import torch
from torch import Tensor
from pytorch_lightning import LightningModule
class Generator:
def __init__(self):
pass
def forward(self):
pass
class Discriminator:
def __init__(self):
pass
def forward(self):
pass
class SimpleGAN(LightningModule):
def __init__(self):
super().__init__()
self.G = Generator()
self.D = Discriminator()
# Important: This property activates manual optimization.
self.automatic_optimization = False
def sample_z(self, n) -> Tensor:
sample = self._Z.sample((n,))
return sample
def sample_G(self, n) -> Tensor:
z = self.sample_z(n)
return self.G(z)
def training_step(self, batch, batch_idx):
# Implementation follows the PyTorch tutorial:
# https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html
g_opt, d_opt = self.optimizers()
X, _ = batch
batch_size = X.shape[0]
real_label = torch.ones((batch_size, 1), device=self.device)
fake_label = torch.zeros((batch_size, 1), device=self.device)
g_X = self.sample_G(batch_size)
##########################
# Optimize Discriminator #
##########################
d_x = self.D(X)
errD_real = self.criterion(d_x, real_label)
d_z = self.D(g_X.detach())
errD_fake = self.criterion(d_z, fake_label)
errD = errD_real + errD_fake
d_opt.zero_grad()
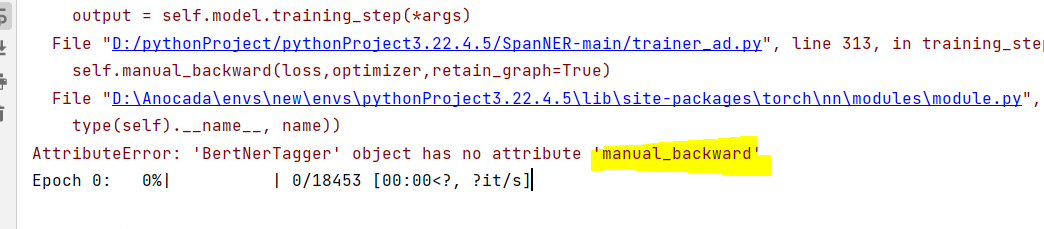
self.manual_backward(errD)
d_opt.step()
######################
# Optimize Generator #
######################
d_z = self.D(g_X)
errG = self.criterion(d_z, real_label)
g_opt.zero_grad()
self.manual_backward(errG)
g_opt.step()
self.log_dict({"g_loss": errG, "d_loss": errD}, prog_bar=True)
def configure_optimizers(self):
g_opt = torch.optim.Adam(self.G.parameters(), lr=1e-5)
d_opt = torch.optim.Adam(self.D.parameters(), lr=1e-5)
return g_opt, d_opt
batch=torch.randn(3,2)
batch_idx=torch.ones(3)
SimpleGAN().training_step(batch,batch_idx)