supported libraries | Purpose | Pros | Cons |
-| --- | --- | --- | --- | --- |
-| 🐍 Python | Requests, BeautifulSoup, Scrapy, Selenium, Playwright | Creating scrapers Automation Testing tools | - Simplifies setup - Supports major Python libraries | - Requires more manual coding (than universal scrapers)- May be restrictive for complex tasks |
-| ☕️ JavaScript | Playwright, Selenium, Cheerio, Cypress, LangChain | Creating scrapers Automation Testing tools | - Eases development with pre-set configurations - Flexibility with JavaScript and TypeScript | - Requires more manual coding (than universal scrapers)- May be restrictive for tasks needing full control |
-
+| Code template | Supported libraries | Purpose | Pros | Cons |
+| ------------- | ----------------------------------------------------- | ------------------------------------------ | -------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- |
+| 🐍 Python | Requests, BeautifulSoup, Scrapy, Selenium, Playwright | Creating scrapers Automation Testing tools | - Simplifies setup - Supports major Python libraries | - Requires more manual coding (than universal scrapers)- May be restrictive for complex tasks |
+| ☕️ JavaScript | Playwright, Selenium, Cheerio, Cypress, LangChain | Creating scrapers Automation Testing tools | - Eases development with pre-set configurations - Flexibility with JavaScript and TypeScript | - Requires more manual coding (than universal scrapers)- May be restrictive for tasks needing full control |
📚 Resources:
@@ -128,7 +125,6 @@ While these tools are distinct, they can be combined. For example, you can use C
- Webinar on how to use [Crawlee Python](https://www.youtube.com/watch?v=ip8Ii0eLfRY)
- Introduction to Apify's [Python SDK](https://www.youtube.com/watch?v=C8DmvJQS3jk)
-
## Code templates vs. universal scrapers vs. libraries
Basically, the choice here depends on how much flexibility you need and how much coding you're willing to do. More flexibility → more coding.
diff --git a/sources/academy/build-and-publish/how-to-build/running_a_web_server.md b/sources/academy/build-and-publish/how-to-build/running_a_web_server.md
index 8a4eaecc86..985f772eb9 100644
--- a/sources/academy/build-and-publish/how-to-build/running_a_web_server.md
+++ b/sources/academy/build-and-publish/how-to-build/running_a_web_server.md
@@ -62,11 +62,7 @@ Now we need to read the following environment variables:
- **APIFY_DEFAULT_KEY_VALUE_STORE_ID** is the ID of the default key-value store of this Actor where we can store screenshots.
```js
-const {
- APIFY_CONTAINER_PORT,
- APIFY_CONTAINER_URL,
- APIFY_DEFAULT_KEY_VALUE_STORE_ID,
-} = process.env;
+const { APIFY_CONTAINER_PORT, APIFY_CONTAINER_URL, APIFY_DEFAULT_KEY_VALUE_STORE_ID } = process.env;
```
Next, we'll create an array of the processed URLs where the **n**th URL has its screenshot stored under the key **n**.jpg in the key-value store.
@@ -133,7 +129,9 @@ app.post('/add-url', async (req, res) => {
await browser.close();
// ... save screenshot to key-value store and add URL to processedUrls.
- await Actor.setValue(`${processedUrls.length}.jpg`, screenshot, { contentType: 'image/jpeg' });
+ await Actor.setValue(`${processedUrls.length}.jpg`, screenshot, {
+ contentType: 'image/jpeg',
+ });
processedUrls.push(url);
res.redirect('/');
@@ -162,11 +160,7 @@ const app = express();
app.use(express.json());
app.use(express.urlencoded({ extended: true }));
-const {
- APIFY_CONTAINER_PORT,
- APIFY_CONTAINER_URL,
- APIFY_DEFAULT_KEY_VALUE_STORE_ID,
-} = process.env;
+const { APIFY_CONTAINER_PORT, APIFY_CONTAINER_URL, APIFY_DEFAULT_KEY_VALUE_STORE_ID } = process.env;
const processedUrls = [];
@@ -219,7 +213,9 @@ app.post('/add-url', async (req, res) => {
await browser.close();
// ... save screenshot to key-value store and add URL to processedUrls.
- await Actor.setValue(`${processedUrls.length}.jpg`, screenshot, { contentType: 'image/jpeg' });
+ await Actor.setValue(`${processedUrls.length}.jpg`, screenshot, {
+ contentType: 'image/jpeg',
+ });
processedUrls.push(url);
res.redirect('/');
diff --git a/sources/academy/build-and-publish/interacting-with-users/emails_to_actor_users.md b/sources/academy/build-and-publish/interacting-with-users/emails_to_actor_users.md
index 663628547a..ba6c3ad03b 100644
--- a/sources/academy/build-and-publish/interacting-with-users/emails_to_actor_users.md
+++ b/sources/academy/build-and-publish/interacting-with-users/emails_to_actor_users.md
@@ -38,15 +38,15 @@ Our general policy is to avoid spamming users with unnecessary emails. We contac
New filter, faster scraping, changes in input schema, in output schema, a new Integration, etc.
->✉️ 🏙️ Introducing Deep city search for Tripadvisor scrapers
+> ✉️ 🏙️ Introducing Deep city search for Tripadvisor scrapers
>
->Hi,
+> Hi,
>
->Tired of Tripadvisor's 3000 hotels-per-search limit? We've got your back. Say hello to our latest baked-in feature: Deep city search. Now, to get all results from a country-wide search you need to just set Max search results above 3000, and watch the magic happen.
+> Tired of Tripadvisor's 3000 hotels-per-search limit? We've got your back. Say hello to our latest baked-in feature: Deep city search. Now, to get all results from a country-wide search you need to just set Max search results above 3000, and watch the magic happen.
>
->A bit of context: while Tripadvisor never limited the search for restaurants or attractions, hotel search was a different case; it always capped at 3000. Our smart search is designed to overcome that limit by including every city within your chosen location. We scrape hotels from each one, ensuring no hidden gems slip through the cracks. This feature is available for [Tripadvisor Scraper](https://console.apify.com/actors/dbEyMBriog95Fv8CW/console) and [Tripadvisor Hotels Scraper](https://console.apify.com/actors/qx7G70MC4WBE273SM/console).
+> A bit of context: while Tripadvisor never limited the search for restaurants or attractions, hotel search was a different case; it always capped at 3000. Our smart search is designed to overcome that limit by including every city within your chosen location. We scrape hotels from each one, ensuring no hidden gems slip through the cracks. This feature is available for [Tripadvisor Scraper](https://console.apify.com/actors/dbEyMBriog95Fv8CW/console) and [Tripadvisor Hotels Scraper](https://console.apify.com/actors/qx7G70MC4WBE273SM/console).
>
->Get ready for an unbeatable hotel-hunting experience. Give it a spin, and let us know what you think!
+> Get ready for an unbeatable hotel-hunting experience. Give it a spin, and let us know what you think!
Introduce and explain the features, add a screenshot of a feature if it will show in the input schema, and ask for feedback.
@@ -54,15 +54,15 @@ Introduce and explain the features, add a screenshot of a feature if it will sho
A common situation in web scraping that's out of your control.
->✉️ 📣 Output changes for Facebook Ads Scraper
+> ✉️ 📣 Output changes for Facebook Ads Scraper
>
->Hi,
+> Hi,
>
->We've got some news regarding your favorite Actor – [Facebook Ads Scraper](https://console.apify.com/actors/JJghSZmShuco4j9gJ/console). Recently, Facebook Ads have changed their data format. To keep our Actor running smoothly, we'll be adapting to these changes by slightly tweaking the Actor Output. Don't worry; it's a breeze! Some of the output data might just appear under new titles.
+> We've got some news regarding your favorite Actor – [Facebook Ads Scraper](https://console.apify.com/actors/JJghSZmShuco4j9gJ/console). Recently, Facebook Ads have changed their data format. To keep our Actor running smoothly, we'll be adapting to these changes by slightly tweaking the Actor Output. Don't worry; it's a breeze! Some of the output data might just appear under new titles.
>
->This change will take place on October 10; please** **make sure to remap your integrations accordingly.
+> This change will take place on October 10; please make sure to remap your integrations accordingly.
>
->Need a hand or have questions? Our support team is just one friendly message away.
+> Need a hand or have questions? Our support team is just one friendly message away.
Inform users about the reason for changes and how the changes impact them and the Actor + give them a date when the change takes effect.
@@ -70,32 +70,32 @@ Inform users about the reason for changes and how the changes impact them and th
Email 1 (before the change, warning about deprecation).
->✉️ 🛎 Changes to Booking Scraper
+> ✉️ 🛎 Changes to Booking Scraper
>
->Hi,
+> Hi,
>
->We’ve got news regarding the Booking scraper you have been using. This change will happen in two steps:
+> We’ve got news regarding the Booking scraper you have been using. This change will happen in two steps:
>
->1. On September 22, we will deprecate it, i.e., new users will not be able to find it in Store. You will still be able to use it though.
->2. At the end of October, we will unpublish this Actor, and from that point on, you will not be able to use it anymore.
+> 1. On September 22, we will deprecate it, i.e., new users will not be able to find it in Store. You will still be able to use it though.
+> 2. At the end of October, we will unpublish this Actor, and from that point on, you will not be able to use it anymore.
>
->Please use this time to change your integrations to our new [Booking Scraper](https://apify.com/voyager/booking-scraper).
+> Please use this time to change your integrations to our new [Booking Scraper](https://apify.com/voyager/booking-scraper).
>
->That’s it! If you have any questions or need more information, don’t hesitate to reach out.
+> That’s it! If you have any questions or need more information, don’t hesitate to reach out.
Warn the users about the deprecation and future unpublishing + add extra information about related Actors if applicable + give them steps and the date when the change takes effect.
Email 2 (after the change, warning about unpublishing)
->✉️ **📢 Deprecated Booking Scraper will stop working as announced 📢**
+> ✉️ **📢 Deprecated Booking Scraper will stop working as announced 📢**
>
->Hi,
+> Hi,
>
->Just a heads-up: today, the deprecated [Booking Scraper](https://console.apify.com/actors/5T5NTHWpvetjeRo3i/console) you have been using will be completely unpublished as announced, and you will not be able to use it anymore.
+> Just a heads-up: today, the deprecated [Booking Scraper](https://console.apify.com/actors/5T5NTHWpvetjeRo3i/console) you have been using will be completely unpublished as announced, and you will not be able to use it anymore.
>
->If you want to continue to scrape Booking.com, make sure to switch to the [latest Actor version](https://apify.com/voyager/booking-scraper).
+> If you want to continue to scrape Booking.com, make sure to switch to the [latest Actor version](https://apify.com/voyager/booking-scraper).
>
->For any assistance or questions, don't hesitate to reach out to our support team.
+> For any assistance or questions, don't hesitate to reach out to our support team.
Remind users to switch to the Actor with a new model.
@@ -103,15 +103,15 @@ Remind users to switch to the Actor with a new model.
Actor downtime, performance issues, Actor directly influenced by platform hiccups.
->✉️ **🛠️ Update on Google Maps Scraper: fixed and ready to go**
+> ✉️ **🛠️ Update on Google Maps Scraper: fixed and ready to go**
>
->Hi,
+> Hi,
>
->We've got a quick update on the Google Maps Scraper for you. If you've been running the Actor this week, you might have noticed some hiccups — scraping was failing for certain places, causing retries and overall slowness.
+> We've got a quick update on the Google Maps Scraper for you. If you've been running the Actor this week, you might have noticed some hiccups — scraping was failing for certain places, causing retries and overall slowness.
>
->We apologize for any inconvenience this may have caused you. The **good news is those performance issues are now resolved**. Feel free to resurrect any affected runs using the "latest" build, should work like a charm now.
+> We apologize for any inconvenience this may have caused you. The **good news is those performance issues are now resolved**. Feel free to resurrect any affected runs using the "latest" build, should work like a charm now.
>
->Need a hand or have questions? Feel free to reply to this email.
+> Need a hand or have questions? Feel free to reply to this email.
Apologize to users and or let them know you're working on it/everything is fixed now. This approach helps maintain trust and reassures users that you're addressing the situation.
diff --git a/sources/academy/build-and-publish/interacting-with-users/issues_tab.md b/sources/academy/build-and-publish/interacting-with-users/issues_tab.md
index 330809182d..0fda16f823 100644
--- a/sources/academy/build-and-publish/interacting-with-users/issues_tab.md
+++ b/sources/academy/build-and-publish/interacting-with-users/issues_tab.md
@@ -93,5 +93,4 @@ When we made the tab public, we took inspiration from StackOverflow’s SEO stra
Politeness goes a long way! Make sure your responses are respectful and straight to the point. It helps to keep things professional, even if the issue seems minor.
-
https://rewind.com/blog/best-practices-for-using-github-issues/
diff --git a/sources/academy/build-and-publish/interacting-with-users/your_store_bio.md b/sources/academy/build-and-publish/interacting-with-users/your_store_bio.md
index 2b51350c67..3063e34fab 100644
--- a/sources/academy/build-and-publish/interacting-with-users/your_store_bio.md
+++ b/sources/academy/build-and-publish/interacting-with-users/your_store_bio.md
@@ -15,7 +15,7 @@ This space is all about helping you shine and promote your tools and skills. Her
- Share your contact email, website, GitHub, X (Twitter), LinkedIn, or Discord handles.
- Summarize what you’ve been doing in Apify Store, your main skills, big achievements, and any relevant experience.
- Offer more ways for people to connect with you, such as links for booking a meeting, discounts, a subscription option for your email newsletter, or your YouTube channel or blog.
- - You can even add a Linktree to keep things neat.
+ - You can even add a Linktree to keep things neat.
- Highlight your other tools on different platforms.
- Get creative by adding banners and GIFs to give your profile some personality.
diff --git a/sources/academy/build-and-publish/promoting-your-actor/parasite_seo.md b/sources/academy/build-and-publish/promoting-your-actor/parasite_seo.md
index 062e981596..cd703a093c 100644
--- a/sources/academy/build-and-publish/promoting-your-actor/parasite_seo.md
+++ b/sources/academy/build-and-publish/promoting-your-actor/parasite_seo.md
@@ -13,7 +13,6 @@ slug: /actor-marketing-playbook/promote-your-actor/parasite-seo
Here’s a full definition, from Authority Hackers:
> Parasite SEO involves publishing a quality piece of content on an established, high-authority external site to rank on search engines. This gives you the benefit of the host’s high traffic, boosting your chances for leads and successful conversions. These high DR websites have a lot of authority and trust in the eyes of Google
->
As you can see, you’re leveraging the existing authority of a third-party site where you can publish content promoting your Actors, and the content should rank better and faster as you publish it on an established site.
diff --git a/sources/academy/build-and-publish/why_publish.md b/sources/academy/build-and-publish/why_publish.md
index 7774cee15f..20732d052a 100644
--- a/sources/academy/build-and-publish/why_publish.md
+++ b/sources/academy/build-and-publish/why_publish.md
@@ -28,7 +28,7 @@ Apify Store offers flexible pricing models that let you match your Actor's value
- Pay-per-event (PPE): Charge for any custom events your Actor triggers (maximum flexibility, AI/MCP compatible, priority store placement)
- Pay-per-result (PPR): Set pricing based on dataset items generated
-(predictable costs for users, unlimited revenue potential)
+ (predictable costs for users, unlimited revenue potential)
- Rental: Charge a flat monthly fee for continuous access (users cover their own platform usage costs)
All models give you 80% of revenue, with platform usage costs deducted for PPR and PPE models.
@@ -70,7 +70,7 @@ Ready to publish? The process involves four main stages:
1. Development: Build your Actor using [Apify SDKs](https://docs.apify.com/sdk), [Crawlee](https://crawlee.dev/), or [Actor templates](https://apify.com/templates)
1. Publication: Set up display information, description, README, and
-monetization
+ monetization
1. Testing: Ensure your Actor works reliably with automated or manual tests
1. Promotion: Optimize for SEO, share on social media, and create tutorials
diff --git a/sources/academy/glossary/concepts/html_elements.md b/sources/academy/glossary/concepts/html_elements.md
index d0c66e754a..7d0a02306e 100644
--- a/sources/academy/glossary/concepts/html_elements.md
+++ b/sources/academy/glossary/concepts/html_elements.md
@@ -14,7 +14,7 @@ An HTML element is a building block of an HTML document. It is used to represent
You can also add **attributes** to an element to provide additional information or to control how the element behaves. For example, the `src` attribute is used to specify the source of an image, like this:
```html
-
+
```
In JavaScript, you can use the **DOM** (Document Object Model) to interact with elements on a web page. For example, you can use the [`querySelector()` method](./querying_css_selectors.md) to select an element by its [CSS selector](./css_selectors.md), like this:
diff --git a/sources/academy/platform/expert_scraping_with_apify/saving_useful_stats.md b/sources/academy/platform/expert_scraping_with_apify/saving_useful_stats.md
index 6bc13433f1..1355cf9087 100644
--- a/sources/academy/platform/expert_scraping_with_apify/saving_useful_stats.md
+++ b/sources/academy/platform/expert_scraping_with_apify/saving_useful_stats.md
@@ -45,11 +45,9 @@ Also, an object including these values should be persisted during the run in th
```json
{
- "errors": { // all of the errors for every request path
- "some-site.com/products/123": [
- "error1",
- "error2"
- ]
+ "errors": {
+ // all of the errors for every request path
+ "some-site.com/products/123": ["error1", "error2"]
},
"totalSaved": 43 // total number of saved items throughout the entire run
}
diff --git a/sources/academy/platform/expert_scraping_with_apify/solutions/handling_migrations.md b/sources/academy/platform/expert_scraping_with_apify/solutions/handling_migrations.md
index 24399f8df6..11533ec137 100644
--- a/sources/academy/platform/expert_scraping_with_apify/solutions/handling_migrations.md
+++ b/sources/academy/platform/expert_scraping_with_apify/solutions/handling_migrations.md
@@ -71,18 +71,20 @@ router.addHandler(labels.START, async ({ $, crawler, request }) => {
// and initialize its collected offers count to 0
tracker.incrementASIN(element.attr('data-asin'));
- await crawler.addRequest([{
- url,
- label: labels.PRODUCT,
- userData: {
- data: {
- title: titleElement.first().text().trim(),
- asin: element.attr('data-asin'),
- itemUrl: url,
- keyword,
+ await crawler.addRequest([
+ {
+ url,
+ label: labels.PRODUCT,
+ userData: {
+ data: {
+ title: titleElement.first().text().trim(),
+ asin: element.attr('data-asin'),
+ itemUrl: url,
+ keyword,
+ },
},
},
- }]);
+ ]);
}
});
@@ -91,16 +93,18 @@ router.addHandler(labels.PRODUCT, async ({ $, crawler, request }) => {
const element = $('div#productDescription');
- await crawler.addRequests([{
- url: OFFERS_URL(data.asin),
- label: labels.OFFERS,
- userData: {
- data: {
- ...data,
- description: element.text().trim(),
+ await crawler.addRequests([
+ {
+ url: OFFERS_URL(data.asin),
+ label: labels.OFFERS,
+ userData: {
+ data: {
+ ...data,
+ description: element.text().trim(),
+ },
},
},
- }]);
+ ]);
});
router.addHandler(labels.OFFERS, async ({ $, request }) => {
diff --git a/sources/academy/platform/expert_scraping_with_apify/solutions/rotating_proxies.md b/sources/academy/platform/expert_scraping_with_apify/solutions/rotating_proxies.md
index 88755208eb..f8e3f36263 100644
--- a/sources/academy/platform/expert_scraping_with_apify/solutions/rotating_proxies.md
+++ b/sources/academy/platform/expert_scraping_with_apify/solutions/rotating_proxies.md
@@ -40,9 +40,7 @@ const crawler = new CheerioCrawler({
// We can add options for each
// session created by the session
// pool here
- sessionOptions: {
-
- },
+ sessionOptions: {},
},
maxConcurrency: 50,
// ...
diff --git a/sources/academy/platform/expert_scraping_with_apify/solutions/using_api_and_client.md b/sources/academy/platform/expert_scraping_with_apify/solutions/using_api_and_client.md
index e2cf1cf0d3..882ef89666 100644
--- a/sources/academy/platform/expert_scraping_with_apify/solutions/using_api_and_client.md
+++ b/sources/academy/platform/expert_scraping_with_apify/solutions/using_api_and_client.md
@@ -150,39 +150,39 @@ And before we push to the platform, let's not forget to write an input schema in
```json
{
- "title": "Actor Caller",
- "type": "object",
- "schemaVersion": 1,
- "properties": {
- "memory": {
- "title": "Memory",
- "type": "integer",
- "description": "Select memory in megabytes.",
- "default": 4096,
- "maximum": 32768,
- "unit": "MB"
+ "title": "Actor Caller",
+ "type": "object",
+ "schemaVersion": 1,
+ "properties": {
+ "memory": {
+ "title": "Memory",
+ "type": "integer",
+ "description": "Select memory in megabytes.",
+ "default": 4096,
+ "maximum": 32768,
+ "unit": "MB"
+ },
+ "useClient": {
+ "title": "Use client?",
+ "type": "boolean",
+ "description": "Specifies whether the Apify JS client, or the pure Apify API should be used.",
+ "default": true
+ },
+ "fields": {
+ "title": "Fields",
+ "type": "array",
+ "description": "Enter the dataset fields to export to CSV",
+ "prefill": ["title", "url", "price"],
+ "editor": "stringList"
+ },
+ "maxItems": {
+ "title": "Max items",
+ "type": "integer",
+ "description": "Fill the maximum number of items to export.",
+ "default": 10
+ }
},
- "useClient": {
- "title": "Use client?",
- "type": "boolean",
- "description": "Specifies whether the Apify JS client, or the pure Apify API should be used.",
- "default": true
- },
- "fields": {
- "title": "Fields",
- "type": "array",
- "description": "Enter the dataset fields to export to CSV",
- "prefill": ["title", "url", "price"],
- "editor": "stringList"
- },
- "maxItems": {
- "title": "Max items",
- "type": "integer",
- "description": "Fill the maximum number of items to export.",
- "default": 10
- }
- },
- "required": ["useClient", "memory", "fields", "maxItems"]
+ "required": ["useClient", "memory", "fields", "maxItems"]
}
```
diff --git a/sources/academy/platform/get_most_of_actors/monetizing_your_actor.md b/sources/academy/platform/get_most_of_actors/monetizing_your_actor.md
index 0f3726b1f7..74bd756455 100644
--- a/sources/academy/platform/get_most_of_actors/monetizing_your_actor.md
+++ b/sources/academy/platform/get_most_of_actors/monetizing_your_actor.md
@@ -28,7 +28,8 @@ You make your Actor rental with 7 days free trial and then $30/month. During the
2. Second user, on Apify paid plan, starts the free trial on 25th
3. Third user, on Apify free plan, start the free trial on 20th
-The first user pays their first rent 7 days after the free trial, i.e., on 22nd. The second user only starts paying the rent next month. The third user is on Apify free plan, so after the free trial ends on 27th, they are not charged and cannot use the Actor further until they get a paid plan. Your profit is computed only from the first user. They were charged $30, so 80% of this goes to you, i.e., _0.8 * 30 = $24_.
+The first user pays their first rent 7 days after the free trial, i.e., on 22nd. The second user only starts paying the rent next month. The third user is on Apify free plan, so after the free trial ends on 27th, they are not charged and cannot use the Actor further until they get a paid plan. Your profit is computed only from the first user. They were charged $30, so 80% of this goes to you, i.e., _0.8 \* 30 = $24_.
+
## Pay-per-result pricing model
@@ -40,7 +41,7 @@ In this model, you set a price per 1000 results. Users are charged based on the
### Pay-per-result unit pricing for cost computation
| Service | Unit price |
-|:--------------------------------|:---------------------------|
+| :------------------------------ | :------------------------- |
| Compute unit | **$0.3** / CU |
| Residential proxies | **$13** / GB |
| SERPs proxy | **$3** / 1,000 SERPs |
@@ -57,7 +58,6 @@ In this model, you set a price per 1000 results. Users are charged based on the
| Request queue - reads | **$0.004** / 1,000 reads |
| Request queue - writes | **$0.02** / 1,000 writes |
-
Only revenue & cost for Apify customers on paid plans are taken into consideration when computing your profit. Users on free plans are not reflected there, although you can see statistics about the potential revenue of users that are currently on free plans in Actor Insights in the Apify Console.
:::note What are Gigabyte-hours?
@@ -66,8 +66,8 @@ Gigabyte-hours (GB-hours) are a unit of measurement used to quantify data storag
For example, if you host 50GB of data for 30 days:
-- Convert days to hours: _30 * 24 = 720_
-- Multiply data size by hours: _50 * 720 = 36,000_
+- Convert days to hours: _30 \* 24 = 720_
+- Multiply data size by hours: _50 \* 720 = 36,000_
This means that storing 50 GB of data for 30 days results in 36,000 GB-hours.
:::
@@ -79,7 +79,8 @@ Read more about Actors in the Store and different pricing models from the perspe
You make your Actor pay-per-result and set price to be $1/1,000 results. During the first month, two users on Apify paid plans use your Actor to get 50,000 and 20,000 results, costing them $50 and $20 respectively. Let's say the underlying platform usage for the first user is $5 and for the second $2. Third user, this time on Apify free plan, uses the Actor to get 5,000 results, with underlying platform usage $0.5.
-Your profit is computed only from the first two users, since they are on Apify paid plans. The revenue for the first user is $50 and for the second $20, i.e., total revenue is $70. The total underlying cost is _$5 + $2 = $7_. Since your profit is 80% of the revenue minus the cost, it would be _0.8 * 70 - 7 = $49_.
+Your profit is computed only from the first two users, since they are on Apify paid plans. The revenue for the first user is $50 and for the second $20, i.e., total revenue is $70. The total underlying cost is _$5 + $2 = $7_. Since your profit is 80% of the revenue minus the cost, it would be _0.8 \* 70 - 7 = $49_.
+
### Best practices for Pay-per-results Actors
@@ -143,7 +144,6 @@ Create SEO-optimized descriptions and README files to improve search engine visi
- Publish articles about your Actor on relevant websites
- Consider creating a product showcase on platforms like Product hunt
-
Remember to tag Apify in your social media posts for additional exposure. Effective promotion can significantly impact your Actor's success, differentiating between those with many paid users and those with few to none.
Learn more about promoting your Actor from [Apify's Marketing Playbook](https://apify.notion.site/3fdc9fd4c8164649a2024c9ca7a2d0da?v=6d262c0b026d49bfa45771cd71f8c9ab).
diff --git a/sources/academy/platform/getting_started/apify_client.md b/sources/academy/platform/getting_started/apify_client.md
index 4cc4b4e6d2..7ffccad988 100644
--- a/sources/academy/platform/getting_started/apify_client.md
+++ b/sources/academy/platform/getting_started/apify_client.md
@@ -12,7 +12,7 @@ import TabItem from '@theme/TabItem';
---
-Now that you've gotten your toes wet with interacting with the Apify API through raw HTTP requests, you're ready to become familiar with the **Apify client**, which is a package available for both JavaScript and Python that allows you to interact with the API in your code without explicitly needing to make any GET or POST requests.
+Now that you've gotten your toes wet with interacting with the Apify API through raw HTTP requests, you're ready to become familiar with the **Apify client**, which is a package available for both JavaScript and Python that allows you to interact with the API in your code without explicitly needing to make any GET or POST requests.
This lesson will provide code examples for both Node.js and Python, so regardless of the language you are using, you can follow along!
diff --git a/sources/academy/platform/getting_started/creating_actors.md b/sources/academy/platform/getting_started/creating_actors.md
index a1c6505b43..b7eea4ccb2 100644
--- a/sources/academy/platform/getting_started/creating_actors.md
+++ b/sources/academy/platform/getting_started/creating_actors.md
@@ -22,9 +22,9 @@ You'll be presented with a page featuring two ways to get started with a new Act
1. Creating an Actor from existing source code (using Git providers or pushing the code from your local machine using Apify CLI)
2. Creating an Actor from a code template
-| Existing source code | Code templates |
-|:---------------------------------------------------------------------------------:|:--------------------------------------------------------------------------------:|
-|  |  |
+| Existing source code | Code templates |
+| :------------------------------------------------------------------------------: | :------------------------------------------------------------------------------: |
+|  |  |
## Creating Actor from existing source code {#existing-source-code}
diff --git a/sources/academy/tutorials/api/index.md b/sources/academy/tutorials/api/index.md
index 4cd998bdd9..face662d28 100644
--- a/sources/academy/tutorials/api/index.md
+++ b/sources/academy/tutorials/api/index.md
@@ -14,4 +14,3 @@ This section explains how you can run [Apify Actors](/platform/actors) using Api
- [JavaScript](/api/client/js/)
- [Python](/api/client/python)
-
diff --git a/sources/academy/tutorials/api/retry_failed_requests.md b/sources/academy/tutorials/api/retry_failed_requests.md
index 90c25aed59..03bf616123 100644
--- a/sources/academy/tutorials/api/retry_failed_requests.md
+++ b/sources/academy/tutorials/api/retry_failed_requests.md
@@ -24,7 +24,7 @@ const REQUEST_QUEUE_ID = 'pFCvCasdvsyvyZdfD'; // Replace with your valid request
const allRequests = [];
let exclusiveStartId = null;
// List all requests from the queue, we have to do it in a loop because the request queue list is paginated
-for (; ;) {
+for (;;) {
const { items: requests } = await Actor.apifyClient
.requestQueue(REQUEST_QUEUE_ID)
.listRequests({ exclusiveStartId, limit: 1000 });
@@ -41,7 +41,9 @@ for (; ;) {
console.log(`Loaded ${allRequests.length} requests from the queue`);
// Now we filter the failed requests
-const failedRequests = allRequests.filter((request) => (request.errorMessages?.length || 0) > (request.retryCount || 0));
+const failedRequests = allRequests.filter(
+ (request) => (request.errorMessages?.length || 0) > (request.retryCount || 0),
+);
// We need to update them 1 by 1 to the pristine state
for (const request of failedRequests) {
diff --git a/sources/academy/tutorials/api/run_actor_and_retrieve_data_via_api.md b/sources/academy/tutorials/api/run_actor_and_retrieve_data_via_api.md
index d852059967..18681c4b27 100644
--- a/sources/academy/tutorials/api/run_actor_and_retrieve_data_via_api.md
+++ b/sources/academy/tutorials/api/run_actor_and_retrieve_data_via_api.md
@@ -15,7 +15,6 @@ The most popular way of [integrating](https://help.apify.com/en/collections/1669
> Remember to check out our [API documentation](/api/v2) with examples in different languages and a live API console. We also recommend testing the API with a desktop client like [Postman](https://www.postman.com/) or [Insomnia](https://insomnia.rest).
-
Apify API offers two ways of interacting with it:
- [Synchronously](#synchronous-flow)
diff --git a/sources/academy/tutorials/apify_scrapers/cheerio_scraper.md b/sources/academy/tutorials/apify_scrapers/cheerio_scraper.md
index 586a835b40..e1be05ce19 100644
--- a/sources/academy/tutorials/apify_scrapers/cheerio_scraper.md
+++ b/sources/academy/tutorials/apify_scrapers/cheerio_scraper.md
@@ -7,7 +7,7 @@ sidebar_position: 3
slug: /apify-scrapers/cheerio-scraper
---
-[//]: # (TODO: Should be updated)
+[//]: # 'TODO: Should be updated'
#
@@ -34,18 +34,18 @@ Now that's out of the way, let's open one of the Actor detail pages in the Store
**Web Scraper** ([apify/web-scraper](https://apify.com/apify/web-scraper)) page, and use our DevTools-Fu to scrape some data.
> If you're wondering why we're using Web Scraper as an example instead of Cheerio Scraper,
-it's only because we didn't want to triple the number of screenshots we needed to make. Lazy developers!
+> it's only because we didn't want to triple the number of screenshots we needed to make. Lazy developers!
## Building our Page function
Before we start, let's do a quick recap of the data we chose to scrape:
- 1. **URL** - The URL that goes directly to the Actor's detail page.
- 2. **Unique identifier** - Such as **apify/web-scraper**.
- 3. **Title** - The title visible in the Actor's detail page.
- 4. **Description** - The Actor's description.
- 5. **Last modification date** - When the Actor was last modified.
- 6. **Number of runs** - How many times the Actor was run.
+1. **URL** - The URL that goes directly to the Actor's detail page.
+2. **Unique identifier** - Such as **apify/web-scraper**.
+3. **Title** - The title visible in the Actor's detail page.
+4. **Description** - The Actor's description.
+5. **Last modification date** - When the Actor was last modified.
+6. **Number of runs** - How many times the Actor was run.
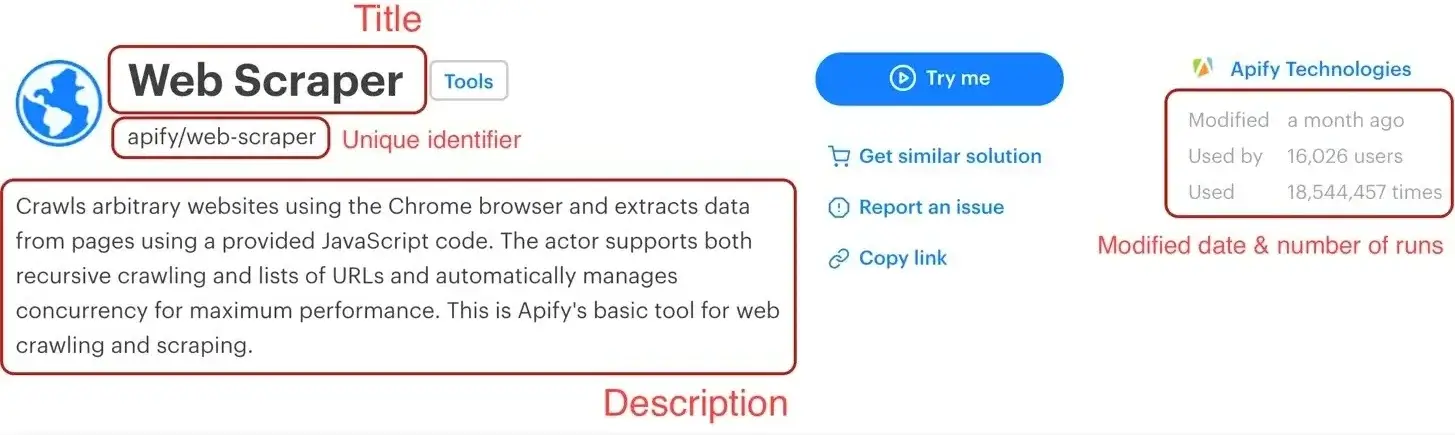
@@ -110,11 +110,7 @@ async function pageFunction(context) {
return {
title: $('header h1').text(),
description: $('header span.actor-description').text(),
- modifiedDate: new Date(
- Number(
- $('ul.ActorHeader-stats time').attr('datetime'),
- ),
- ),
+ modifiedDate: new Date(Number($('ul.ActorHeader-stats time').attr('datetime'))),
};
}
```
@@ -137,11 +133,7 @@ async function pageFunction(context) {
return {
title: $('header h1').text(),
description: $('header span.actor-description').text(),
- modifiedDate: new Date(
- Number(
- $('ul.ActorHeader-stats time').attr('datetime'),
- ),
- ),
+ modifiedDate: new Date(Number($('ul.ActorHeader-stats time').attr('datetime'))),
runCount: Number(
$('ul.ActorHeader-stats > li:nth-of-type(3)')
.text()
@@ -175,21 +167,14 @@ async function pageFunction(context) {
const { url } = request;
// ... rest of your code can come here
- const uniqueIdentifier = url
- .split('/')
- .slice(-2)
- .join('/');
+ const uniqueIdentifier = url.split('/').slice(-2).join('/');
return {
url,
uniqueIdentifier,
title: $('header h1').text(),
description: $('header span.actor-description').text(),
- modifiedDate: new Date(
- Number(
- $('ul.ActorHeader-stats time').attr('datetime'),
- ),
- ),
+ modifiedDate: new Date(Number($('ul.ActorHeader-stats time').attr('datetime'))),
runCount: Number(
$('ul.ActorHeader-stats > li:nth-of-type(3)')
.text()
@@ -216,21 +201,14 @@ async function pageFunction(context) {
await skipLinks();
// Do some scraping.
- const uniqueIdentifier = url
- .split('/')
- .slice(-2)
- .join('/');
+ const uniqueIdentifier = url.split('/').slice(-2).join('/');
return {
url,
uniqueIdentifier,
title: $('header h1').text(),
description: $('header span.actor-description').text(),
- modifiedDate: new Date(
- Number(
- $('ul.ActorHeader-stats time').attr('datetime'),
- ),
- ),
+ modifiedDate: new Date(Number($('ul.ActorHeader-stats time').attr('datetime'))),
runCount: Number(
$('ul.ActorHeader-stats > li:nth-of-type(3)')
.text()
@@ -255,9 +233,9 @@ actually scrape all the Actors, just the first page of results. That's because t
one needs to click the **Show more** button at the very bottom of the list. This is pagination.
> This is a typical JavaScript pagination, sometimes called infinite scroll. Other pages may use links
-that take you to the next page. If you encounter those, make a Pseudo URL for those links and they
-will be automatically enqueued to the request queue. Use a label to let the scraper know what kind of URL
-it's processing.
+> that take you to the next page. If you encounter those, make a Pseudo URL for those links and they
+> will be automatically enqueued to the request queue. Use a label to let the scraper know what kind of URL
+> it's processing.
If you paid close attention, you may now see a problem. How do we click a button in the page when we're working
with Cheerio? We don't have a browser to do it and we only have the HTML of the page to work with. The simple
@@ -305,9 +283,9 @@ we need is there, in the `data.props.pageProps.items` array. Great!
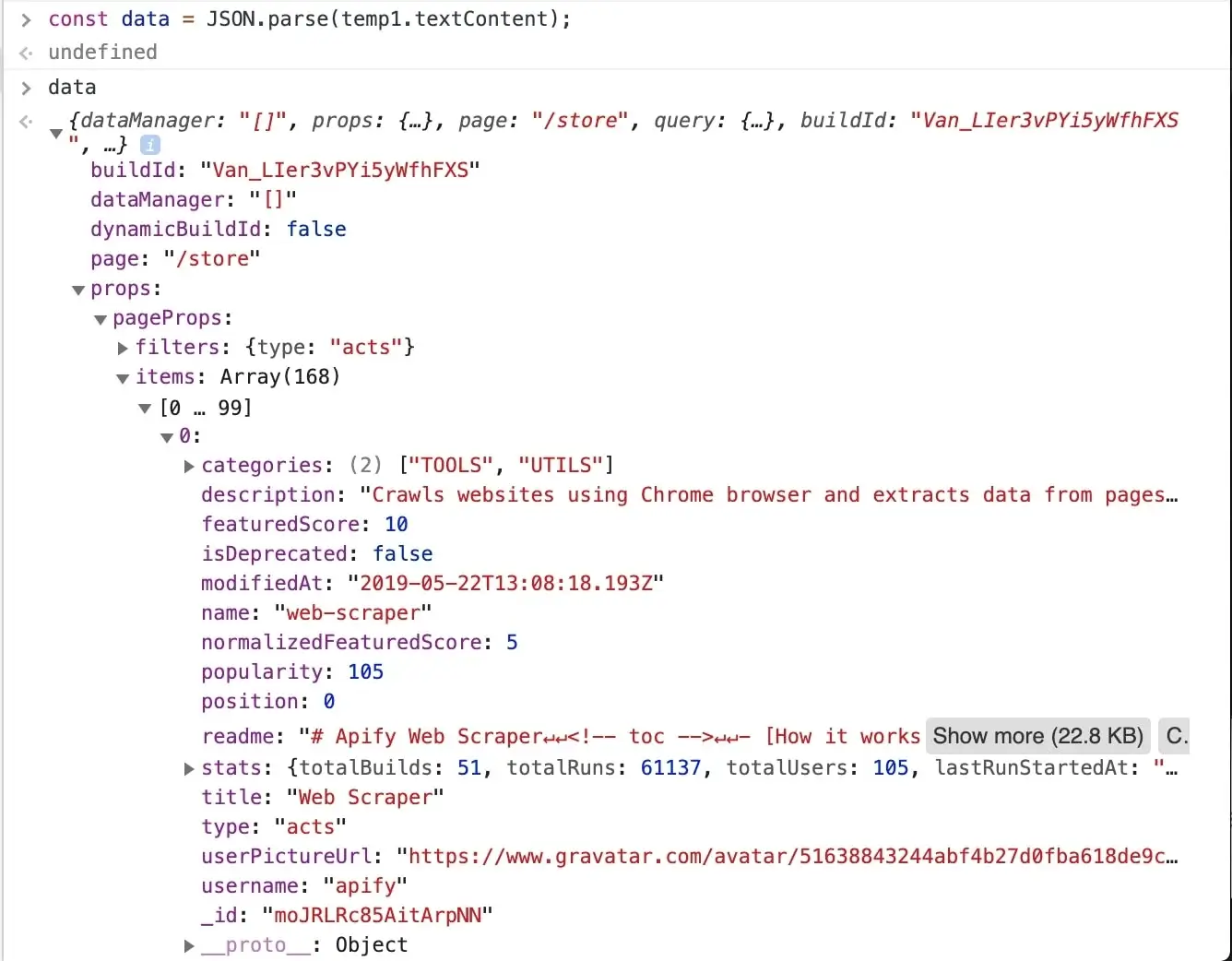
> It's obvious that all the information we set to scrape is available in this one data object,
-so you might already be wondering, can I make one request to the store to get this JSON
-and then parse it out and be done with it in a single request? Yes you can! And that's the power
-of clever page analysis.
+> so you might already be wondering, can I make one request to the store to get this JSON
+> and then parse it out and be done with it in a single request? Yes you can! And that's the power
+> of clever page analysis.
### Using the data to enqueue all Actor details
@@ -339,8 +317,8 @@ We iterate through the items we found, build Actor detail URLs from the availabl
those URLs into the request queue. We need to specify the label too, otherwise our page function wouldn't know
how to route those requests.
->If you're wondering how we know the structure of the URL, see the [Getting started
-with Apify Scrapers](./getting_started.md) tutorial again.
+> If you're wondering how we know the structure of the URL, see the [Getting started
+> with Apify Scrapers](./getting_started.md) tutorial again.
### Plugging it into the Page function
@@ -374,21 +352,14 @@ async function pageFunction(context) {
await skipLinks();
// Do some scraping.
- const uniqueIdentifier = url
- .split('/')
- .slice(-2)
- .join('/');
+ const uniqueIdentifier = url.split('/').slice(-2).join('/');
return {
url,
uniqueIdentifier,
title: $('header h1').text(),
description: $('header span.actor-description').text(),
- modifiedDate: new Date(
- Number(
- $('ul.ActorHeader-stats time').attr('datetime'),
- ),
- ),
+ modifiedDate: new Date(Number($('ul.ActorHeader-stats time').attr('datetime'))),
runCount: Number(
$('ul.ActorHeader-stats > li:nth-of-type(3)')
.text()
@@ -406,10 +377,10 @@ You should have a table of all the Actor's details in front of you. If you do, g
scraped Apify Store. And if not, no worries, go through the code examples again, it's probably just a typo.
> There's an important caveat. The way we implemented pagination here is in no way a generic system that you can
-use with other websites. Cheerio is fast (and that means it's cheap), but it's not easy. Sometimes there's just no way
-to get all results with Cheerio only and other times it takes hours of research. Keep this in mind when choosing
-the right scraper for your job. But don't get discouraged. Often times, the only thing you will ever need is to
-define a correct Pseudo URL. Do your research first before giving up on Cheerio Scraper.
+> use with other websites. Cheerio is fast (and that means it's cheap), but it's not easy. Sometimes there's just no way
+> to get all results with Cheerio only and other times it takes hours of research. Keep this in mind when choosing
+> the right scraper for your job. But don't get discouraged. Often times, the only thing you will ever need is to
+> define a correct Pseudo URL. Do your research first before giving up on Cheerio Scraper.
## Downloading the scraped data
@@ -436,9 +407,12 @@ that encapsulate all the different logic. You can, for example, define a functio
```js
async function pageFunction(context) {
switch (context.request.userData.label) {
- case 'START': return handleStart(context);
- case 'DETAIL': return handleDetail(context);
- default: throw new Error('Unknown request label.');
+ case 'START':
+ return handleStart(context);
+ case 'DETAIL':
+ return handleDetail(context);
+ default:
+ throw new Error('Unknown request label.');
}
async function handleStart({ log, waitFor, $ }) {
@@ -466,21 +440,14 @@ async function pageFunction(context) {
await skipLinks();
// Do some scraping.
- const uniqueIdentifier = url
- .split('/')
- .slice(-2)
- .join('/');
+ const uniqueIdentifier = url.split('/').slice(-2).join('/');
return {
url,
uniqueIdentifier,
title: $('header h1').text(),
description: $('header span.actor-description').text(),
- modifiedDate: new Date(
- Number(
- $('ul.ActorHeader-stats time').attr('datetime'),
- ),
- ),
+ modifiedDate: new Date(Number($('ul.ActorHeader-stats time').attr('datetime'))),
runCount: Number(
$('ul.ActorHeader-stats > li:nth-of-type(3)')
.text()
@@ -493,7 +460,7 @@ async function pageFunction(context) {
```
> If you're confused by the functions being declared below their executions, it's called hoisting and it's a feature
-of JavaScript. It helps you put what matters on top, if you so desire.
+> of JavaScript. It helps you put what matters on top, if you so desire.
## Final word
@@ -501,10 +468,9 @@ Thank you for reading this whole tutorial! Really! It's important to us that our
## What's next
-* Check out the [Apify SDK](https://docs.apify.com/sdk) and its [Getting started](https://docs.apify.com/sdk/js/docs/guides/apify-platform) tutorial if you'd like to try building your own Actors. It's a bit more complex and involved than writing a `pageFunction`, but it allows you to fine-tune all the details of your scraper to your liking.
-* [Take a deep dive into Actors](/platform/actors), from how they work to [publishing](/platform/actors/publishing) them in Apify Store, and even [making money](https://blog.apify.com/make-regular-passive-income-developing-web-automation-actors-b0392278d085/) on Actors.
-* Found out you're not into the coding part but would still to use Apify Actors? Check out our [ready-made solutions](https://apify.com/store) or [order a custom Actor](https://apify.com/contact-sales) from an Apify-certified developer.
-
+- Check out the [Apify SDK](https://docs.apify.com/sdk) and its [Getting started](https://docs.apify.com/sdk/js/docs/guides/apify-platform) tutorial if you'd like to try building your own Actors. It's a bit more complex and involved than writing a `pageFunction`, but it allows you to fine-tune all the details of your scraper to your liking.
+- [Take a deep dive into Actors](/platform/actors), from how they work to [publishing](/platform/actors/publishing) them in Apify Store, and even [making money](https://blog.apify.com/make-regular-passive-income-developing-web-automation-actors-b0392278d085/) on Actors.
+- Found out you're not into the coding part but would still to use Apify Actors? Check out our [ready-made solutions](https://apify.com/store) or [order a custom Actor](https://apify.com/contact-sales) from an Apify-certified developer.
**Learn how to scrape a website using Apify's Cheerio Scraper. Build an Actor's page function, extract information from a web page and download your data.**
diff --git a/sources/academy/tutorials/apify_scrapers/getting_started.md b/sources/academy/tutorials/apify_scrapers/getting_started.md
index 9b05130eba..9ef63ae65c 100644
--- a/sources/academy/tutorials/apify_scrapers/getting_started.md
+++ b/sources/academy/tutorials/apify_scrapers/getting_started.md
@@ -7,7 +7,7 @@ sidebar_position: 1
slug: /apify-scrapers/getting-started
---
-[//]: # (TODO: Should be updated)
+[//]: # 'TODO: Should be updated'
#
@@ -37,7 +37,7 @@ Scroll down to the **Performance and limits** section and set the **Max pages pe
> This also helps with keeping your [compute unit](/platform/actors/running/usage-and-resources) (CU) consumption low. To get an idea, our free plan includes 10 CUs and this run will consume about 0.04 CU, so you can run it 250 times a month for free. If you accidentally go over the limit, no worries, we won't charge you for it. You just won't be able to run more tasks that month.
-Now click **Save & Run**! *(in the bottom-left part of your screen)*
+Now click **Save & Run**! _(in the bottom-left part of your screen)_
### The run detail
@@ -97,12 +97,12 @@ Since this is a tutorial, we'll be scraping our own website. [Apify Store](https
We want to create a scraper that scrapes all the Actors in the store and collects the following attributes for each Actor:
- 1. **URL** - The URL that goes directly to the Actor's detail page.
- 2. **Unique identifier** - Such as **apify/web-scraper**.
- 3. **Title** - The title visible in the Actor's detail page.
- 4. **Description** - The Actor's description.
- 5. **Last modification date** - When the Actor was last modified.
- 6. **Number of runs** - How many times the Actor was run.
+1. **URL** - The URL that goes directly to the Actor's detail page.
+2. **Unique identifier** - Such as **apify/web-scraper**.
+3. **Title** - The title visible in the Actor's detail page.
+4. **Description** - The Actor's description.
+5. **Last modification date** - When the Actor was last modified.
+6. **Number of runs** - How many times the Actor was run.
Some of this information may be scraped directly from the listing pages, but for the rest, we will need to visit the detail pages of all the Actors.
@@ -120,7 +120,7 @@ We also need to somehow distinguish the **Start URL** from all the other URLs th
```json
{
- "label": "START"
+ "label": "START"
}
```
@@ -184,7 +184,7 @@ Let's use the above **Pseudo URL** in our task. We should also add a label as we
```json
{
- "label": "DETAIL"
+ "label": "DETAIL"
}
```
@@ -268,8 +268,8 @@ async function pageFunction(context) {
will produce the following table:
-| title | url |
-| ----- | --- |
+| title | url |
+| ---------------------------------------------------- | ----------------- |
| Web Scraping, Data Extraction and Automation - Apify | https://apify.com |
## Scraper lifecycle
@@ -279,12 +279,12 @@ or in other words, what the scraper actually does when it scrapes. It's quite st
The scraper:
- 1. Visits the first **Start URL** and waits for the page to load.
- 2. Executes the `pageFunction`.
- 3. Finds all the elements matching the **Link selector** and extracts their `href` attributes (URLs).
- 4. Uses the **pseudo URLs** to filter the extracted URLs and throws away those that don't match.
- 5. Enqueues the matching URLs to the end of the crawling queue.
- 6. Closes the page and selects a new URL to visit, either from the **Start URL**s if there are any left, or from the beginning of the crawling queue.
+1. Visits the first **Start URL** and waits for the page to load.
+2. Executes the `pageFunction`.
+3. Finds all the elements matching the **Link selector** and extracts their `href` attributes (URLs).
+4. Uses the **pseudo URLs** to filter the extracted URLs and throws away those that don't match.
+5. Enqueues the matching URLs to the end of the crawling queue.
+6. Closes the page and selects a new URL to visit, either from the **Start URL**s if there are any left, or from the beginning of the crawling queue.
> When you're not using the request queue, the scraper repeats steps 1 and 2. You would not use the request queue when you already know all the URLs you want to visit. For example, when you have a pre-existing list of a thousand URLs that you uploaded as a text file. Or when scraping a single URL.
@@ -314,10 +314,7 @@ async function pageFunction(context) {
await skipLinks();
// Do some scraping.
- const uniqueIdentifier = url
- .split('/')
- .slice(-2)
- .join('/');
+ const uniqueIdentifier = url.split('/').slice(-2).join('/');
return {
url,
diff --git a/sources/academy/tutorials/apify_scrapers/puppeteer_scraper.md b/sources/academy/tutorials/apify_scrapers/puppeteer_scraper.md
index 130713691a..312d48ed5c 100644
--- a/sources/academy/tutorials/apify_scrapers/puppeteer_scraper.md
+++ b/sources/academy/tutorials/apify_scrapers/puppeteer_scraper.md
@@ -7,7 +7,7 @@ sidebar_position: 4
slug: /apify-scrapers/puppeteer-scraper
---
-[//]: # (TODO: Should be updated)
+[//]: # 'TODO: Should be updated'
#
@@ -30,8 +30,8 @@ so that you can start using it for some of the most typical scraping tasks, but
you'll need to visit its [documentation](https://pptr.dev/) and really dive deep into its intricacies.
> The purpose of Puppeteer Scraper is to remove some of the difficulty faced when using Puppeteer by wrapping
-it in a nice, manageable UI. It provides almost all of its features in a format that is much easier to grasp
-when first trying to scrape using Puppeteer.
+> it in a nice, manageable UI. It provides almost all of its features in a format that is much easier to grasp
+> when first trying to scrape using Puppeteer.
### Web Scraper differences
@@ -49,18 +49,18 @@ Puppeteer Scraper is powerful (and the [Apify SDK](https://sdk.apify.com) is sup
Now that's out of the way, let's open one of the Actor detail pages in the Store, for example the Web Scraper page and use our DevTools-Fu to scrape some data.
> If you're wondering why we're using Web Scraper as an example instead of Puppeteer Scraper,
-it's only because we didn't want to triple the number of screenshots we needed to make. Lazy developers!
+> it's only because we didn't want to triple the number of screenshots we needed to make. Lazy developers!
## Building our Page function
Before we start, let's do a quick recap of the data we chose to scrape:
- 1. **URL** - The URL that goes directly to the Actor's detail page.
- 2. **Unique identifier** - Such as **apify/web-scraper**.
- 3. **Title** - The title visible in the Actor's detail page.
- 4. **Description** - The Actor's description.
- 5. **Last modification date** - When the Actor was last modified.
- 6. **Number of runs** - How many times the Actor was run.
+1. **URL** - The URL that goes directly to the Actor's detail page.
+2. **Unique identifier** - Such as **apify/web-scraper**.
+3. **Title** - The title visible in the Actor's detail page.
+4. **Description** - The Actor's description.
+5. **Last modification date** - When the Actor was last modified.
+6. **Number of runs** - How many times the Actor was run.

@@ -87,10 +87,7 @@ And as we already know, there's only one.
// Using Puppeteer
async function pageFunction(context) {
const { page } = context;
- const title = await page.$eval(
- 'header h1',
- ((el) => el.textContent),
- );
+ const title = await page.$eval('header h1', (el) => el.textContent);
return {
title,
@@ -113,14 +110,8 @@ the `` element too, same as the title. Moreover, the actual description
```js
async function pageFunction(context) {
const { page } = context;
- const title = await page.$eval(
- 'header h1',
- ((el) => el.textContent),
- );
- const description = await page.$eval(
- 'header span.actor-description',
- ((el) => el.textContent),
- );
+ const title = await page.$eval('header h1', (el) => el.textContent);
+ const description = await page.$eval('header span.actor-description', (el) => el.textContent);
return {
title,
@@ -138,18 +129,11 @@ The DevTools tell us that the `modifiedDate` can be found in a `
 +
+