注:阅读本文需要基础的强化学习知识,如了解环境、动作、奖励等基本概念。
(你最好也学过一些本文的相关内容)
目标:最大化任意 trajectory 的 return 的期望。
- trajectory 的概率,主要取决于:
- policy 选择 action
- 状态转移
$ p_\theta(\tau) = p(s_1)p_\theta(a_1|s_1)p(s_2|s_1, a_1)p_\theta(a_2|s_2)p(s_3|s_2, a_2) \cdots \ = p(s_1) \prod_{t=1}^{T} p_\theta(a_t|s_t) p(s_{t+1}|s_t, a_t) $
- return的期望=每条trajectory的return * 每条trajectory的概率
$ \bar{R}\theta = \sum\tau R(\tau)p_\theta(\tau) $
- 由于需要最大化 return 的期望,因此可以使用梯度上升来更新 policy
$ \nabla \bar{R}\theta = \sum\tau R(\tau) \nabla p_\theta(\tau) \ = \sum_\tau R(\tau) p_\theta(\tau) \frac{\nabla p_\theta(\tau)}{p_\theta(\tau)} \ = \sum_\tau R(\tau) p_\theta(\tau) \nabla \log p_\theta(\tau) $
前两项可以视为 return 的期望,等价于抽样 N 条 trajectory,计算 return 的均值
$ \nabla \bar{R}\theta = \sum\tau R(\tau) \nabla p_\theta(\tau) \ = \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} R(\tau^n) \nabla \log p_\theta(\tau) $
如何计算 log 项?连乘取 log 后变为连加,最终只与包含 policy 的一项有关
$ p_\theta(\tau) = p(s_1)p_\theta(a_1|s_1)p(s_2|s_1, a_1)p_\theta(a_2|s_2)p(s_3|s_2, a_2) \cdots \ = p(s_1) \prod_{t=1}^{T} p_\theta(a_t|s_t) p(s_{t+1}|s_t, a_t) $
$ \nabla \log p_\theta(\tau) = \nabla \left( \log p(s_1) + \sum_{t=1}^{T} \log p_\theta(a_t|s_t) + \sum_{t=1}^{T} \log p(s_{t+1}|s_t, a_t) \right) \ = \nabla \log p(s_1) + \nabla \sum_{t=1}^{T} \log p_\theta(a_t|s_t) + \nabla \sum_{t=1}^{T} \log p(s_{t+1}|s_t, a_t) \ = \nabla \sum_{t=1}^{T} \log p_\theta(a_t|s_t) \ = \sum_{t=1}^{T} \nabla \log p_\theta(a_t|s_t) $
最终结果
$ \nabla \bar{R}\theta = \frac{1}{N} \sum{n=1}^{N} \sum_{t=1}^{T_n} R(\tau^n) \nabla \log p_\theta(a_t^n | s_t^n) $
- 定义 loss
$ loss = -\frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} R(\tau^n) \log p_\theta(a_t^n | s_t^n) $
训练时:$ \theta_{new}=\theta_{old}-lr*(loss对\theta的梯度)=\theta_{old}+lr*\nabla \bar{R}_\theta $
直观理解:如果一个 trajectory 的 return 为正,就强化这个 trajectory 中每个 state 采取对应 action 的概率
- on policy
策略梯度收集多个 trajectory,更新 policy,循环往复。(收集数据的 policy 和待更新的 policy 是同一个,称为 on policy)
缺点:采集数据时间较长,训练较慢。
- 改进 return
- 问题 1: 当前 state 做出的 action 应该只影响以后的 reward(而不是整条 trajectory 的 return),同时影响应该逐渐衰减。
- 修改方案:将return修改为当前时间步到结束的reward之和,并引入逐渐衰减的权重
- 问题 2:可能所有 action 的 reward 都是正值,这样选择的所有 action 都会被提升,训练效果较慢,即使所有 action 的 reward 都是正值,也需要区分出它们的相对性
- 修改方案:为所有 action 的 reward 设置一个与当前 state 相关的 baseline
修改后:
$ \nabla \bar{R}\theta = \frac{1}{N} \sum{n=1}^{N} \sum_{t=1}^{T_n} (R_t^n - B(s_n^t))\nabla\log P_\theta(a_n^t|s_n^t)
- 价值函数与优势
- action value$ Q_{\theta}(s,a) $:直接使用神经网络估计出在 state
s下做出 actiona的 return 的期望 - state value$ V_{\theta}(s) $:使用神经网络估计在 state
s下的 return 的期望 - advantage$ A_{\theta}(s,a)=Q_{\theta}(s,a)-V_{\theta}(s) $:在 state
s下做出 actiona相比其他 action 的优势,可以体现出 action 间的相对性
因此将梯度替换为:
$ \nabla \bar{R}\theta = \frac{1}{N} \sum{n=1}^{N} \sum_{t=1}^{T_n} A_{\theta}(s,a)\nabla\log P_\theta(a_n^t|s_n^t) $
- 优势的推导
- 根据 immediate reward 展开 action value,并更新 advantage
$ Q_\theta(s_t, a) = r_t + \gamma * V_\theta(s_{t+1}) $
$ A_\theta(s_t, a) = r_t + \gamma * V_\theta(s_{t+1}) - V_\theta(s_t) $
- 再根据 immediate reward 将 t+1 时刻的 state value 递推一步
$ V_\theta(s_{t+1}) \approx r_{t+1} + \gamma * V_\theta(s_{t+2}) $
- 因此,advantage 可以根据不同数量的 immediate reward 进行展开
$ A_\theta^1(s_t, a) = r_t + \gamma * V_\theta(s_{t+1}) - V_\theta(s_t) $
$ A_\theta^2(s_t, a) = r_t + \gamma * r_{t+1} + \gamma^2 * V_\theta(s_{t+2}) - V_\theta(s_t) $
$
A_\theta^3(s_t, a) = r_t + \gamma * r_{t+1} + \gamma^2 * r_{t+2} + \gamma^3V_\theta(s_{t+3}) - V_\theta(s_t) \ \vdots $
$ A_\theta^T(s_t, a) = r_t + \gamma * r_{t+1} + \gamma^2 * r_{t+2} + \gamma^3 * r_{t+3} + \cdot + \gamma^T * r_T - V_\theta(s_t) $
影响:采样越少,可能越偏离真实情况,偏差越大,方差小;采样步数越多,越接近真实值,偏差越小,数据为真实值,方差较大。
- GAE 函数,对所有时间步的结果都进行采样,并分配权重,均衡偏差与方差
$ A_\theta^{GAE}(s_t, a) = (1 - \lambda)(A_\theta^1 + \lambda * A_\theta^2 + \lambda^2 A_\theta^3 + \cdots) $
因此将梯度替换为:
$ \nabla \bar{R}\theta = \frac{1}{N} \sum{n=1}^{N} \sum_{t=1}^{T_n} A_\theta^{GAE}(s^t_n, a^t_n)\nabla\log P_\theta(a_n^t|s_n^t) $
- 训练 state value 网络
与 policy 共享权重,policy 最后一层输出 action 的概率分布,而 state value 网络最后一层输出一个值作为 state value 即可,label 是当前 state 到结束时的 reward 之和
- on policy 与 off policy
on policy:使用 policy 采集数据,更新 policy (同一个 policy)
off policy:使用参考 policy 采集数据,来更新需要训练的 policy
- 重要性采样
$ E(f(x)){x \sim p(x)} = \sum{x} f(x) * p(x) \ = \sum_{x} f(x) * p(x) \frac{q(x)}{q(x)} \ = \sum_{x} f(x) \frac{p(x)}{q(x)} * q(x) \ = E\left(f(x) \frac{p(x)}{q(x)}\right){x \sim q(x)} \ \approx \frac{1}{N} \sum{n=1}^{N} f(x) \frac{p(x)}{q(x)}_{x \sim q(x)} $
要求f(x)在分布p(x)下的期望,可以转化为f(x)p(x)/q(x)在分布q(x)下的期望,并转化为采样 N 条记录的均值
可以将上述思想替换到策略梯度中:p(x)为原 policy$
P_\theta(a_n^t|s_n^t) $,q(x)为用于收集数据的参考 policy$
P_{\theta'}(a_n^t|s_n^t) $,则梯度替换为:
$ \nabla \bar{R}\theta = \frac{1}{N} \sum{n=1}^{N} \sum_{t=1}^{T_n} A_\theta^{GAE}(s^t_n, a^t_n)\nabla\log P_\theta(a_n^t|s_n^t) \ = \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} A_{\theta'}^{GAE}(s_n^t, a_n^t) \frac{P_\theta(a_n^t|s_n^t)}{P_{\theta'}(a_n^t|s_n^t)}\nabla\log P_\theta(a_n^t|s_n^t) $
展开 log 项可得
$ = \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} A_{\theta'}^{GAE}(s_n^t, a_n^t) \frac{P_\theta(a_n^t|s_n^t)}{P_{\theta'}(a_n^t|s_n^t)}\frac{\nabla P_\theta(a_n^t|s_n^t)}{P_\theta(a_n^t|s_n^t)} \ = \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} A_{\theta'}^{GAE}(s_n^t, a_n^t) \frac{\nabla P_\theta(a_n^t|s_n^t)}{P_{\theta'}(a_n^t|s_n^t)} $
最后的 loss 表示为
$ loss=- \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} A_{\theta'}^{GAE}(s_n^t, a_n^t) \frac{\nabla P_\theta(a_n^t|s_n^t)}{P_{\theta'}(a_n^t|s_n^t)} $
另一种理解方式:如果 advantage 为正,并且$ {P_{\theta'}(a_n^t|s_n^t)}
- 两个分布的差距不能过大
- kl 散度约束
$ loss_1=- \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} A_{\theta'}^{GAE}(s_n^t, a_n^t) \frac{\nabla P_\theta(a_n^t|s_n^t)}{P_{\theta'}(a_n^t|s_n^t)}+\beta kl(P_{\theta'},P_{\theta}) $
- 截断过大的更新
$ Loss_{2} = -\frac{1}{N}\sum_{n=1}^{N}\sum_{t=1}^{T_n} min(A_{\theta'}^{GAE}(S_n^t, a_n^t)\frac{P_{\theta}(a_n^t|S_n^t)}{P_{\theta'}(a_n^t|S_n^t)}, clip(\frac{P_{\theta}(a_n^t|S_n^t)}{P_{\theta'}(a_n^t|S_n^t)}, 1-\epsilon, 1+\epsilon)A_{\theta'}^{GAE}(S_n^t, a_n^t)) $
clip:比值在1-ε到1+ε之间,返回本身;小于返回1-ε;大于返回1+ε
LLM 的训练步骤:pretrain,sft,reward model,ppo
-
目的:输入一个问答序列,输出一个分值。可以使用 bert/LLM 类模型,更改最后一层即可,将最后一个 token 的 hidden state 作为输入。
-
训练数据-用户偏好数据:三元组
question什么是数据库?
chosen数据库是一个有组织的数据集合,允许高效的数据存储、检索和管理。
rejected数据库用于存储数据。
注:为什么不直接使用question+answer+score的数据来训练?因为不同人对同一个 answer 的好坏标准并不同。
3.loss
loss:$ -log(\frac{1}{1+e^{-x}} )
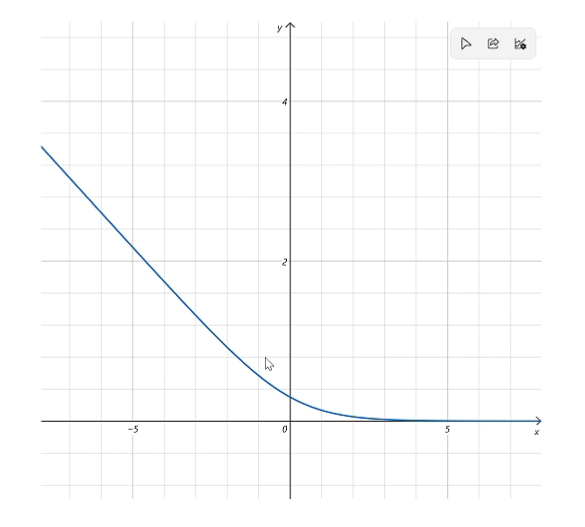
当$ chosen_{score}>rejected_{score} $时,loss 较低,反之则很高
对于 LLM,当前上下文视为 state,输出下一个 token 视为 action,LLM 本身视为 policy。
- 四个 model:
- reference model:经过 sft 后的 model,冻结,输出层为
dim*vocab - actor model:需要训练的 model,输出层为
dim*vocab - reward model:对问答进行评分,输出层为
dim*1 - state value model:计算生成每个 token 时的 state value,输出层为
dim*1,所有 token 共享
注:actor 和 state value 可以共用 model,只是输出层不同
- 流程:
- 将若干 prompt 输入 actor model,得到 response
- reward model 对 prompt+response 打出一个 score
- 将 prompt+response 传入 reference model,得到 response 中每个 token 的概率 ref_logprob
- 记录 actor model 对 response 中每个 token 的概率 old_logprob
- state value model 同时给出 response 中每个 token 的 old_value
- 计算 rewards
reward 由 ref_logprob 和 old_logprob 的 kl 散度计算,同时,最后一个 token 的 reward 需要加上 score
$ reward=score-\beta kl_loss $
- 计算 advantage
当前 token 的 action value 等于该 token 的 reward 加上下一时刻的 state value
$ return_t=reward_t+\gamma*value_{t+1} $
计算 advantage,还考虑下一个 token 的衰减 advantage(GAE)
$ advantage_t'=return_t-value_t $
$ advantage_t=advantage_t'+\gamma*\lambda*advantage_{t+1} $
- 计算 return,将实际 return 近似为 state value 加上 advantage
$ return=advantage+value $
- state value model loss
$ critic_loss=(value-return)^2 $
- actor loss
$ actor_loss=-\frac{new_ prob}{old_ prob}*advantage $
- 一次采样,每组数据训练多次
直接通过用户偏好数据训练 LLM,最大化获胜回答的奖励与落败回答的奖励之间的差距
$ \mathcal{L}{\text{DPO}}(\pi\theta; \pi_{\text{ref}}) = - \mathbb{E}{(x,y_w,y_l) \sim \mathcal{D}} \left[ \log \sigma \left( \beta \log \frac{\pi\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{\text{ref}}(y_l|x)} \right) \right] $
$ \frac{\pi_\theta(y_w|x)}{\pi_{\text{ref}}(y_w|x)} $这个比率衡量了新模型相比于旧模型,生成获胜回答的可能性提高了多少倍,后同。