This document provides detailed analysis of the performance variations observed across three benchmark datasets in our fact verification evaluation: FactBench, YAGO, and DBpedia.
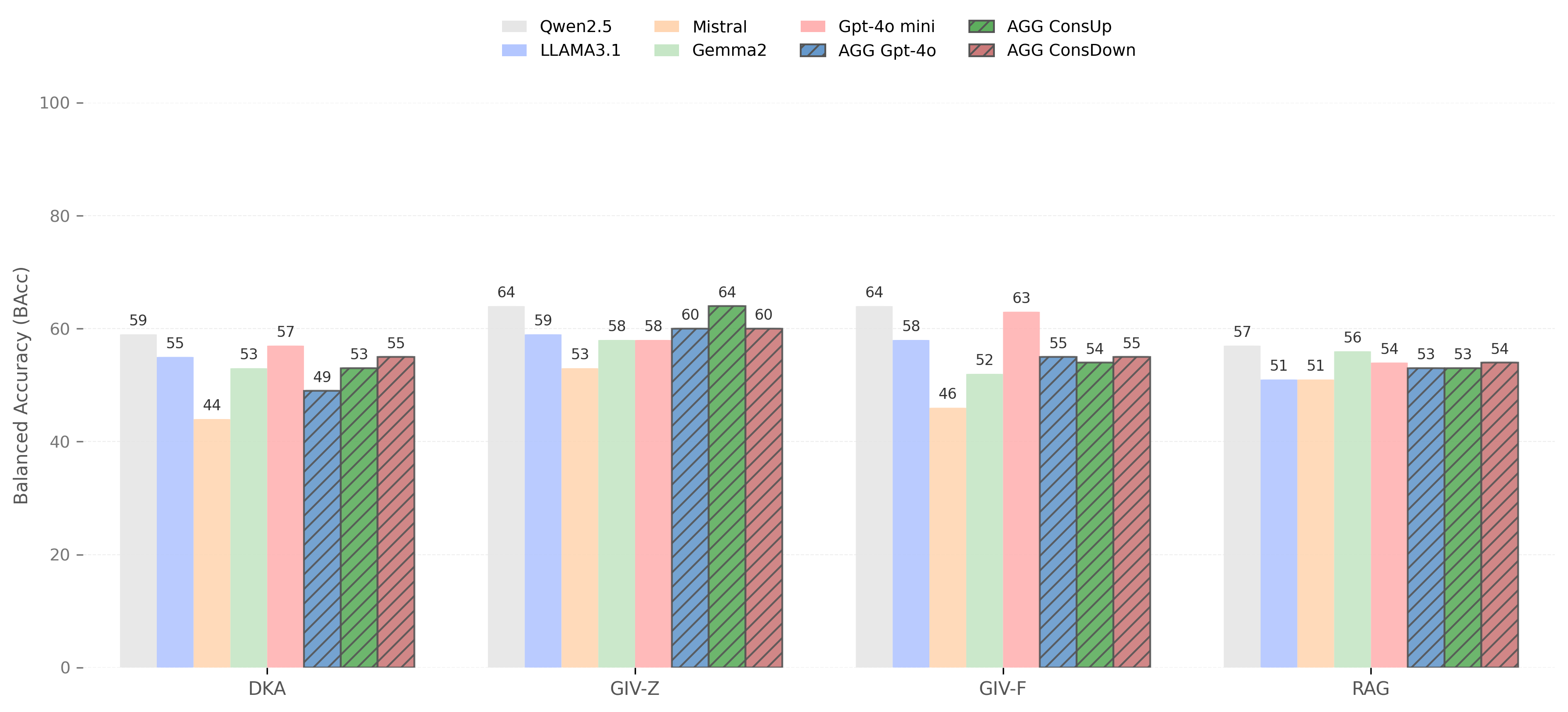
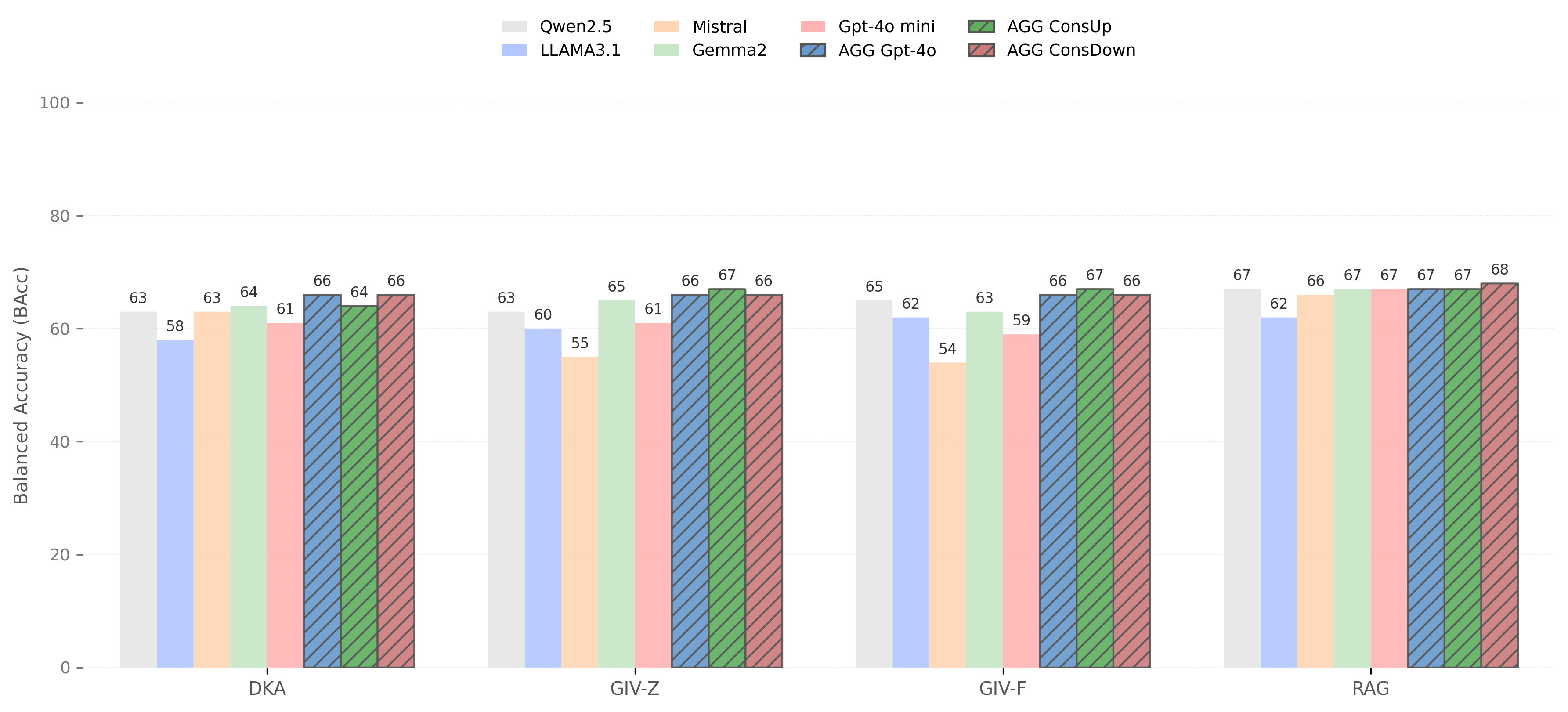
The performance plots illustrate how four different methodologies (DKA, GIV-Z, GIV-F, and RAG) perform across multiple language models (Qwen2.5, Llama3.1, Mistral, Gemma2, and GPT-4o mini) on three distinct fact verification datasets. Each dataset presents unique challenges that significantly impact verification accuracy.
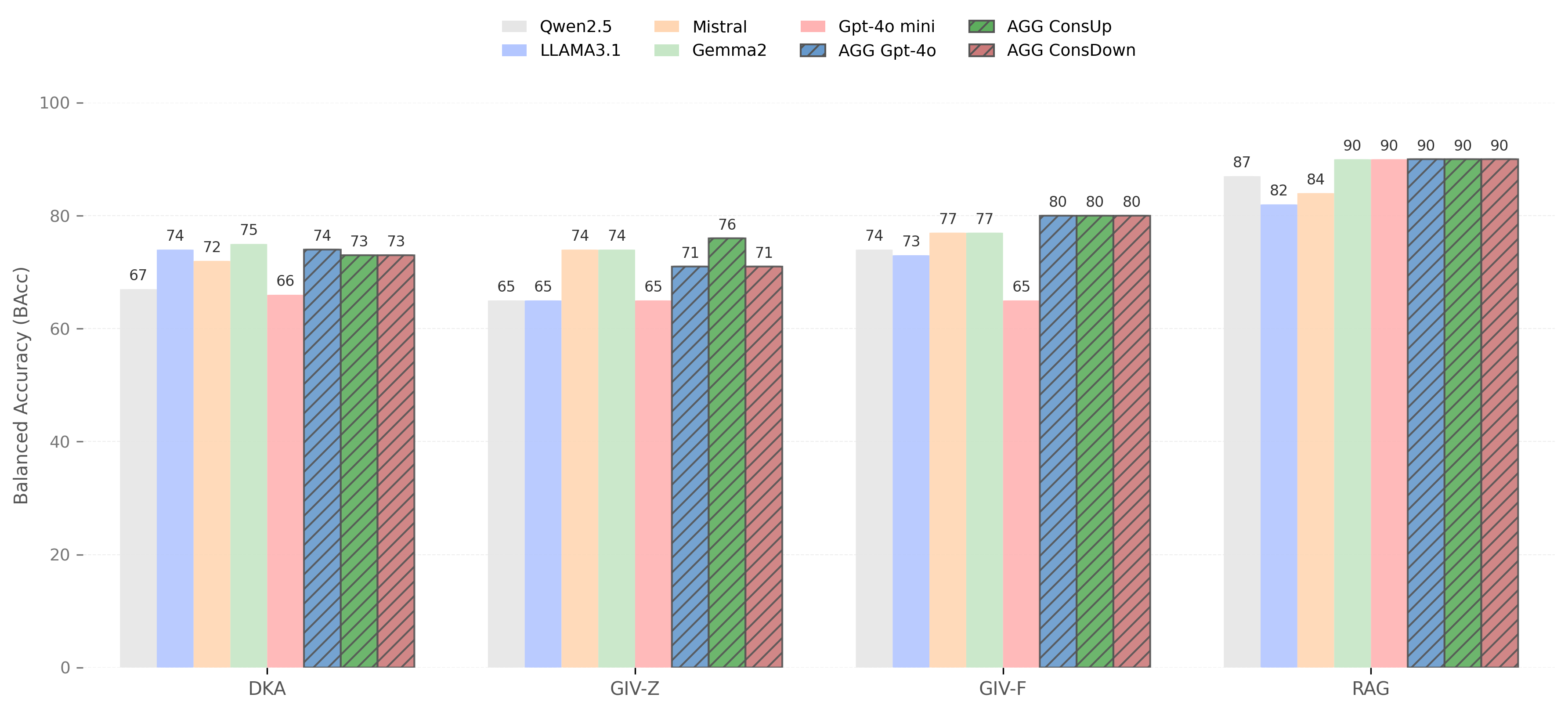
- Best Performance: FactBench (90% BAcc)
- Most Challenging: YAGO (54-57% BAcc)
- Key Insight: External knowledge retrieval most effective with balanced datasets
- Shows consistent moderate performance across datasets
- Less sensitive to class imbalance compared to RAG
- Provides stable baseline performance
- Performance varies significantly by model and dataset
- Particularly effective on FactBench with certain models (Gemma2, Mistral)
- Generally lower performance across all datasets
- Struggles particularly with YAGO's class imbalance
- Most consistent performance on FactBench
-
Dataset Characteristics Drive Performance: The fundamental properties of each dataset (class balance, error types, predicate diversity) significantly impact verification accuracy more than model choice alone.
-
RAG Benefits from Balance: Retrieval-augmented approaches show dramatic improvements on balanced datasets but offer minimal gains on highly imbalanced ones.
-
Model Consistency Varies: Different models show varying levels of robustness across datasets, with some performing consistently (GPT-4o mini) while others show high variance (Qwen2.5).