diff --git a/docs/colab_notebooks/7-nemotron-personas.ipynb b/docs/colab_notebooks/7-nemotron-personas.ipynb
new file mode 100644
index 000000000..32cc898ba
--- /dev/null
+++ b/docs/colab_notebooks/7-nemotron-personas.ipynb
@@ -0,0 +1,1071 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "40d84353",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "092d9fb9",
+ "metadata": {},
+ "source": [
+ "# 👥 Data Designer Tutorial: Reproducing & Customizing Nemotron-Personas\n",
+ "\n",
+ "This notebook reproduces the [Nemotron-Personas-USA](https://huggingface.co/datasets/nvidia/Nemotron-Personas-USA) generation pipeline end to end with [🎨 NeMo Data Designer](https://github.com/NVIDIA-NeMo/DataDesigner), and then shows how to customize that pipeline to generate personas for a specific use case. A similar approach was used to build every dataset in the [Nemotron-Personas HF collection](https://huggingface.co/collections/nvidia/nemotron-personas).\n",
+ "\n",
+ "We seed the pipeline with the **extended Nemotron-Personas-USA dataset on NGC**, which is a superset of the publicly released HuggingFace version — it includes additional demographic and persona fields used internally to ground synthetic generation. From those grounded seeds, two stages of LLM structured-output columns produce the persona attributes (cultural background, skills, career goals, hobbies) and the persona descriptions across professional, financial, healthcare, sports, arts, travel, and culinary dimensions.\n",
+ "\n",
+ "> ⚠️ **Note**: To run this notebook, follow the setup instructions in the [Quick Start](https://nvidia-nemo.github.io/DataDesigner/quick-start/), make sure you have generated an API key for accessing models on [build.nvidia.com](https://build.nvidia.com), and that you've set the `NVIDIA_API_KEY` environment variable. The next section also walks through downloading the NGC-hosted Nemotron-Personas dataset.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "092d9fb9",
+ "metadata": {},
+ "source": [
+ "# 👥 Data Designer Tutorial: Reproducing & Customizing Nemotron-Personas\n",
+ "\n",
+ "This notebook reproduces the [Nemotron-Personas-USA](https://huggingface.co/datasets/nvidia/Nemotron-Personas-USA) generation pipeline end to end with [🎨 NeMo Data Designer](https://github.com/NVIDIA-NeMo/DataDesigner), and then shows how to customize that pipeline to generate personas for a specific use case. A similar approach was used to build every dataset in the [Nemotron-Personas HF collection](https://huggingface.co/collections/nvidia/nemotron-personas).\n",
+ "\n",
+ "We seed the pipeline with the **extended Nemotron-Personas-USA dataset on NGC**, which is a superset of the publicly released HuggingFace version — it includes additional demographic and persona fields used internally to ground synthetic generation. From those grounded seeds, two stages of LLM structured-output columns produce the persona attributes (cultural background, skills, career goals, hobbies) and the persona descriptions across professional, financial, healthcare, sports, arts, travel, and culinary dimensions.\n",
+ "\n",
+ "> ⚠️ **Note**: To run this notebook, follow the setup instructions in the [Quick Start](https://nvidia-nemo.github.io/DataDesigner/quick-start/), make sure you have generated an API key for accessing models on [build.nvidia.com](https://build.nvidia.com), and that you've set the `NVIDIA_API_KEY` environment variable. The next section also walks through downloading the NGC-hosted Nemotron-Personas dataset.\n",
+ "\n",
+ "\n",
+ "

\n",
+ "
\n",
+ "See [Big Five personality traits Wikipedia article](https://en.wikipedia.org/wiki/Big_Five_personality_traits) for more context.\n",
+ "\n",
+ "In this notebook the OCEAN traits come straight from the **NGC-hosted Nemotron-Personas-USA dataset** in the next section (`with_synthetic_personas=True` exposes `person.openness`, `person.conscientiousness`, etc. as `struct`). The helper functions in Section 2 are kept ready for the `SAMPLE_FROM_SDG_PGM = True` reproduction path."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "84775cd8",
+ "metadata": {},
+ "source": [
+ "## 4.2 👩🎨👨🎨 Generate Persona Attributes\n",
+ "\n",
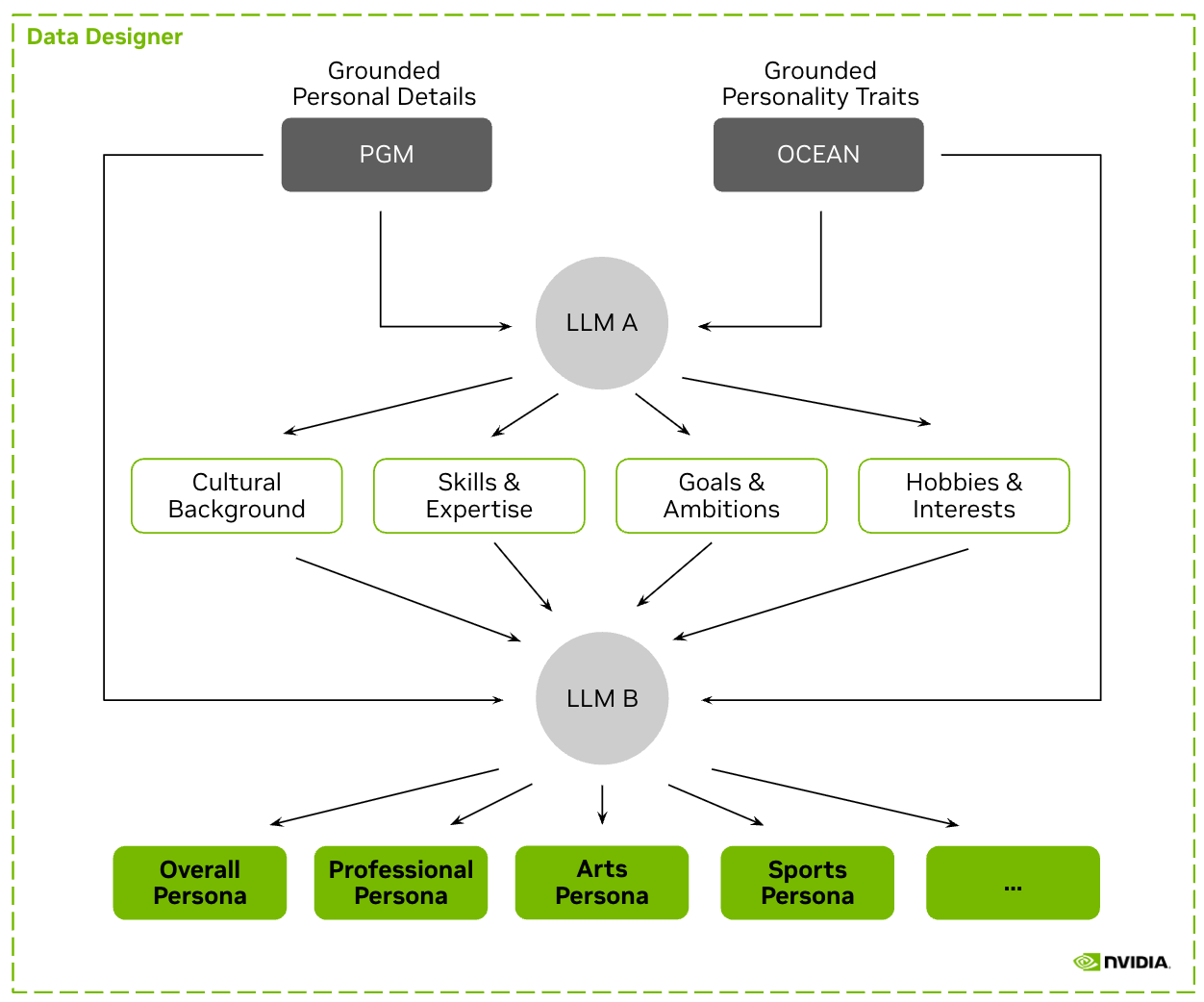
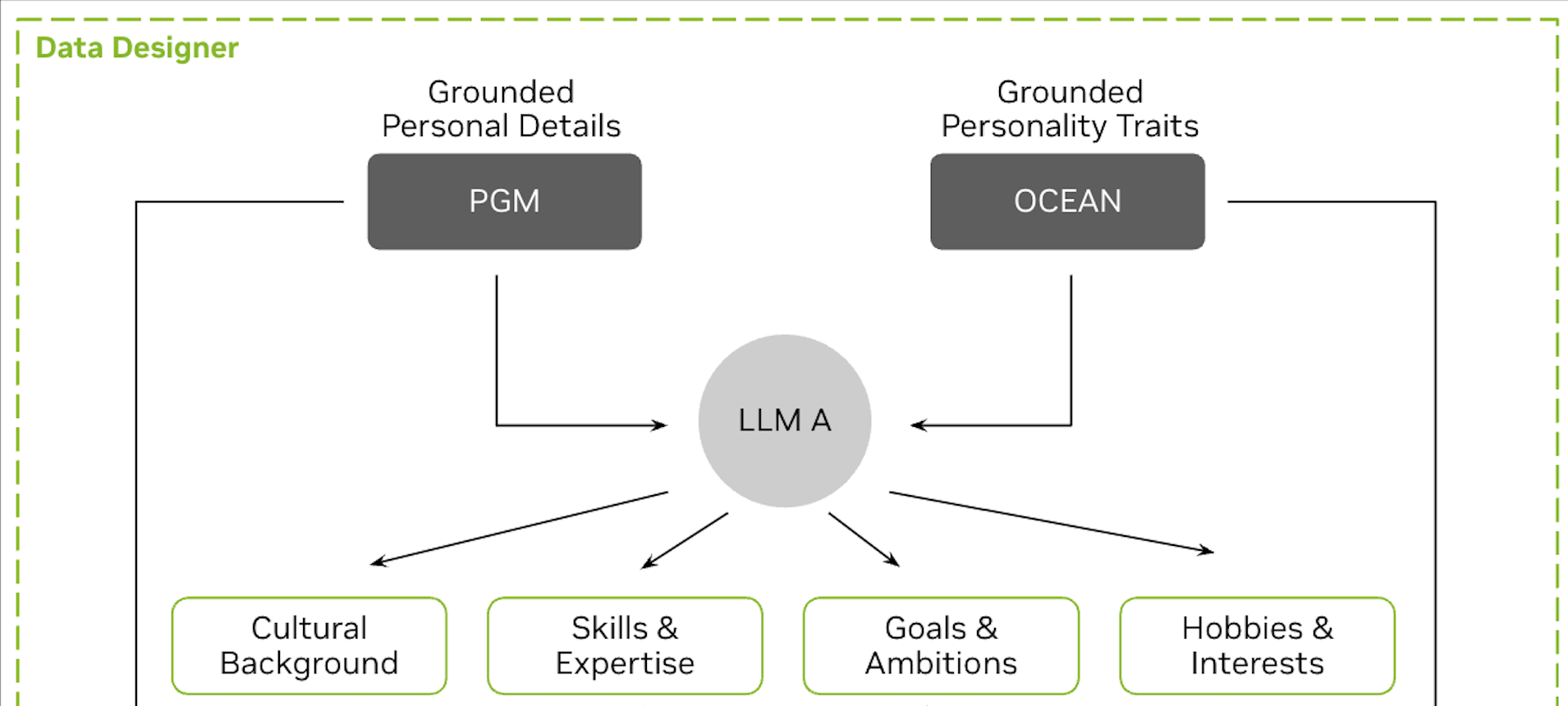
+ "We are focusing just on the part in the diagram below and seeding persona attributes with PGM + OCEAN details:\n",
+ "\n",
+ "\n",
+ "

\n",
+ "
\n",
+ "

\n",
+ "
+  +
+
+
+---
+
+## **Why grounded synthetic personas matter**
+
+It's easy to underestimate what a really good persona seed buys you. Three angles worth keeping in mind:
+
+1. **Distributional faithfulness for sovereign AI.** Models trained on synthetic data that doesn't reflect the actual demographics of a region inherit subtle biases — over-representing some groups, under-representing others, getting cultural context wrong. For sovereign-AI work, that's not a rounding error; it's the whole problem. Grounding personas in census + administrative data closes that gap before the LLM ever sees the data.
+
+2. **Diversity that random sampling can't produce.** "Generate 10,000 customer queries" with no seed and an LLM will give you 10,000 variations on the same handful of latent personas. Conditioning each query on a distinct, demographically-grounded persona forces the model to span the actual population it'll be deployed against — the conscientious 62-year-old retired electrician in Pittsburgh, the 24-year-old graduate student in Bengaluru, the elementary-school teacher in Lille. Each yields a meaningfully different prompt.
+
+3. **Reusable seed material.** Once a persona has a name, a demographic profile, an OCEAN vector, and a coherent backstory, *any* downstream pipeline can attach to it: a tool-use environment, a long-context construction, a safety-refusal template, a roleplay scenario. The collection acts as a library — generate the personas once, reuse them across training stages.
+
+That last point is the bridge to the rest of this post.
+
+---
+
+## **Nemotron-Personas inside Nemotron training**
+
+The [Nemotron 3 Super Technical Report](https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-Super-Technical-Report.pdf) shows just how foundational these personas have become. They're not a side-quest dataset; they're a *seeding primitive* used across many post-training stages.
+
+### Long-context samples
+
+Long-context training data is hard to source — you need genuinely long, coherent sequences that aren't just concatenations of unrelated documents. Persona records, by virtue of being self-contained narratives with rich attributes, concatenate cleanly:
+
+> *"We also construct long-context samples by concatenating records from [Nemotron-Personas-USA](https://huggingface.co/datasets/nvidia/Nemotron-Personas-USA) to reach the required sequence length."*
+>
+> — [Nemotron 3 Super Technical Report](https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-Super-Technical-Report.pdf)
+
+Each persona is internally coherent (the OCEAN traits inform the cultural background, which informs the career goals, which informs the professional persona, etc.), and across personas the records are independent — exactly the right shape to pack into long sequences.
+
+### General-purpose tool-use rollouts
+
+Tool-use trajectories require a *user* with a goal, not just a tool set. The Super pipeline uses a dual-LLM setup where one LLM plays the user and another plays the agent:
+
+> *"The User-LLM is seeded with the selected tool set, a persona sampled from [Nemotron-Personas-USA](https://huggingface.co/datasets/nvidia/Nemotron-Personas-USA)..."*
+>
+> — [Nemotron 3 Super Technical Report](https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-Super-Technical-Report.pdf)
+
+Seeding the user side with a real persona is what makes the rollouts feel like authentic conversations — the user's goals, communication style, and frustration patterns all flow from their underlying attributes. The agent has to handle the variance that real users actually produce, not the narrow band of "well-behaved benchmark user" prompts.
+
+A closely related approach was used to build **Nemotron-Nano-9B-v2-Japanese**, NVIDIA's Japanese small language model that ranks **#1 on the Nejumi LLM Leaderboard**. The Japanese instruction-following + general-chat data was seeded by [Nemotron-Personas-Japan](https://huggingface.co/datasets/nvidia/Nemotron-Personas-Japan), with prompts and assistant responses anchored to Japanese-grounded personas. That's the multi-locale story turning into a multi-locale model story: a Japanese persona collection, generated by a localized DD pipeline, becomes the seeding layer for a Japanese model that beats the leaderboard.
+
+The same template is being used across the family — instruction-following and general-chat data going into Nemotron Nano v3 (and from there into Super v3) follows the same persona-seeded recipe.
+
+### Synthetic formal-logic data
+
+Even abstract reasoning data benefits from persona conditioning:
+
+> *"We introduced variability into the generated scenarios, premises, and formulas by incorporating random personas, letters, and/or logic connective (i.e., ∧, ∨, ⊃, ≡, ∼) into the prompt."*
+>
+> — [Nemotron 3 Super Technical Report](https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-Super-Technical-Report.pdf)
+
+Formal-logic problems become more diverse — and more transferable — when the surface scenario shifts. A propositional-logic puzzle about an elementary teacher planning a field trip exercises the same underlying inference as one about a credit-counselor evaluating a loan, but the lexical surface looks completely different. Persona-driven scenario variation breaks the model out of the canonical "Alice and Bob" rut that plagues most synthetic formal-logic datasets.
+
+### Sensitive-safety-category-refusals (SSCR)
+
+The SSCR dataset — used in Nemotron's safety blend — leverages Nemotron-Personas as seed data when constructing prompts that require refusal across sensitive categories. Personas matter here because real-world adversarial / sensitive prompts come from all kinds of users; grounding the synthetic prompts in demographically diverse personas ensures the trained refusal behavior generalizes across user populations rather than overfitting to a narrow band of "obviously suspicious" phrasings. SSCR is included in the broader **nemotron-safety-blend**.
+
+### General chat and instruction following
+
+The same persona-seeding pattern that powers tool-use rollouts also powers the broader general-chat and instruction-following data that flows into Nemotron Nano v3 and from there into Super v3. A chat or instruction sample is a function of *who* is asking — their goals, their constraints, their communication style — and personas are how the pipeline encodes "who."
+
+---
+
+## **How they're built: a four-stage compound-AI pipeline**
+
+Across all locales, the construction pipeline is the same four-stage shape (the regional adaptations live in the seed distributions, the language of the prompts, and which locale-specific fields get added). NeMo Data Designer orchestrates the pipeline as a column DAG:
+
+
+  +
+
+
+### Stage 1 — OCEAN Big-Five sampling
+
+OCEAN ([Big Five personality traits](https://en.wikipedia.org/wiki/Big_Five_personality_traits)) is the most empirically grounded model of human personality. For each persona we sample five trait T-scores (\(\mu = 50\), \(\sigma = 10\), clipped to \([20, 80]\)), bucket each into a coarse label, and attach a prose description grounded in the personality literature. Working at the description level (rather than raw scores) is what makes the downstream LLM stages produce nuanced, internally-consistent narratives — "highly conscientious" vs "highly extraverted" reads very differently to an LLM than `t_score=72`.
+
+The score-to-label mapping is shared across all five traits:
+
+| T-score | Label |
+| :---: | :--- |
+| 20 – 34 | very low |
+| 35 – 44 | low |
+| 45 – 54 | average |
+| 55 – 64 | high |
+| 65 – 80 | very high |
+
+Each (trait, label) pair maps to a curated description that captures how that level of the trait actually manifests. A representative slice of the **openness** mapping:
+
+| Label | Description |
+| :--- | :--- |
+| very low | *"Strongly prefers routine and the familiar. Traditional in thinking and values practicality over abstract ideas."* |
+| low | *"Generally prefers structure and predictability. Tends to be practical and focused on immediate realities."* |
+| average | *"Balances curiosity with practicality. Appreciates both new ideas and established methods."* |
+| high | *"Curious and appreciative of art, new ideas, and varied experiences. Open to unconventional thinking."* |
+| very high | *"Highly imaginative and intellectually curious. Strongly drawn to novelty, art, and abstract concepts."* |
+
+The other four traits each have their own 5-row description table tuned to their domain (conscientiousness around organization vs spontaneity, extraversion around social energy, agreeableness around cooperation, neuroticism around emotional reactivity). The result is that one sampled persona arrives at Stage 3 with a structured personality block:
+
+```python
+{
+ "openness": {"t_score": 67, "label": "high", "description": "Curious and appreciative of art..."},
+ "conscientiousness": {"t_score": 72, "label": "very high", "description": "Exceptionally organized..."},
+ "extraversion": {"t_score": 41, "label": "low", "description": "Generally reserved..."},
+ "agreeableness": {"t_score": 55, "label": "average", "description": "Generally cooperative..."},
+ "neuroticism": {"t_score": 38, "label": "low", "description": "Emotionally stable..."},
+}
+```
+
+…which the downstream LLM prompts reference directly via Jinja templates:
+
+```jinja
+Personality profile:
+- {{ openness.description }}
+- {{ conscientiousness.description }}
+- {{ extraversion.description }}
+- {{ agreeableness.description }}
+- {{ neuroticism.description }}
+```
+
+### Stage 2 — Demographically-grounded sampling
+
+This is the engine of regional fidelity. For each locale, the goal is to produce a demographic record whose attributes correlate with each other the way real populations do — age × education × occupation × marital status × geography, with locale-specific extensions. Naive independent sampling produces nonsensical records (3-year-old surgeon married for 30 years living alone in Singapore); the released artifact pulls from [Probabilistic Graphical Models](https://en.wikipedia.org/wiki/Graphical_model) trained on real statistical distributions (census tables, administrative records, public surveys) so the correlations are statistically faithful.
+
+**The simplest path to seed your own pipeline today** is to consume the released NGC-hosted Nemotron-Personas dataset directly via Data Designer's built-in `PersonSampler`. This gives you the full demographic + OCEAN block from a verified PGM-grounded source without rebuilding anything yourself. One `SamplerColumnConfig` is enough:
+
+```python
+import data_designer.config as dd
+
+config_builder.add_column(
+ dd.SamplerColumnConfig(
+ name="person",
+ sampler_type=dd.SamplerType.PERSON,
+ params=dd.PersonSamplerParams(
+ locale="en_US", # or ja_JP, en_IN, fr_FR, ko_KR, pt_BR, en_SG, hi_Deva_IN, hi_Latn_IN
+ age_range=[18, 114],
+ with_synthetic_personas=True, # exposes Big Five + cultural background + hobbies + career_goals + ...
+ ),
+ drop=True,
+ )
+)
+```
+
+`{{ person.openness.description }}`, `{{ person.occupation }}`, `{{ person.county }}` all become available to downstream Jinja templates immediately. See the [Person Sampling docs](https://nvidia-nemo.github.io/DataDesigner/latest/concepts/person_sampling/) for the full setup walkthrough (NGC API key + `data-designer download personas --locale en_US`).
+
+**For new locales without a released artifact — or for teams that need full control over the demographic distributions** — the underlying engine, **SDG-PGMs**, was just open-sourced as [NVIDIA-NeMo/SDG-PGMs](https://github.com/NVIDIA-NeMo/SDG-PGMs). Its README states the connection plainly:
+
+> *"Together with Data Designer, SDG-PGMs helps power the Nemotron-Personas HF collection — multilingual, region-specific synthetic persona datasets for sovereign AI development. The USA dataset alone contains 6M personas grounded in US Census data, with realistic demographic correlations across age, sex, geography, education, marital status, and 560+ occupations."*
+
+A first-class Data Designer plugin (`PGMGeneratorPluginConfig`) is **coming soon**. The eventual integration shape:
+
+```python
+# Coming soon — full Data Designer integration for custom PGMs:
+from data_designer_plugins.pgm_generator_plugin import PGMGeneratorPluginConfig
+
+config_builder.add_column(
+ PGMGeneratorPluginConfig(
+ name="person",
+ generator_class="my_generators.UsPersonGenerator",
+ )
+)
+```
+
+Until that lands, SDG-PGMs can be run standalone (output → seed parquet → `dd.LocalFileSeedSource`) to feed any Data Designer pipeline. Either way, Stage 2 produces a consistent demographic record per persona; the locale-specific fields (France's `name_heritage`, Korea's military/health indicators, India's multi-language stack, etc.) are layered in here, sourced from the relevant regional statistical bodies.
+
+### Stage 3 — Persona attributes via structured outputs
+
+With OCEAN traits and demographic grounding in hand, the pipeline calls a reasoning LLM with a single `LLMStructuredColumnConfig` that materializes six rich attribute fields in one shot via a Pydantic schema:
+
+
+  +
+
+
+```python
+from pydantic import BaseModel, Field
+
+
+class PersonaAttributes(BaseModel):
+ cultural_background: str = Field(description="Description of the person's cultural background")
+ skills_and_expertise: str = Field(description="Description of the person's skills and expertise")
+ skills_and_expertise_list: list[str] = Field(description="List of the person's skills and expertise")
+ career_goals_and_ambitions: str = Field(description="Description of the person's career goals and ambitions")
+ hobbies_and_interests: str = Field(description="Description of the person's hobbies and interests")
+ hobbies_and_interests_list: list[str] = Field(description="List of the person's hobbies and interests")
+
+
+config_builder.add_column(
+ dd.LLMStructuredColumnConfig(
+ name="persona_attributes",
+ system_prompt=PERSONA_ATTRIBUTES_SYSTEM_PROMPT,
+ prompt="""\
+Based on a person with the following profile:
+
+Name: {{ first_name }} {{ middle_name if middle_name else '' }} {{ last_name }}
+Age: {{ age }}, Sex: {{ sex }}, Occupation: {{ occupation }}
+Location: {{ city }}, {{ state }}, {{ county }}
+
+Personality profile:
+- {{ openness.description }}
+- {{ conscientiousness.description }}
+- {{ extraversion.description }}
+- {{ agreeableness.description }}
+- {{ neuroticism.description }}
+
+Generate the cultural_background, skills_and_expertise, career_goals_and_ambitions, and hobbies_and_interests fields.
+""",
+ output_format=PersonaAttributes,
+ model_alias=MODEL_ALIAS,
+ drop=True,
+ )
+)
+```
+
+The system prompt forces internal consistency ("attributes that are internally consistent and logically connected to the base persona details"), cultural sensitivity ("avoid stereotypes while acknowledging cultural influences"), and specificity ("create specific, detailed responses rather than generic ones"). Pydantic schema enforcement means every record's attributes parse cleanly downstream.
+
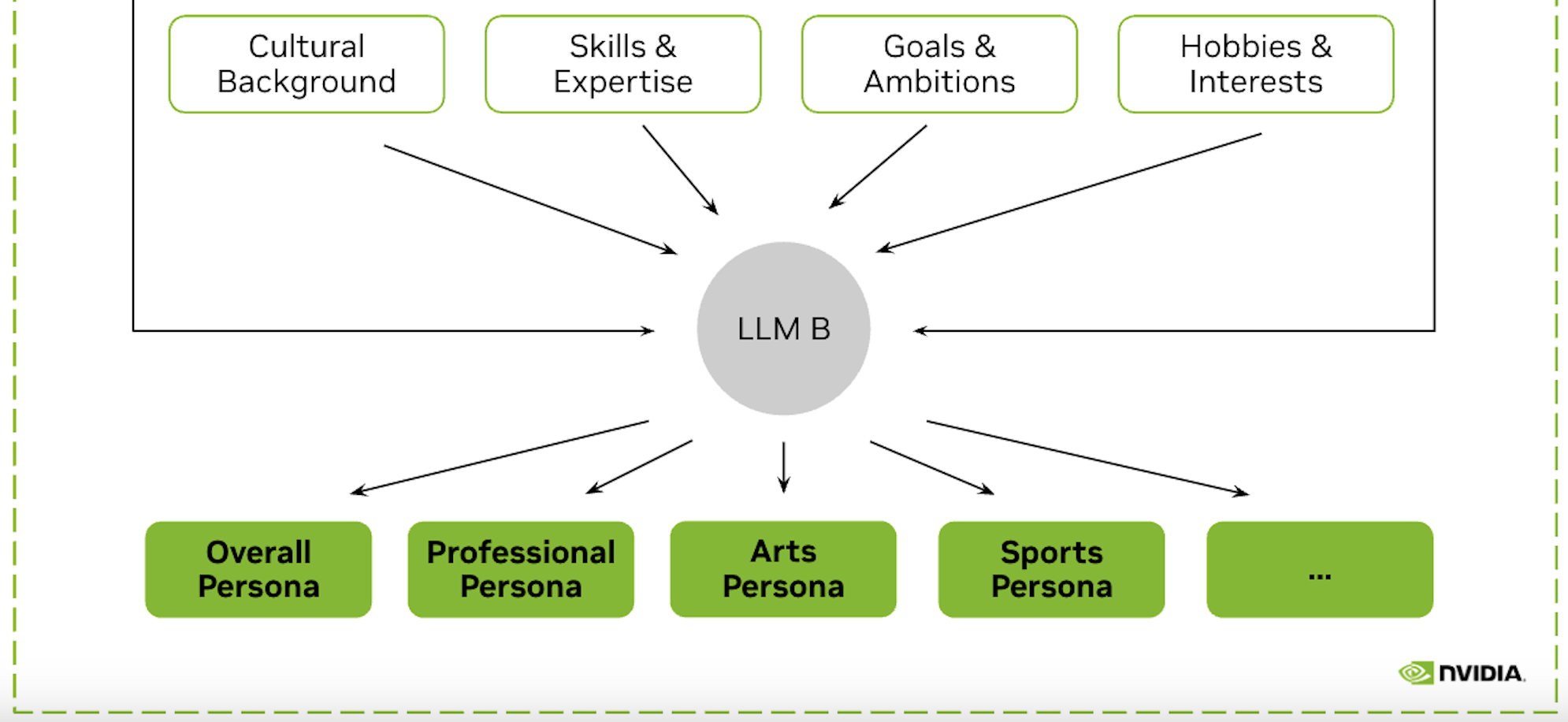
+### Stage 4 — Persona descriptions
+
+The final stage is a second structured-output LLM call that synthesizes everything above into nine cohesive persona descriptions: `professional_persona`, `finance_persona`, `healthcare_persona`, `sports_persona`, `arts_persona`, `travel_persona`, `culinary_persona`, `concise_persona`, and a paragraph-length `detailed_persona`.
+
+
+  +
+
+
+```python
+class Personas(BaseModel):
+ professional_persona: str = Field(description="...primary field of work, key professional skills...")
+ finance_persona: str = Field(description="...spending habits, relationship with money...")
+ healthcare_persona: str = Field(description="...specific health conditions, patient behavior...")
+ sports_persona: str = Field(description="...athletic interests, fitness approach, specific teams...")
+ arts_persona: str = Field(description="...engagement with creative expression, specific artists...")
+ travel_persona: str = Field(description="...travel interests, planning style, specific destinations...")
+ culinary_persona: str = Field(description="...food preferences, specific dishes and ingredients...")
+ concise_persona: str = Field(description="One-sentence essence of the person, including quirks.")
+ detailed_persona: str = Field(description="Paragraph-length descriptive narrative.")
+
+
+config_builder.add_column(
+ dd.LLMStructuredColumnConfig(
+ name="personas",
+ system_prompt=PERSONA_SYSTEM_PROMPT,
+ prompt="""\
+Based on a person with the following persona attributes and profile:
+
+Age: {{ age }}
+Cultural background: {{ cultural_background }}
+Hobbies and interests: {{ hobbies_and_interests }}
+Skills and expertise: {{ skills_and_expertise }}
+Career goals and ambitions: {{ career_goals_and_ambitions }}
+
+Personality profile:
+- {{ openness.description }}
+- ...
+
+Generate self-contained persona descriptions per the schema.
+""",
+ output_format=Personas,
+ model_alias=MODEL_ALIAS,
+ drop=True,
+ )
+)
+```
+
+The system prompt contains explicit guardrails: include the name in every description, never directly mention cultural heritage (infuse it implicitly through practices and traditions), and always take age into account. The LLM does the synthesis; Pydantic does the validation; Data Designer's DAG executes the whole thing in parallel across millions of records.
+
+---
+
+## **Building your own — the customization story**
+
+The released artifact is the *general-purpose* collection. In practice, every team that uses these personas downstream extends them in some way. NeMo Data Designer makes that trivial: the same `LLMStructuredColumnConfig` + `ExpressionColumnConfig` pattern that builds the released schema can be used to layer on any custom dimension you need.
+
+The accompanying [Data Designer Tutorial: Reproducing & Customizing Nemotron-Personas](#try-it-yourself) walks through a concrete example. After reproducing the released schema with a `PersonSampler` against the NGC-hosted dataset, the tutorial adds a custom `tech_persona` dimension with two new fields — a prose description of the persona's relationship with technology, plus a list of specific tech tools they use:
+
+```python
+import data_designer.config as dd
+from pydantic import BaseModel, Field
+
+
+class TechPersona(BaseModel):
+ tech_persona: str = Field(
+ description=(
+ "A 2-3 sentence description of this person's relationship with technology: "
+ "comfort with AI/digital tools, level of tech adoption, preferred devices, "
+ "and one specific way technology shapes their daily routine."
+ )
+ )
+ tech_tools: list[str] = Field(
+ description=(
+ "List of 4-6 specific tech tools, apps, services, or devices this person uses regularly. "
+ "Each entry should be a concrete named product, not a generic category."
+ )
+ )
+
+
+config_builder.add_column(
+ dd.LLMStructuredColumnConfig(
+ name="custom_persona",
+ system_prompt=(
+ "You write nuanced, specific tech-relationship personas grounded in demographic "
+ "and psychometric attributes. Avoid generic platitudes; ground every claim in the "
+ "person's age, occupation, personality, and lifestyle."
+ ),
+ prompt="""\
+Based on a person with the following persona profile:
+
+Name: {{ first_name }} {{ last_name }}, Age: {{ age }}, Occupation: {{ occupation }}
+Cultural background: {{ cultural_background }}
+Career goals: {{ career_goals_and_ambitions }}
+Hobbies: {{ hobbies_and_interests }}
+
+Personality profile:
+- {{ openness.description }}
+- {{ conscientiousness.description }}
+- {{ extraversion.description }}
+- {{ agreeableness.description }}
+- {{ neuroticism.description }}
+
+Generate the `tech_persona` and `tech_tools` fields per the schema.
+""",
+ output_format=TechPersona,
+ model_alias=MODEL_ALIAS,
+ drop=True,
+ )
+)
+
+config_builder.add_column(dd.ExpressionColumnConfig(name="tech_persona", expr="{{ custom_persona.tech_persona }}"))
+config_builder.add_column(dd.ExpressionColumnConfig(name="tech_tools", expr="{{ custom_persona.tech_tools }}"))
+```
+
+A representative output from the tutorial run:
+
+```text
+tech_persona Megan pragmatically adopts mainstream tech, seamlessly weaving AI assistants
+ into her lesson planning while preferring her well-worn iPad over flashier
+ gadgets; technology shapes her workflow most when she's grading assignments
+ on Sunday evenings.
+tech_tools ['MacBook Air', 'iPad Pro 12.9', 'iPhone 14', 'Google Classroom',
+ 'Microsoft OneNote', 'ChatGPT']
+```
+
+That's it — a few lines of Pydantic + one LLM column + a couple of expression columns and the released schema picks up two brand-new domain-specific fields. The same pattern scales: a healthcare provider extends with `medical_history_persona` and `insurance_persona`; a media company extends with `media_consumption_persona` and `subscription_stack`; a financial-services team extends with `investment_persona` and `risk_tolerance_persona`. The PGM-grounded base record stays the seed; everything else is one schema away.
+
+### Going deeper: build a brand-new locale
+
+For locales without an NGC-hosted Nemotron-Personas dataset, the build path is open. The OCEAN Big-Five helpers ship in the tutorial repo (Stage 1 of the original pipeline), and [NeMo SDG-PGMs](https://github.com/NVIDIA-NeMo/SDG-PGMs) provides the framework for building your own demographic PGM (Stage 2) — collect aggregate statistical distributions, declare a `PGMGenerator` subclass, and drop it into Data Designer via the bundled `PGMGeneratorPluginConfig`. The downstream LLM stages (3 and 4) are locale-agnostic; they just need the right language in the prompts. The tutorial leaves a `SAMPLE_FROM_SDG_PGM = True` toggle in place as the integration point.
+
+---
+
+## **Try it yourself**
+
+The full reproduction-and-customization tutorial covers every detail in this post end-to-end, from the NGC dataset bootstrap through the toy custom-persona example.
+
+ +
+- **Tutorial notebook:** [Reproducing & Customizing Nemotron-Personas](../../notebooks/7-nemotron-personas.ipynb) — runs locally end-to-end; takes ~5 min on `gpt-oss-20b` for a 5-record smoke run.
+- **Colab:** click the badge above to launch the same notebook on Colab. The injected setup cells handle the `NVIDIA_API_KEY` / `NGC_API_KEY` ceremony from Colab Secrets and install the NGC CLI before the persona dataset download.
+- **NGC dataset setup (local):** see the [Person Sampling docs](https://nvidia-nemo.github.io/DataDesigner/latest/concepts/person_sampling/) for the full walkthrough (NGC API key + NGC CLI + `data-designer download personas --locale en_US`).
+
+Switching locales is a one-liner: change `personas_locale = "en_US"` to any of `en_IN`, `en_SG`, `fr_FR`, `hi_Deva_IN`, `hi_Latn_IN`, `ja_JP`, `ko_KR`, `pt_BR` and re-run the download cell. Everything downstream stays the same.
+
+---
+
+## **Closing thoughts**
+
+The headline number on the [Nemotron-Personas HF collection](https://huggingface.co/collections/nvidia/nemotron-personas) is the persona count, but the real story is that **a single, modular, locale-adaptable pipeline produces seed material that recurs throughout Nemotron's training stack**. Long-context construction, tool-use rollouts, formal-logic variability, safety refusals, instruction-following data — all of them lean on the same underlying primitive. That's the compound-AI bet paying off: build the right primitive once, and many downstream pipelines stop being one-off projects.
+
+If you're building region-specific synthetic data for your own model, the path is clear: take a locale's released artifact, layer your domain-specific dimensions on top with a few lines of Data Designer config, and you have a custom dataset that inherits all the demographic grounding the original artifact carries.
+
+---
+
+**Key Resources:**
+
+- **Nemotron-Personas HF collection:** [huggingface.co/collections/nvidia/nemotron-personas](https://huggingface.co/collections/nvidia/nemotron-personas)
+- **NeMo Data Designer:** [github.com/NVIDIA-NeMo/DataDesigner](https://github.com/NVIDIA-NeMo/DataDesigner)
+- **NeMo SDG-PGMs:** [github.com/NVIDIA-NeMo/SDG-PGMs](https://github.com/NVIDIA-NeMo/SDG-PGMs)
+- **Nemotron 3 Super Technical Report:** [research.nvidia.com/labs/nemotron/.../NVIDIA-Nemotron-3-Super-Technical-Report.pdf](https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-Super-Technical-Report.pdf)
+- **Person Sampling in Data Designer:** [nvidia-nemo.github.io/DataDesigner/.../person_sampling](https://nvidia-nemo.github.io/DataDesigner/latest/concepts/person_sampling/)
+- **Related dev notes:** [Designing Data Designer: Why SDG Is a Systems Problem](design-principles.md), [Engineering an Enterprise-Grade Text-to-SQL Dataset](text-to-sql.md), [Push Datasets to Hugging Face Hub](push-datasets-to-hugging-face-hub.md)
+
+---
+
+*Want to learn more about NeMo Data Designer? Check out our [documentation](https://nvidia-nemo.github.io/DataDesigner/) and start building your own region-specific synthetic persona datasets today.*
diff --git a/docs/notebook_source/7-nemotron-personas.py b/docs/notebook_source/7-nemotron-personas.py
new file mode 100644
index 000000000..ce9ce175c
--- /dev/null
+++ b/docs/notebook_source/7-nemotron-personas.py
@@ -0,0 +1,708 @@
+# ---
+# jupyter:
+# jupytext:
+# text_representation:
+# extension: .py
+# format_name: percent
+# format_version: '1.3'
+# jupytext_version: 1.18.1
+# kernelspec:
+# display_name: .venv
+# language: python
+# name: python3
+# ---
+
+# %% [markdown]
+# # 👥 Data Designer Tutorial: Reproducing & Customizing Nemotron-Personas
+#
+# This notebook reproduces the [Nemotron-Personas-USA](https://huggingface.co/datasets/nvidia/Nemotron-Personas-USA) generation pipeline end to end with [🎨 NeMo Data Designer](https://github.com/NVIDIA-NeMo/DataDesigner), and then shows how to customize that pipeline to generate personas for a specific use case. A similar approach was used to build every dataset in the [Nemotron-Personas HF collection](https://huggingface.co/collections/nvidia/nemotron-personas).
+#
+# We seed the pipeline with the **extended Nemotron-Personas-USA dataset on NGC**, which is a superset of the publicly released HuggingFace version — it includes additional demographic and persona fields used internally to ground synthetic generation. From those grounded seeds, two stages of LLM structured-output columns produce the persona attributes (cultural background, skills, career goals, hobbies) and the persona descriptions across professional, financial, healthcare, sports, arts, travel, and culinary dimensions.
+#
+# > ⚠️ **Note**: To run this notebook, follow the setup instructions in the [Quick Start](https://nvidia-nemo.github.io/DataDesigner/quick-start/), make sure you have generated an API key for accessing models on [build.nvidia.com](https://build.nvidia.com), and that you've set the `NVIDIA_API_KEY` environment variable. The next section also walks through downloading the NGC-hosted Nemotron-Personas dataset.
+#
+#
+
+- **Tutorial notebook:** [Reproducing & Customizing Nemotron-Personas](../../notebooks/7-nemotron-personas.ipynb) — runs locally end-to-end; takes ~5 min on `gpt-oss-20b` for a 5-record smoke run.
+- **Colab:** click the badge above to launch the same notebook on Colab. The injected setup cells handle the `NVIDIA_API_KEY` / `NGC_API_KEY` ceremony from Colab Secrets and install the NGC CLI before the persona dataset download.
+- **NGC dataset setup (local):** see the [Person Sampling docs](https://nvidia-nemo.github.io/DataDesigner/latest/concepts/person_sampling/) for the full walkthrough (NGC API key + NGC CLI + `data-designer download personas --locale en_US`).
+
+Switching locales is a one-liner: change `personas_locale = "en_US"` to any of `en_IN`, `en_SG`, `fr_FR`, `hi_Deva_IN`, `hi_Latn_IN`, `ja_JP`, `ko_KR`, `pt_BR` and re-run the download cell. Everything downstream stays the same.
+
+---
+
+## **Closing thoughts**
+
+The headline number on the [Nemotron-Personas HF collection](https://huggingface.co/collections/nvidia/nemotron-personas) is the persona count, but the real story is that **a single, modular, locale-adaptable pipeline produces seed material that recurs throughout Nemotron's training stack**. Long-context construction, tool-use rollouts, formal-logic variability, safety refusals, instruction-following data — all of them lean on the same underlying primitive. That's the compound-AI bet paying off: build the right primitive once, and many downstream pipelines stop being one-off projects.
+
+If you're building region-specific synthetic data for your own model, the path is clear: take a locale's released artifact, layer your domain-specific dimensions on top with a few lines of Data Designer config, and you have a custom dataset that inherits all the demographic grounding the original artifact carries.
+
+---
+
+**Key Resources:**
+
+- **Nemotron-Personas HF collection:** [huggingface.co/collections/nvidia/nemotron-personas](https://huggingface.co/collections/nvidia/nemotron-personas)
+- **NeMo Data Designer:** [github.com/NVIDIA-NeMo/DataDesigner](https://github.com/NVIDIA-NeMo/DataDesigner)
+- **NeMo SDG-PGMs:** [github.com/NVIDIA-NeMo/SDG-PGMs](https://github.com/NVIDIA-NeMo/SDG-PGMs)
+- **Nemotron 3 Super Technical Report:** [research.nvidia.com/labs/nemotron/.../NVIDIA-Nemotron-3-Super-Technical-Report.pdf](https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-Super-Technical-Report.pdf)
+- **Person Sampling in Data Designer:** [nvidia-nemo.github.io/DataDesigner/.../person_sampling](https://nvidia-nemo.github.io/DataDesigner/latest/concepts/person_sampling/)
+- **Related dev notes:** [Designing Data Designer: Why SDG Is a Systems Problem](design-principles.md), [Engineering an Enterprise-Grade Text-to-SQL Dataset](text-to-sql.md), [Push Datasets to Hugging Face Hub](push-datasets-to-hugging-face-hub.md)
+
+---
+
+*Want to learn more about NeMo Data Designer? Check out our [documentation](https://nvidia-nemo.github.io/DataDesigner/) and start building your own region-specific synthetic persona datasets today.*
diff --git a/docs/notebook_source/7-nemotron-personas.py b/docs/notebook_source/7-nemotron-personas.py
new file mode 100644
index 000000000..ce9ce175c
--- /dev/null
+++ b/docs/notebook_source/7-nemotron-personas.py
@@ -0,0 +1,708 @@
+# ---
+# jupyter:
+# jupytext:
+# text_representation:
+# extension: .py
+# format_name: percent
+# format_version: '1.3'
+# jupytext_version: 1.18.1
+# kernelspec:
+# display_name: .venv
+# language: python
+# name: python3
+# ---
+
+# %% [markdown]
+# # 👥 Data Designer Tutorial: Reproducing & Customizing Nemotron-Personas
+#
+# This notebook reproduces the [Nemotron-Personas-USA](https://huggingface.co/datasets/nvidia/Nemotron-Personas-USA) generation pipeline end to end with [🎨 NeMo Data Designer](https://github.com/NVIDIA-NeMo/DataDesigner), and then shows how to customize that pipeline to generate personas for a specific use case. A similar approach was used to build every dataset in the [Nemotron-Personas HF collection](https://huggingface.co/collections/nvidia/nemotron-personas).
+#
+# We seed the pipeline with the **extended Nemotron-Personas-USA dataset on NGC**, which is a superset of the publicly released HuggingFace version — it includes additional demographic and persona fields used internally to ground synthetic generation. From those grounded seeds, two stages of LLM structured-output columns produce the persona attributes (cultural background, skills, career goals, hobbies) and the persona descriptions across professional, financial, healthcare, sports, arts, travel, and culinary dimensions.
+#
+# > ⚠️ **Note**: To run this notebook, follow the setup instructions in the [Quick Start](https://nvidia-nemo.github.io/DataDesigner/quick-start/), make sure you have generated an API key for accessing models on [build.nvidia.com](https://build.nvidia.com), and that you've set the `NVIDIA_API_KEY` environment variable. The next section also walks through downloading the NGC-hosted Nemotron-Personas dataset.
+#
+#
+#
+#
+# See [Big Five personality traits Wikipedia article](https://en.wikipedia.org/wiki/Big_Five_personality_traits) for more context.
+#
+# In this notebook the OCEAN traits come straight from the **NGC-hosted Nemotron-Personas-USA dataset** in the next section (`with_synthetic_personas=True` exposes `person.openness`, `person.conscientiousness`, etc. as `struct`). The helper functions in Section 2 are kept ready for the `SAMPLE_FROM_SDG_PGM = True` reproduction path.
+
+# %% [markdown]
+# ## 4.2 👩🎨👨🎨 Generate Persona Attributes
+#
+# We are focusing just on the part in the diagram below and seeding persona attributes with PGM + OCEAN details:
+#
+#
+#
+#
+#
+#