Comparisson between various OpenMP policies for multi-thread loop distribution based on the Gaussian Blur algorithm using box blur approximation. Algorithm is being run for a .pgm picture.
Gaussian blur is an algorithm that blurs the image using the gaussian function:
$ g(x, y) = e^\frac{x^2+y^2}{2\sigma^2} $. Result of the function are used to create a convolution kernel of size
Applying gaussian blur directly can proove to be rather time-consuming. What we need is some form of approximation of the blur. This example uses the box blur aaproximation technique. Lets define the horizontal and total blur:
Where
This makes the time complexity of the algoritm to be O(nr).
One of the most popular ways to use OpenMP is to parallelize loops. This can be achieve using different verious scheduling options
- static. This means loop iterations will ber equally distributed between threads
- static,
$x$ . This means that each thread will get an$x$ amount of iterations - dynamic,
$x$ . This means that each thread get$x$ iterations and "asks" for new iterations after completing previously assigned ones.
I calculated the run-time of the programm using various policies, carious thread pool size and various chunk_size(
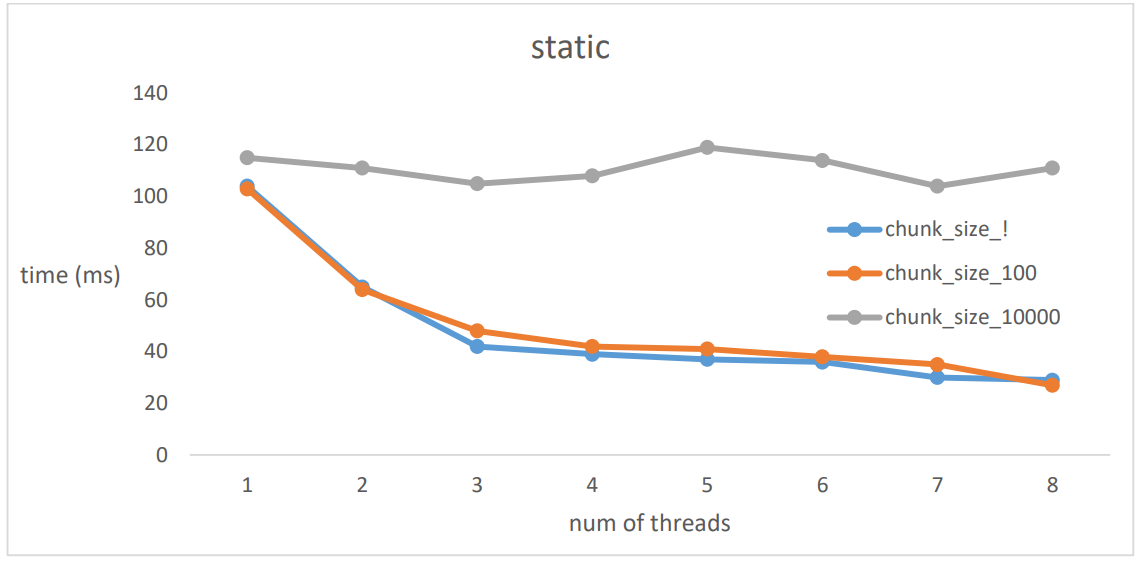
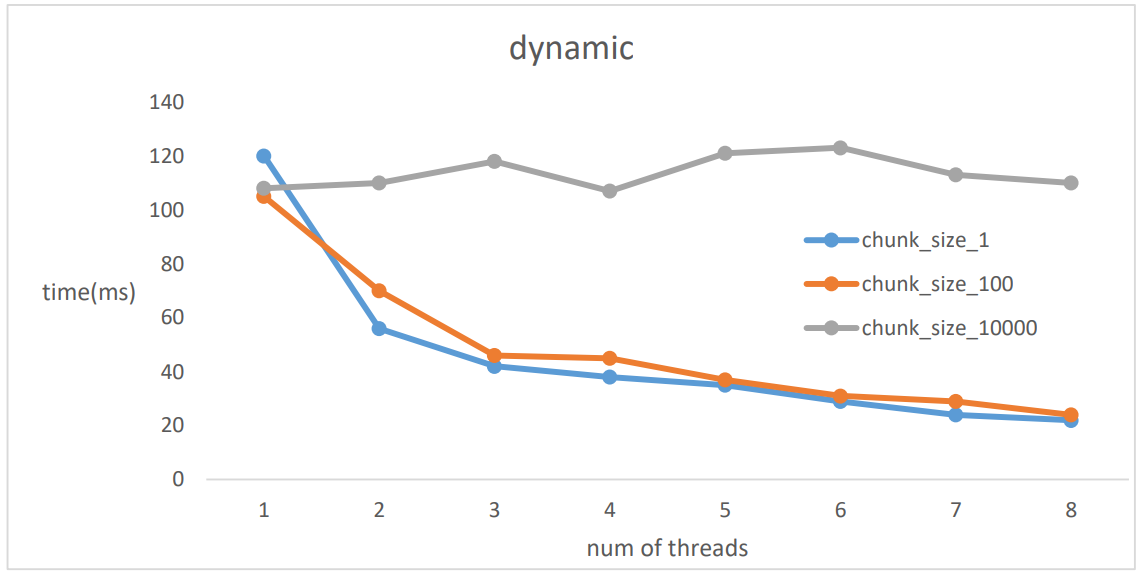
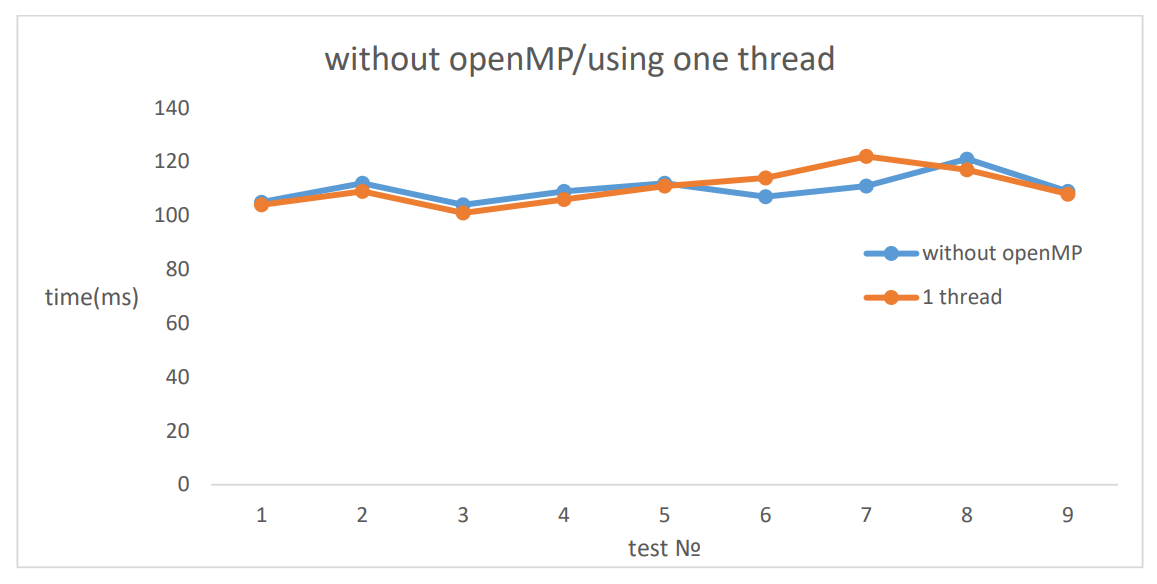
To get thus results, I used the average of 5 runs. The results show that maxing out the thread pool size with out passing over the harware limit of supported threads yields the best results. Dynamic and static scheduling show almost equal results on this algorithm. I think the reason behind this is that I still use a fixed-size thread pool for each run with out any other processes in the backgtound. Maxing out the chunk_size seems to limit the amount of threads used making the programm slower.