-
-
-  -
-
-
-
-
-
-
- -
-
-
--
- -
-
-
Reasoning-based RAG ◦ No Vector DB ◦ No Chunking ◦ Human-like Retrieval
- -- 🏠 Homepage • - 🖥️ Chat Platform • - 🔌 MCP • - 📚 Docs • - 💬 Discord • - ✉️ Contact -
- -
-
-
- **🔥 Releases:**
-- [**PageIndex Chat**](https://chat.pageindex.ai): The first human-like document-analysis agent [platform](https://chat.pageindex.ai) built for professional long documents. Can also be integrated via [MCP](https://pageindex.ai/mcp) or [API](https://docs.pageindex.ai/quickstart) (beta).
-
-
-
- **📝 Articles:**
-- [**PageIndex Framework**](https://pageindex.ai/blog/pageindex-intro): Introduces the PageIndex framework — an *agentic, in-context* *tree index* that enables LLMs to perform *reasoning-based*, *human-like retrieval* over long documents, without vector DB or chunking.
-
-
- **🧪 Cookbooks:**
-- [Vectorless RAG](https://docs.pageindex.ai/cookbook/vectorless-rag-pageindex): A minimal, hands-on example of reasoning-based RAG using PageIndex. No vectors, no chunking, and human-like retrieval.
-- [Vision-based Vectorless RAG](https://docs.pageindex.ai/cookbook/vision-rag-pageindex): OCR-free, vision-only RAG with PageIndex's reasoning-native retrieval workflow that works directly over PDF page images.
-
+# 🌲 PageIndexOllama: Local-First Tree RAG for Long Documents
+
+**PageIndex-Ollama** is an independent fork of PageIndex focused on **fully local document indexing and reasoning** with **Ollama**.
+
+You point it to a PDF (or Markdown), it builds a **hierarchical tree index**, and then uses LLM reasoning over that tree to retrieve relevant sections.
+
+Run it on your own machine with **no API keys** and no required external inference service.
+
+Detailed technical delta report: [ENHANCEMENTS_REPORT.md](ENHANCEMENTS_REPORT.md)
---
-# 📑 Introduction to PageIndex
+## ✨ Why This Fork Exists
-Are you frustrated with vector database retrieval accuracy for long professional documents? Traditional vector-based RAG relies on semantic *similarity* rather than true *relevance*. But **similarity ≠ relevance** — what we truly need in retrieval is **relevance**, and that requires **reasoning**. When working with professional documents that demand domain expertise and multi-step reasoning, similarity search often falls short.
+The upstream project is broad. This fork is opinionated:
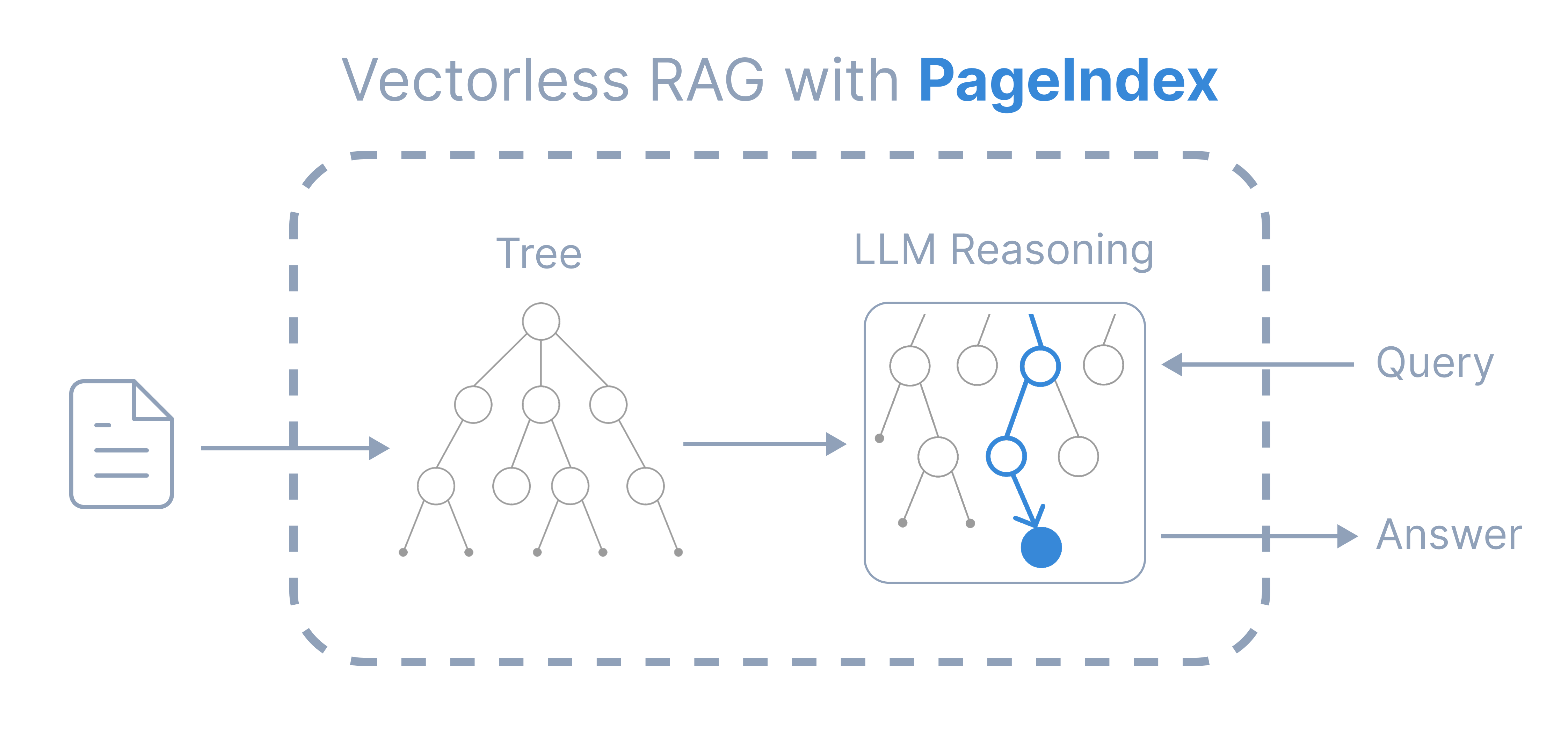
-Inspired by AlphaGo, we propose **[PageIndex](https://vectify.ai/pageindex)** — a **vectorless**, **reasoning-based RAG** system that builds a **hierarchical tree index** from long documents and uses LLMs to **reason** *over that index* for **agentic, context-aware retrieval**.
-It simulates how *human experts* navigate and extract knowledge from complex documents through *tree search*, enabling LLMs to *think* and *reason* their way to the most relevant document sections. PageIndex performs retrieval in two steps:
+- local-first workflows
+- Ollama as the default inference backend
+- minimal cloud assumptions in setup and usage docs
+- engineer-focused, reproducible CLI + test flow
-1. Generate a “Table-of-Contents” **tree structure index** of documents
-2. Perform reasoning-based retrieval through **tree search**
+This repo keeps the core PageIndex retrieval design while making local execution the default operating mode.
-📢 Latest Updates
-
- **🔥 Releases:**
-- [**PageIndex Chat**](https://chat.pageindex.ai): The first human-like document-analysis agent [platform](https://chat.pageindex.ai) built for professional long documents. Can also be integrated via [MCP](https://pageindex.ai/mcp) or [API](https://docs.pageindex.ai/quickstart) (beta).
-
-
-
- **📝 Articles:**
-- [**PageIndex Framework**](https://pageindex.ai/blog/pageindex-intro): Introduces the PageIndex framework — an *agentic, in-context* *tree index* that enables LLMs to perform *reasoning-based*, *human-like retrieval* over long documents, without vector DB or chunking.
-
-
- **🧪 Cookbooks:**
-- [Vectorless RAG](https://docs.pageindex.ai/cookbook/vectorless-rag-pageindex): A minimal, hands-on example of reasoning-based RAG using PageIndex. No vectors, no chunking, and human-like retrieval.
-- [Vision-based Vectorless RAG](https://docs.pageindex.ai/cookbook/vision-rag-pageindex): OCR-free, vision-only RAG with PageIndex's reasoning-native retrieval workflow that works directly over PDF page images.
-
-
-  -
-
-
-
+---
-### 🎯 Core Features
+## 🔍 What’s Different From Upstream PageIndex
+
+- OpenAI SDK is not part of the documented local workflow for this fork.
+- Ollama is the default backend used in setup and examples.
+- Provider abstraction is retained so model-call logic stays isolated from pipeline logic.
+- Offline-capable after model download.
+- No external API dependency required for normal local operation.
+
+### Enhancement Highlights in This Fork
+
+- **Runtime decoupling:** provider-routed wrappers replace OpenAI-tied call assumptions.
+- **Response contract stability:** finish-reason and response-shape normalization reduce provider-specific branching downstream.
+- **Prompt governance:** registry + loader architecture replaces large inline prompts and improves reproducibility.
+- **Performance:** bounded async parallelism accelerates TOC/summarization stages for local inference.
+- **Robustness:** adaptive chunking and hierarchical fallbacks reduce failure rates on difficult PDFs.
+- **Validation:** expanded e2e/integration/performance coverage validates local-first behavior end-to-end.
+
+### Upstream vs Fork (Practical Delta)
+
+| Area | Upstream | Fork | Decoupling Value |
+|---|---|---|---|
+| Provider API wrappers | OpenAI-branded wrappers | Provider-routed `Ollama_API*` wrappers | High |
+| Finish reason semantics | Provider-specific assumptions | Normalized response handler | High |
+| Credentials/env handling | More distributed | Centralized provider-aware module | Medium-High |
+| Prompt management | Inline prompt strings | Registry + loader + prompt files | High (operational) |
+| TOC/summary processing | More sequential | Async bounded concurrency | Medium-High |
+| Fallback behavior | Simpler/no hardening in some paths | Hierarchical/adaptive fallback paths | Medium |
+| CLI defaults | OpenAI model default | Local model default path | High (UX/ops) |
+| Test coverage | Minimal Python tests | Expanded e2e/integration/perf checks | High (risk reduction) |
+---
-Compared to traditional vector-based RAG, **PageIndex** features:
-- **No Vector DB**: Uses document structure and LLM reasoning for retrieval, instead of vector similarity search.
-- **No Chunking**: Documents are organized into natural sections, not artificial chunks.
-- **Human-like Retrieval**: Simulates how human experts navigate and extract knowledge from complex documents.
-- **Better Explainability and Traceability**: Retrieval is based on reasoning — traceable and interpretable, with page and section references. No more opaque, approximate vector search (“vibe retrieval”).
+## 🧠 How It Works (Architecture)
-PageIndex powers a reasoning-based RAG system that achieved **state-of-the-art** [98.7% accuracy](https://github.com/VectifyAI/Mafin2.5-FinanceBench) on FinanceBench, demonstrating superior performance over vector-based RAG solutions in professional document analysis (see our [blog post](https://vectify.ai/blog/Mafin2.5) for details).
+PageIndex-Ollama keeps the same core pattern:
-### 📍 Explore PageIndex
+1. Build a structured tree from a document
+2. Run LLM-guided search over that tree
+3. Generate answers from selected node context
-To learn more, please see a detailed introduction of the [PageIndex framework](https://pageindex.ai/blog/pageindex-intro). Check out this GitHub repo for open-source code, and the [cookbooks](https://docs.pageindex.ai/cookbook), [tutorials](https://docs.pageindex.ai/tutorials), and [blog](https://pageindex.ai/blog) for additional usage guides and examples.
+Key implementation points:
-The PageIndex service is available as a ChatGPT-style [chat platform](https://chat.pageindex.ai), or can be integrated via [MCP](https://pageindex.ai/mcp) or [API](https://docs.pageindex.ai/quickstart).
+- `pageindex/page_index.py` contains the PDF pipeline (`page_index_main`) and tree construction flow.
+- `pageindex/page_index_md.py` provides the Markdown path (`md_to_tree`).
+- `pageindex/utils.py` contains model-call wrappers (`Ollama_API_with_finish_reason`, `Ollama_API`, `Ollama_API_async`) and env-driven provider/model resolution.
+- `pageindex/response_handlers.py` normalizes response shape (including finish reason handling) to keep downstream logic stable.
+- `pageindex/continuation.py` handles truncated outputs by generating continuation prompts and stitching responses.
+- `pageindex/credentials.py` centralizes provider-specific credential/environment resolution.
+- `pageindex/models.py` defines typed schemas for structured outputs and parsing stability.
+- `pageindex/chunking_config.py` provides adaptive chunking strategy used for large-document handling.
+- Prompt templates are loaded through `pageindex/prompt_loader.py` and `pageindex/prompts/`.
-### 🛠️ Deployment Options
-- Self-host — run locally with this open-source repo.
-- Cloud Service — try instantly with our [Chat Platform](https://chat.pageindex.ai/), or integrate with [MCP](https://pageindex.ai/mcp) or [API](https://docs.pageindex.ai/quickstart).
-- _Enterprise_ — private or on-prem deployment. [Contact us](https://ii2abc2jejf.typeform.com/to/tK3AXl8T) or [book a demo](https://calendly.com/pageindex/meet) for more details.
+### Provider-Decoupling Design
-### 🧪 Quick Hands-on
+This fork keeps provider-specific behavior at the runtime boundary:
-- Try the [**Vectorless RAG**](https://github.com/VectifyAI/PageIndex/blob/main/cookbook/pageindex_RAG_simple.ipynb) notebook — a *minimal*, hands-on example of reasoning-based RAG using PageIndex.
-- Experiment with [*Vision-based Vectorless RAG*](https://github.com/VectifyAI/PageIndex/blob/main/cookbook/vision_RAG_pageindex.ipynb) — no OCR; a minimal, reasoning-native RAG pipeline that works directly over page images.
-
-
+1. Resolve provider/model from environment and config.
+2. Dispatch to provider-specific call path.
+3. Normalize output/finish reason into a stable internal shape.
+4. Continue tree/search/answer logic with provider-agnostic contracts.
----
+This keeps indexing and retrieval flows isolated from vendor-specific response differences.
-# 🌲 PageIndex Tree Structure
-PageIndex can transform lengthy PDF documents into a semantic **tree structure**, similar to a _"table of contents"_ but optimized for use with Large Language Models (LLMs). It's ideal for: financial reports, regulatory filings, academic textbooks, legal or technical manuals, and any document that exceeds LLM context limits.
-
-Below is an example PageIndex tree structure. Also see more example [documents](https://github.com/VectifyAI/PageIndex/tree/main/tests/pdfs) and generated [tree structures](https://github.com/VectifyAI/PageIndex/tree/main/tests/results).
-
-```jsonc
-...
-{
- "title": "Financial Stability",
- "node_id": "0006",
- "start_index": 21,
- "end_index": 22,
- "summary": "The Federal Reserve ...",
- "nodes": [
- {
- "title": "Monitoring Financial Vulnerabilities",
- "node_id": "0007",
- "start_index": 22,
- "end_index": 28,
- "summary": "The Federal Reserve's monitoring ..."
- },
- {
- "title": "Domestic and International Cooperation and Coordination",
- "node_id": "0008",
- "start_index": 28,
- "end_index": 31,
- "summary": "In 2023, the Federal Reserve collaborated ..."
- }
- ]
-}
-...
-```
+This design allows the same indexing/search pipeline to operate across providers with minimal call-site change.
+
+Runtime controls:
-You can generate the PageIndex tree structure with this open-source repo, or use our [API](https://docs.pageindex.ai/quickstart)
+- `LLM_PROVIDER=ollama`
+- `OLLAMA_URL=http://localhost:11434`
+- `OLLAMA_MODEL=mistral24b-16k` (or any installed Ollama model)
---
-# ⚙️ Package Usage
+## 🤖 Supported Models
+
+Any Ollama-compatible model can be used, including:
+
+- mistral
+- llama
+- qwen
+- other locally available Ollama models
-You can follow these steps to generate a PageIndex tree from a PDF document.
+Default examples in this repo use `mistral24b-16k`.
-### 1. Install dependencies
+Model quality and speed depend on:
+
+- model family + parameter size
+- quantization
+- context length
+- local CPU/GPU/VRAM
+
+---
+
+## 🚀 Quick Start (Local Only)
+
+### 1) Install dependencies
```bash
-pip3 install --upgrade -r requirements.txt
+pip install -r requirements.txt
```
-### 2. Set your OpenAI API key
+### 2) Install Ollama
+
+Use one of the repo scripts if helpful:
+
+```bash
+# Linux/macOS
+bash scripts/setup_ollama.sh
+
+# Windows PowerShell
+powershell scripts/setup_ollama.ps1
+```
-Create a `.env` file in the root directory and add your API key:
+### 3) Pull a model
```bash
-CHATGPT_API_KEY=your_openai_key_here
+ollama pull mistral24b-16k
```
-### 3. Run PageIndex on your PDF
+If that tag is unavailable on your machine, use any installed Ollama model and set `OLLAMA_MODEL` accordingly.
+
+### 4) Set environment variables
```bash
-python3 run_pageindex.py --pdf_path /path/to/your/document.pdf
+# Linux/macOS
+export LLM_PROVIDER=ollama
+export OLLAMA_URL=http://localhost:11434
+export OLLAMA_MODEL=mistral24b-16k
+
+# Windows PowerShell
+$env:LLM_PROVIDER="ollama"
+$env:OLLAMA_URL="http://localhost:11434"
+$env:OLLAMA_MODEL="mistral24b-16k"
```
-
-
-
-
-You can customize the processing with additional optional arguments: +### 5) Run the CLI + +PDF: +```bash +python cli.py --pdf_path /path/to/document.pdf --model mistral24b-16k ``` ---model OpenAI model to use (default: gpt-4o-2024-11-20) ---toc-check-pages Pages to check for table of contents (default: 20) ---max-pages-per-node Max pages per node (default: 10) ---max-tokens-per-node Max tokens per node (default: 20000) ---if-add-node-id Add node ID (yes/no, default: yes) ---if-add-node-summary Add node summary (yes/no, default: yes) ---if-add-doc-description Add doc description (yes/no, default: yes) + +Markdown: + +```bash +python cli.py --md_path /path/to/document.md --model mistral24b-16k ``` -
-Optional parameters
--You can customize the processing with additional optional arguments: +### 5) Run the CLI + +PDF: +```bash +python cli.py --pdf_path /path/to/document.pdf --model mistral24b-16k ``` ---model OpenAI model to use (default: gpt-4o-2024-11-20) ---toc-check-pages Pages to check for table of contents (default: 20) ---max-pages-per-node Max pages per node (default: 10) ---max-tokens-per-node Max tokens per node (default: 20000) ---if-add-node-id Add node ID (yes/no, default: yes) ---if-add-node-summary Add node summary (yes/no, default: yes) ---if-add-doc-description Add doc description (yes/no, default: yes) + +Markdown: + +```bash +python cli.py --md_path /path/to/document.md --model mistral24b-16k ``` -
-
-We also provide markdown support for PageIndex. You can use the `-md_path` flag to generate a tree structure for a markdown file. +Outputs are written to `results/*_structure.json`. + +--- + +## 🧪 Testing + +Main test surfaces: + +- `run_comprehensive_e2e_tests.py` +- `tests/e2e/` +- `tests/` +- `test_parallel_processing.py` + +Run: ```bash -python3 run_pageindex.py --md_path /path/to/your/document.md +python run_comprehensive_e2e_tests.py +python -m pytest tests ``` -> Note: in this function, we use "#" to determine node heading and their levels. For example, "##" is level 2, "###" is level 3, etc. Make sure your markdown file is formatted correctly. If your Markdown file was converted from a PDF or HTML, we don't recommend using this function, since most existing conversion tools cannot preserve the original hierarchy. Instead, use our [PageIndex OCR](https://pageindex.ai/blog/ocr), which is designed to preserve the original hierarchy, to convert the PDF to a markdown file and then use this function. -
+What these validate (end-to-end):
+
+- tree generation
+- tree availability/structure checks
+- LLM-driven node selection over tree content
+- answer generation from extracted node context
+- provider-decoupled response handling (including continuation behavior)
+- concurrency paths used for local throughput improvements
-
+### Why These Enhancements Matter Locally
+
+Local-first systems face two practical constraints: variable model quality and slower inference throughput.
+These enhancements directly target those constraints by improving deterministic behavior under imperfect outputs
+and reducing total latency through bounded parallelism.
---
-# 📈 Case Study: PageIndex Leads Finance QA Benchmark
+## 📌 Current Standardization Gaps
-[Mafin 2.5](https://vectify.ai/mafin) is a reasoning-based RAG system for financial document analysis, powered by **PageIndex**. It achieved a state-of-the-art [**98.7% accuracy**](https://vectify.ai/blog/Mafin2.5) on the [FinanceBench](https://arxiv.org/abs/2311.11944) benchmark, significantly outperforming traditional vector-based RAG systems.
+The core architecture is stable, but a few consistency items remain:
-PageIndex's hierarchical indexing and reasoning-driven retrieval enable precise navigation and extraction of relevant context from complex financial reports, such as SEC filings and earnings disclosures.
+- Canonical default model should be unified across CLI, config, docs, and tests.
+- Tree-search output key naming should be standardized (`node_ids` vs `relevant_node_ids`).
+- Some legacy naming/constants should be aligned with current model/provider behavior.
-Explore the full [benchmark results](https://github.com/VectifyAI/Mafin2.5-FinanceBench) and our [blog post](https://vectify.ai/blog/Mafin2.5) for detailed comparisons and performance metrics.
+These are consistency and maintenance concerns, not blockers for local-first operation.
-Markdown support
--We also provide markdown support for PageIndex. You can use the `-md_path` flag to generate a tree structure for a markdown file. +Outputs are written to `results/*_structure.json`. + +--- + +## 🧪 Testing + +Main test surfaces: + +- `run_comprehensive_e2e_tests.py` +- `tests/e2e/` +- `tests/` +- `test_parallel_processing.py` + +Run: ```bash -python3 run_pageindex.py --md_path /path/to/your/document.md +python run_comprehensive_e2e_tests.py +python -m pytest tests ``` -> Note: in this function, we use "#" to determine node heading and their levels. For example, "##" is level 2, "###" is level 3, etc. Make sure your markdown file is formatted correctly. If your Markdown file was converted from a PDF or HTML, we don't recommend using this function, since most existing conversion tools cannot preserve the original hierarchy. Instead, use our [PageIndex OCR](https://pageindex.ai/blog/ocr), which is designed to preserve the original hierarchy, to convert the PDF to a markdown file and then use this function. -
-
-  -
-
-
-
+For full technical analysis, see [ENHANCEMENTS_REPORT.md](ENHANCEMENTS_REPORT.md).
---
-# 🧭 Resources
+## ⚠️ Known Limitations
-* 🧪 [Cookbooks](https://docs.pageindex.ai/cookbook/vectorless-rag-pageindex): hands-on, runnable examples and advanced use cases.
-* 📖 [Tutorials](https://docs.pageindex.ai/doc-search): practical guides and strategies, including *Document Search* and *Tree Search*.
-* 📝 [Blog](https://pageindex.ai/blog): technical articles, research insights, and product updates.
-* 🔌 [MCP setup](https://pageindex.ai/mcp#quick-setup) & [API docs](https://docs.pageindex.ai/quickstart): integration details and configuration options.
+- Local model choice matters a lot; small models can struggle on deep reasoning.
+- ~3B class models are usually weaker than larger frontier-class systems on complex document QA.
+- Very large PDFs can pressure RAM/VRAM depending on model/context settings.
+- Inference throughput and latency are hardware-dependent.
+- Some scripts in the repo assume specific local paths/shell conventions and may need environment-specific adjustment.
---
-# ⭐ Support Us
-Please cite this work as:
-```
-Mingtian Zhang, Yu Tang and PageIndex Team,
-"PageIndex: Next-Generation Vectorless, Reasoning-based RAG",
-PageIndex Blog, Sep 2025.
+## 🗂️ Project Layout
+
+```text
+PageIndexOllama/
+├── cli.py
+├── run_comprehensive_e2e_tests.py
+├── pageindex/
+│ ├── page_index.py
+│ ├── page_index_md.py
+│ ├── utils.py
+│ ├── response_handlers.py
+│ ├── continuation.py
+│ ├── credentials.py
+│ ├── models.py
+│ ├── chunking_config.py
+│ ├── prompt_loader.py
+│ └── prompts/
+├── scripts/
+│ ├── setup_ollama.sh
+│ └── setup_ollama.ps1
+├── tests/
+│ ├── e2e/
+│ ├── pdfs/
+│ └── results/
+└── requirements.txt
```
-Or use the BibTeX citation:
+---
-```
-@article{zhang2025pageindex,
- author = {Mingtian Zhang and Yu Tang and PageIndex Team},
- title = {PageIndex: Next-Generation Vectorless, Reasoning-based RAG},
- journal = {PageIndex Blog},
- year = {2025},
- month = {September},
- note = {https://pageindex.ai/blog/pageindex-intro},
-}
-```
+## 🔗 Relationship to Official PageIndex
-Leave us a star 🌟 if you like our project. Thank you!
+This repository is an **independent fork**.
-
-
-